第一,我们找到豆瓣官网
,网址如下:https://movie.douban.com/
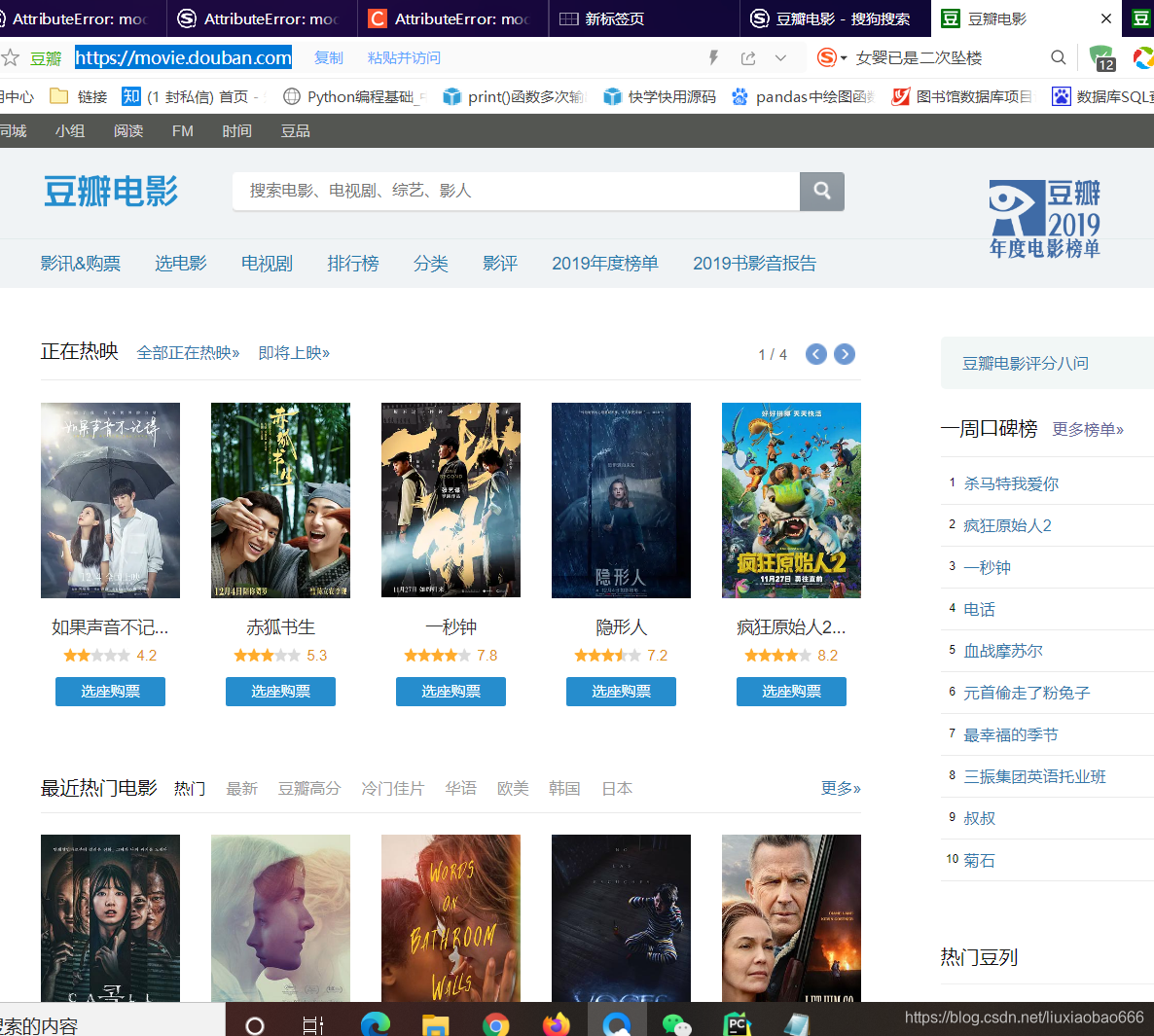
第二,我们分析页面数据
,打开排行榜,打开抓包工具(F12),并找到NetWord
,接着定位到XHR,
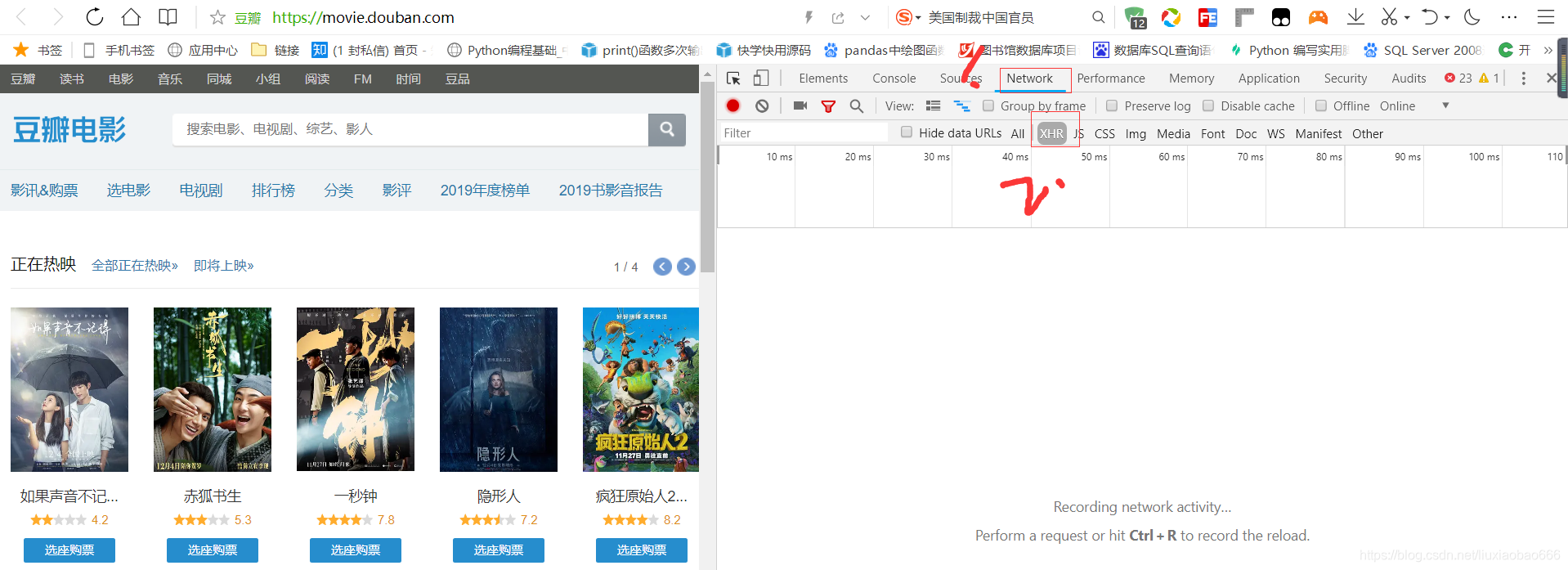
第三,既然是动态获取,那就肯定会有一定的规律
,我们滑动首页,就可以发现,每次滑到底部,就会有新的一批数据出现,右边的XHR就会多一行东西出来,这里我滑动到页面底部两次,就出现了两个不同的连接,继续滑动就会继续出现,
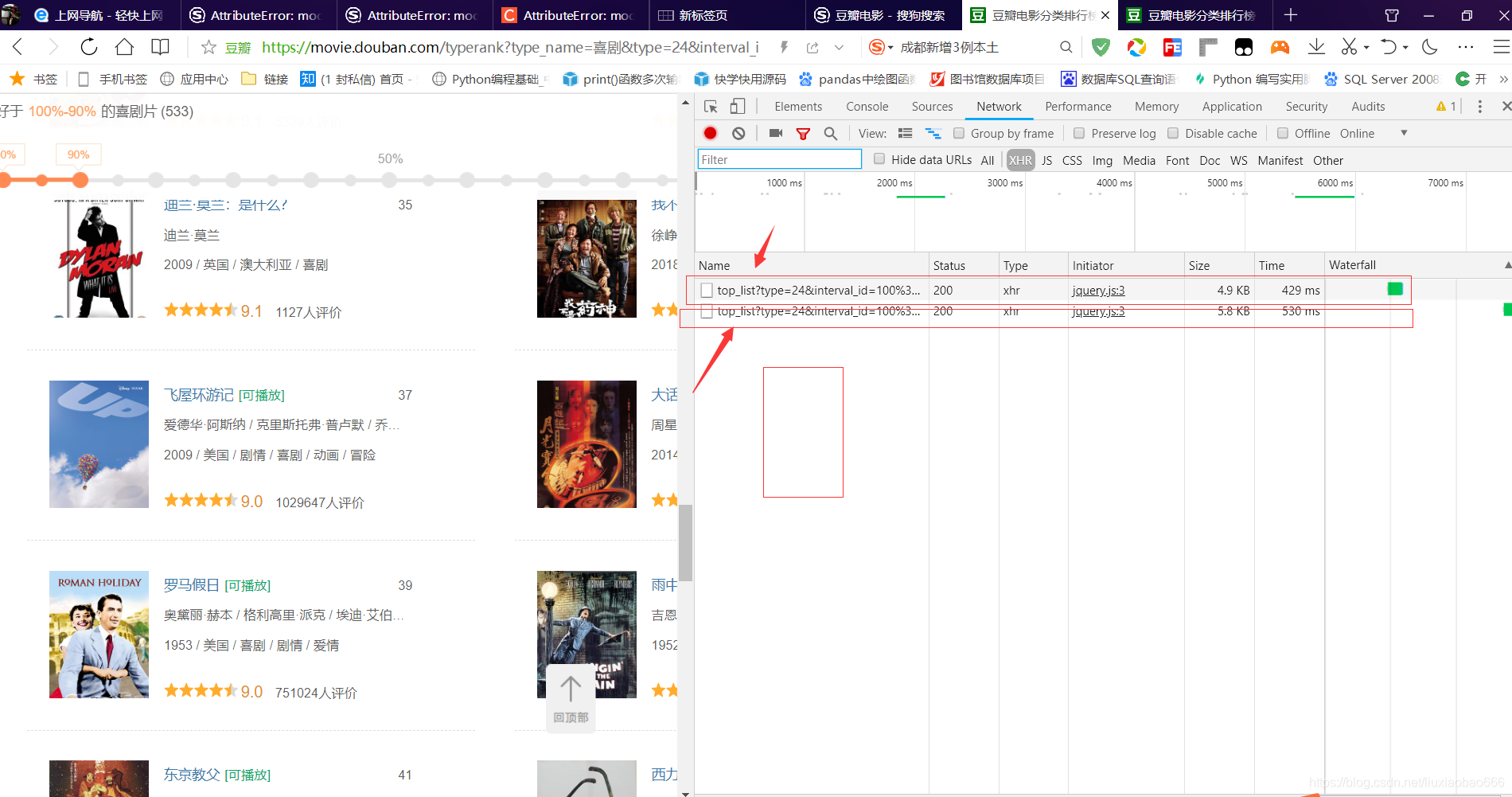
