大数据相关知识
以下为相关的资料整理
MR (key,value)排序
第一种方法是,Reducer 将给定 key 的所有值都缓存起来,然后对它们在 Reduce 内部做一个内排序。但是,由于 Reducer 需要缓存给定 key 的所有值,数据量多的话可能会导致内存不足。
第二种方法是,将值的一部分或整个值键入到原始 key 中,重新组合成一个新的 key 。这两种方法各有各的特点,第一种方法编写简单,但是需要较小的并发度,数据量大的话可能会造成内存耗尽卡死的状态。 第二种方法则是将排序的任务交给 MapReduce 框架进行 shuffle,更符合 Hadoop/Reduce 的设计思想。
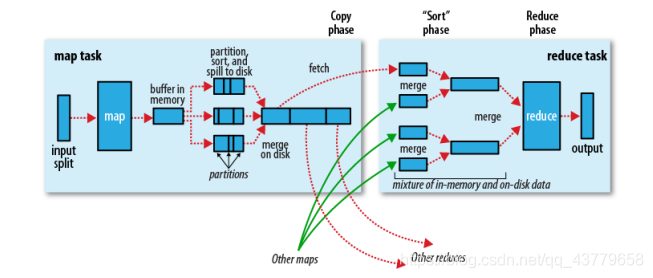
Map端
<1>在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V 2>的输出,这些输出显存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
<2>写磁盘前,要partition,sort。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
<3>最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入来自其他的Map输出。
Reduce端

<1>Reducer通过Http方式得到输出文件的分区。
<2>TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
<3>排序阶段合并map输出。然后走Reduce阶段。
全排序 — 内存不够
最简单的方法就是使用一个partition,因为一个partition对应一个reduce的task,然而reduce的输入本来就是对key有序的,所以很自然地就产生了一个全排序文件。但是这种方法在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了mapreduce所提供的并行架构的优势。
分多个partition,首先创建一系列排好序的文件;其次,串联这些文件(类似归并排序);最后得到一个全局有序的文件
-
按区间排序
比如有1000个1-10000的数据,跑10个ruduce任务,如果进行partition的时候,能够将在1-1000中数据的分配到第一个reduce中,1001-2000的数据分配到第二个reduce中,以此类推。==即第n个reduce所分配到的数据全部大于第n-1个reduce中的数据。==这样,每个reduce出来之后都是有序的了,我们只要concat所有的输出文件,变成一个大的文件,就都是有序的了。
-
而对于区间内部
MapReduce的天然特性 — 在数据达到reducer之前,map reduce框架已经对这些数据按key排序了。
-
对于数据分配不同区间
就是在定义每个partition的边界的时候,可能会导致每个partition上分配到的记录数相差很大,这样数据最多的partition就会拖慢整个系统。
我们期望的是每个partition上分配的数据量基本相同,hadoop提供了采样器帮我们预估整个边界,以使数据的分配尽量平均。
-
面对大量的数据,为了partition均匀,需要先取样:
1.根据所有数据键值对的数目、所有数据split的数目以及设定的每个split取样数目进行取样,比如原有100亿条数据,10个split,对每个split取样1W条,则总共10W个样本;
2.将10W个样本进行全排序,根据reducer的数量n,取出间隔平均的n-1个样本;
3.将这n-1个样本写入二进制文件(默认是 _partition.lst,是一个SequenceFile);
4.将上述二进制文件写入DistributedCache(所有mapper和reducer共享)。
接下来PartitionerClass来读取这个共享的二进制文件,根据这n-1个key生成一个类似于B-树的Tire树,可以加快查找(以空间换取时间),将所有的map输出根据这n-1个不同范围内的key输出到不同partition,这样可以保证第i个partition输出的键值对都比第i+1个partition的键值对的key小。然后每个partition进行一下局部排序即可,从而达到所有的key全局有序。
-
在map阶段,根据预先定义的patition规则进行分区,map首先将输出写到缓存中,当缓存内容达到阈值时,将结果spill到硬盘,每一次spill都会在硬盘产生一个spill文件,因此一个map task可能会产生多个spill文件。
接下来进入shuffle阶段,当map写出最后一个输出,需要在map端进行一次merge操作,按照partition和partition内的key进行合并和排序,此时每个partition内按照key值整体有序。
然后开始第二次merge,这次是在reduce端,在此期间数据在内存和磁盘上都有,其实这个阶段的merge并不是严格意义上的排序,只是将多个整体有序的文件merge成一个大的文件,最终完成排序工作。
数据库join
Join 分为:
- 内连接(inner join)
- 外连接(outer join)
其中外连接分为:
- 左外连接(left outer join)
- 右外连接(right outer join)
- 全外连接(full outer join)
hadoop join
Map Join
- 描述场景:Map Join 适用于有一份数据较小的连接情况。