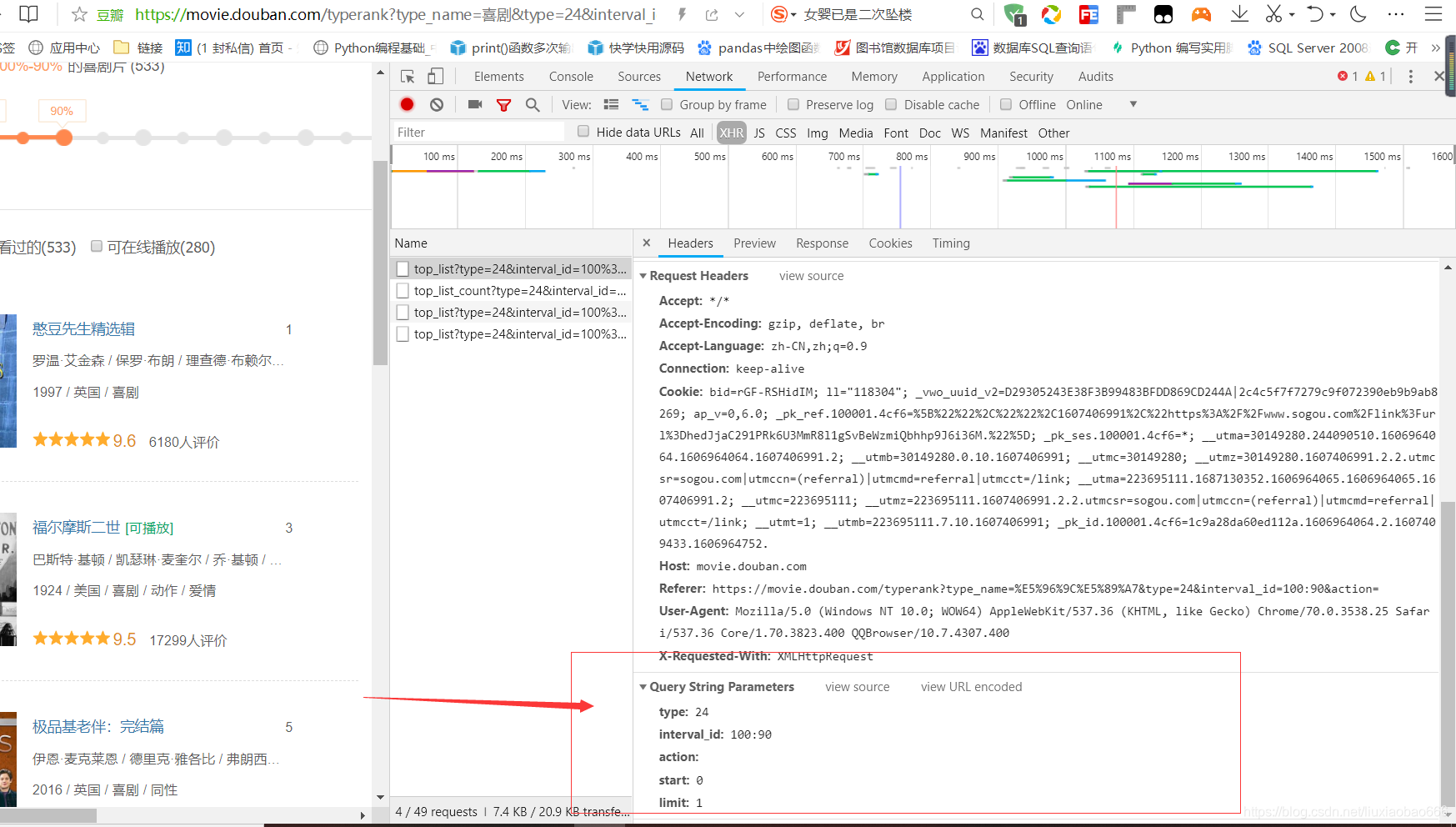
第四,我们打开右边出现的连接
,分析它的结构,这里我们先分析这四个,首先是URL,这就是第一个页面的电影的连接,我们要获取电影,就必须经过他来得到相应的电影名称,其次就是,整个网页采用GET方式来请求数据,就意味着我们写代码要用到get,,接着我们看网页时一个Json的格式,自然也要用json来解析,如下:
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()
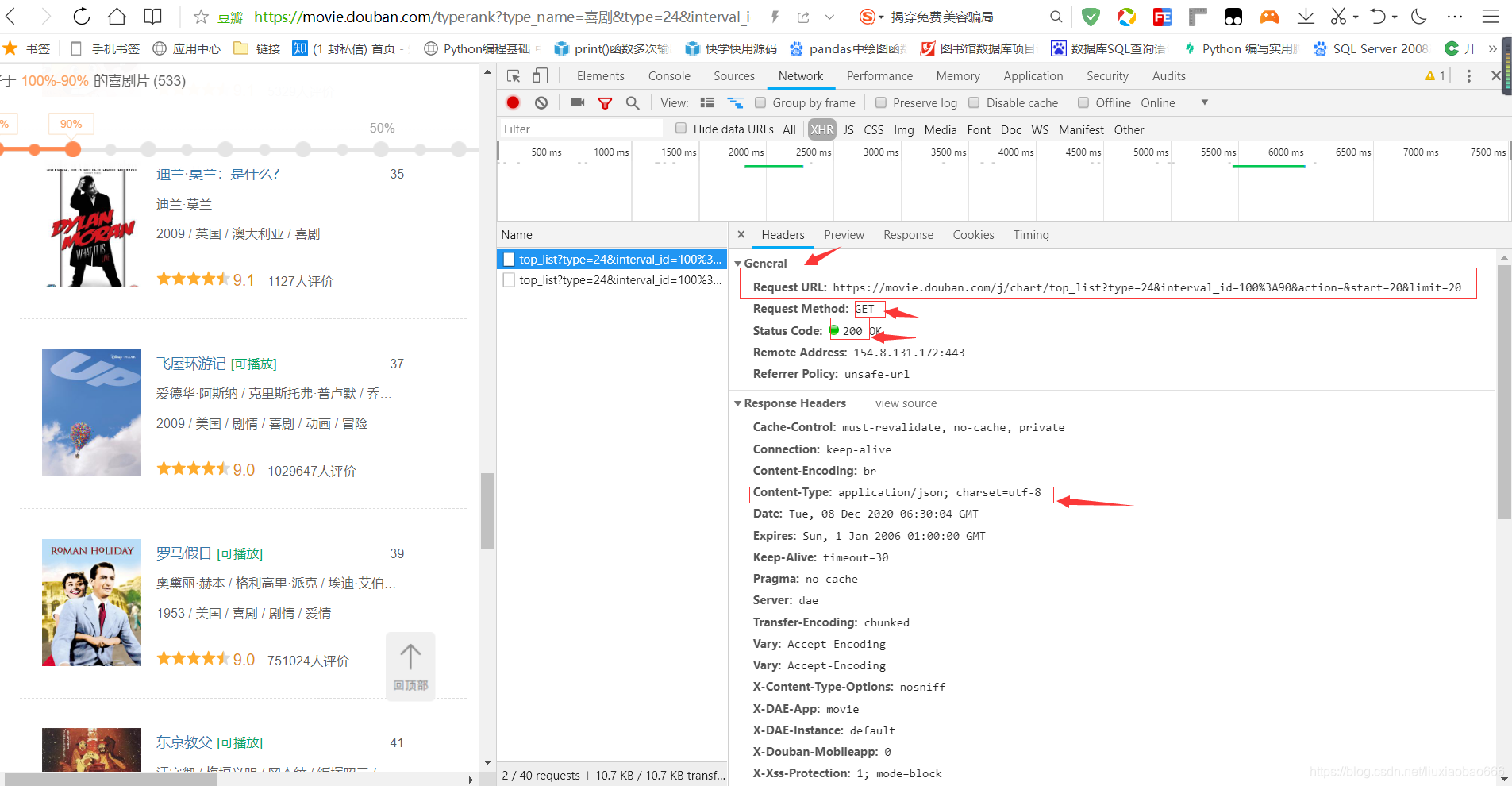
第五,我们看到最底下的param,这个就是链接里面的部分参数
,其实就是把它跟主链接拼接起来,具体,链接为:Request URL: https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20
这个是一个页面的连接,我们要的不只是一个页面,所以这里就采用拼接的方式来得到其他页面的内容:
`import requests
from bs4 import BeautifulSoup
import json
if __name__=="__main__":
url="https://movie.douban.com/j/chart/top_list"
param={
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从第几个电影爬取
'limit': '20',
}`
第七,我们开始编写代码,以下是全部的代码
import requests
from bs4 import BeautifulSoup
import json
if __name__=="__main__":
url="https://movie.douban.com/j/chart/top_list"
param={
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从第几个电影爬取
'limit': '20',
}
headers={
'User-Agent':'Mozilla/5.0(Windows NT 10.0;WOW64)AppleWebKit/537.36(KHTML, like Gecko)Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400'
}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()
fp=open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print("over!!!")
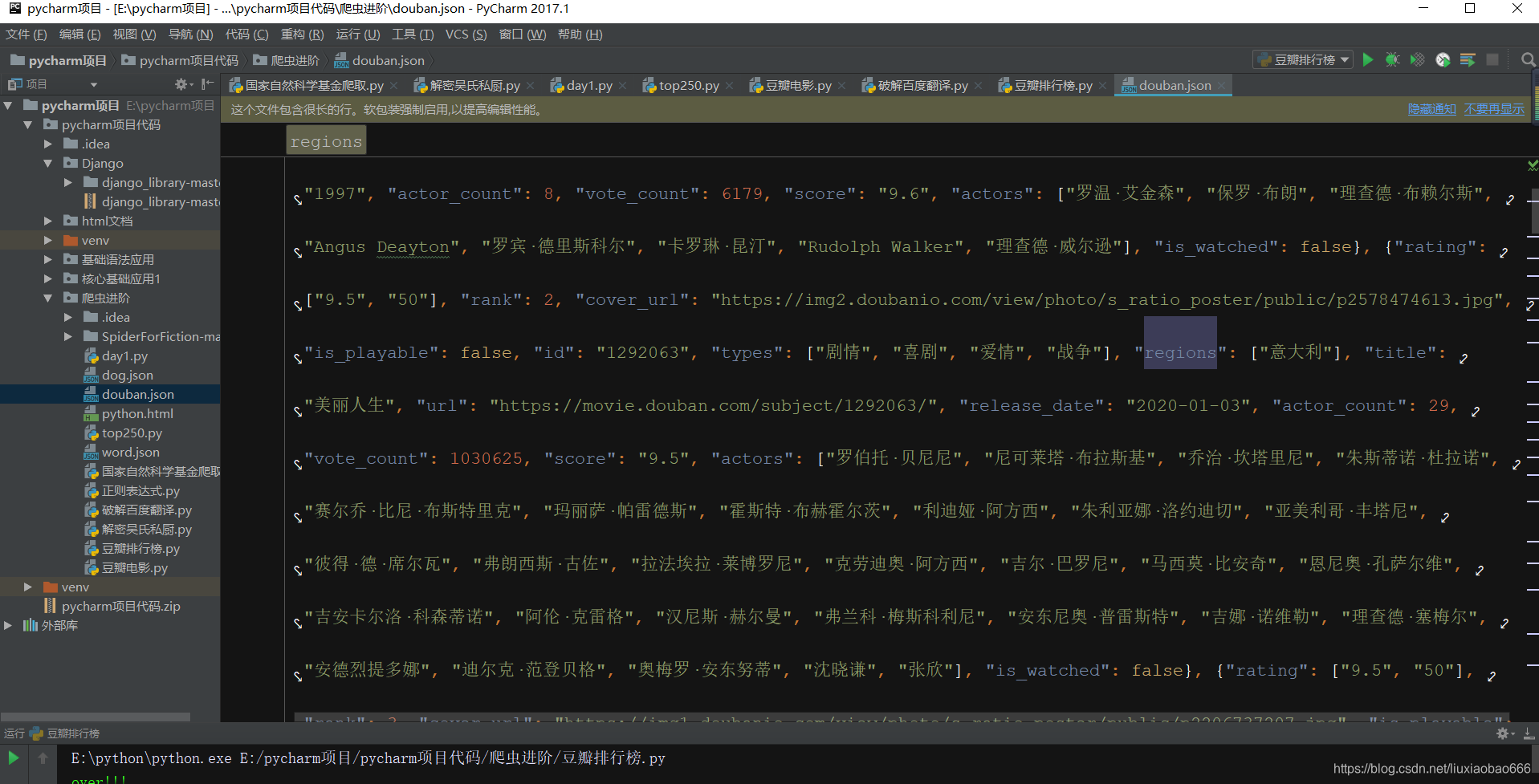
运行结果如下:
感谢支持,喜欢就点个赞吧!!!