- 做法:直接将较小的数据加载到内存中,按照连接的关键字建立索引,大份数据作为Map Task的输入数据对 map()方法的每次输入都去内存当中直接去匹配连接。然后把连接结果按 key 输出,这种方法要使用 hadoop中的 Distributed Cache 把小份数据分布到各个计算节点,每个 map task 执行任务的节点都需要加载该数据到内存,并且按连接关键字建立索引。
- Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多 份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
Reduce Join
-
描述
在map阶段, 把关键字作为key输出,并在value中标记出数据是来自data1还是data2。因为在shuffle阶段已经自然按key分组,reduce阶段,判断每一个value是来自data1还是data2,在内部分成2组,做集合的笛卡尔积。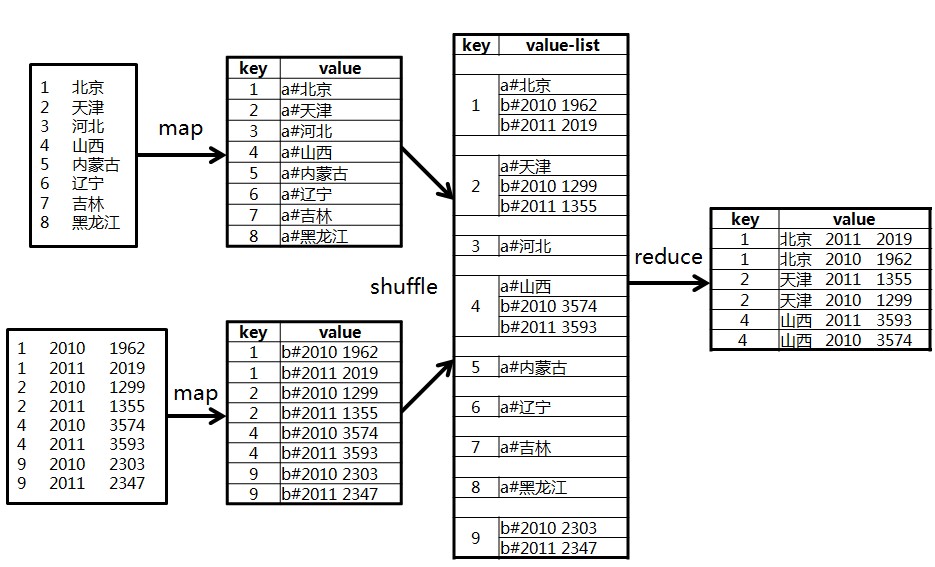
-
这种方法有2个问题:
- map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
- reduce端对2个集合做乘积计算,很耗内存,容易导致OOM。.
Semi Join
-
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
-
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到
内存中。在map阶段,使用Distributed Cache将File3复制到各个TaskTracker上,然后将File2中不在File3中的 key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
Spark join
SparkSQL支持三种Join算法-shuffle hash join、broadcast hash join以及sort merge join。其中前两者归根到底都属于hash join
hash join算法
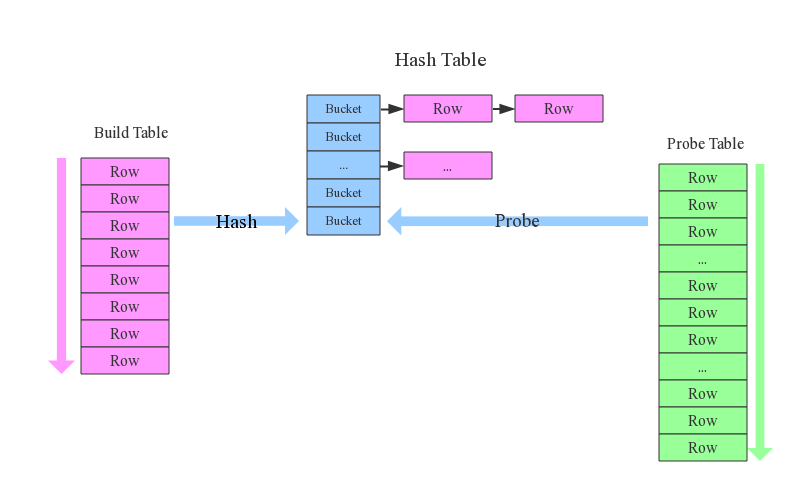
整个过程会经历三步:
- 确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table。
- 构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存。
- 探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。
改进:
-
broadcast hash join:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景。
-
shuffler hash join:一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化
Broadcast Hash Join
如下图所示,broadcast hash join可以分为两步:
-
broadcast阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于bittorrete的p2p思路;
-
hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探;

Shuffle Hash Join
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
-
shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle
-
hash join阶段:每个分区节点上的数据单独执行单机hash join算法。
Sort-Merge Join
-
shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理
-
sort阶段:对单个分区节点的两表数据,分别进行排序
-
merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出
仔细分析的话会发现,sort-merge join的代价并不比shuffle hash join小,反而是多了很多。那为什么SparkSQL还会在两张大表的场景下选择使用sort-merge join算法呢?这和Spark的shuffle实现有关,目前spark的shuffle实现都适用sort-based shuffle算法,因此在经过shuffle之后partition数据都是按照key排序的。因此理论上可以认为数据经过shuffle之后是不需要sort的,可以直接merge。
value排序
- map阶段不做改变,在reduce阶段对map的输出进行缓存,重写clean up方法,在其中对缓存的数据进行排序输出。
缺点:如果数据量过大,将消耗大量的内存- 其中setup方法和cleanup方法默认是不做任何操作,且它们只被执行一次。但是setup方法一般会在map函数之前执行一些准备工作,如作业的一些配置信息等;cleanup方法则是在map方法运行完之后最后执行 的,该方法是完成一些结尾清理的工作,如:资源释放等。如果需要做一些配置和清理的工作,需要在Mapper/Reducer的子类中进行重写来实现相应的功能。map方法会在对应的子类中重新实现,就是我们自定义的map方法。该方法在一个while循环里面,表明该方法是执行很多次的。run方法就是每个maptask调用的方法。
- 进行两个Mapreduce操作
将第一个次Mapreduce的输出value作为第二次map的key,在第二次reduce再还原成原来的key value形式