前言
在前面的几章内, 我们主要讲解了如何进行简单的MR操作, 以及如何开发自定义组件.(Combiner/InputFormat等).
在本章中, 我们主要讲解MR中的一个非常经典的问题: 如何实现Join操作?
本文相关代码, 可在我的Github项目 https://github.com/SeanYanxml/bigdata/ 目录下可以找到. PS: (如果觉得项目不错, 可以给我一个Star.)
知识准备
Mysql Join操作
- Table A 订单编号表
| 订单编号 | 手机种类编号 | 时间 |
|---|---|---|
| 1 | 1 | 2018-09-09 |
| 2 | 2 | 2018-09-10 |
| 3 | 1 | 2018-09-11 |
- Table B 手机类别表
| 手机种类编号 | 手机类型名称 |
|---|---|
| 1 | XiaoMi |
| 2 | HuaWei |
左外链接的SQL应该这样写
select orderId,phoneTypeNumber,phoneTypeName,orderTime from TableA a left join on TableB b on a.phoneTypeNumber = b.phoneTypeNumber;
业务场景
我们今天就要使用Map/Reduce来完成上面的业务操作问题. 使用左外链接来获取全表数据.
使用数据: 主要包括 OrderData 与 PhoneData.
# orderData
1 1
2 2
3 1
4 1
5 3
6 1
# PhoneData
1 xiaomi
2 huawei
3 iphone
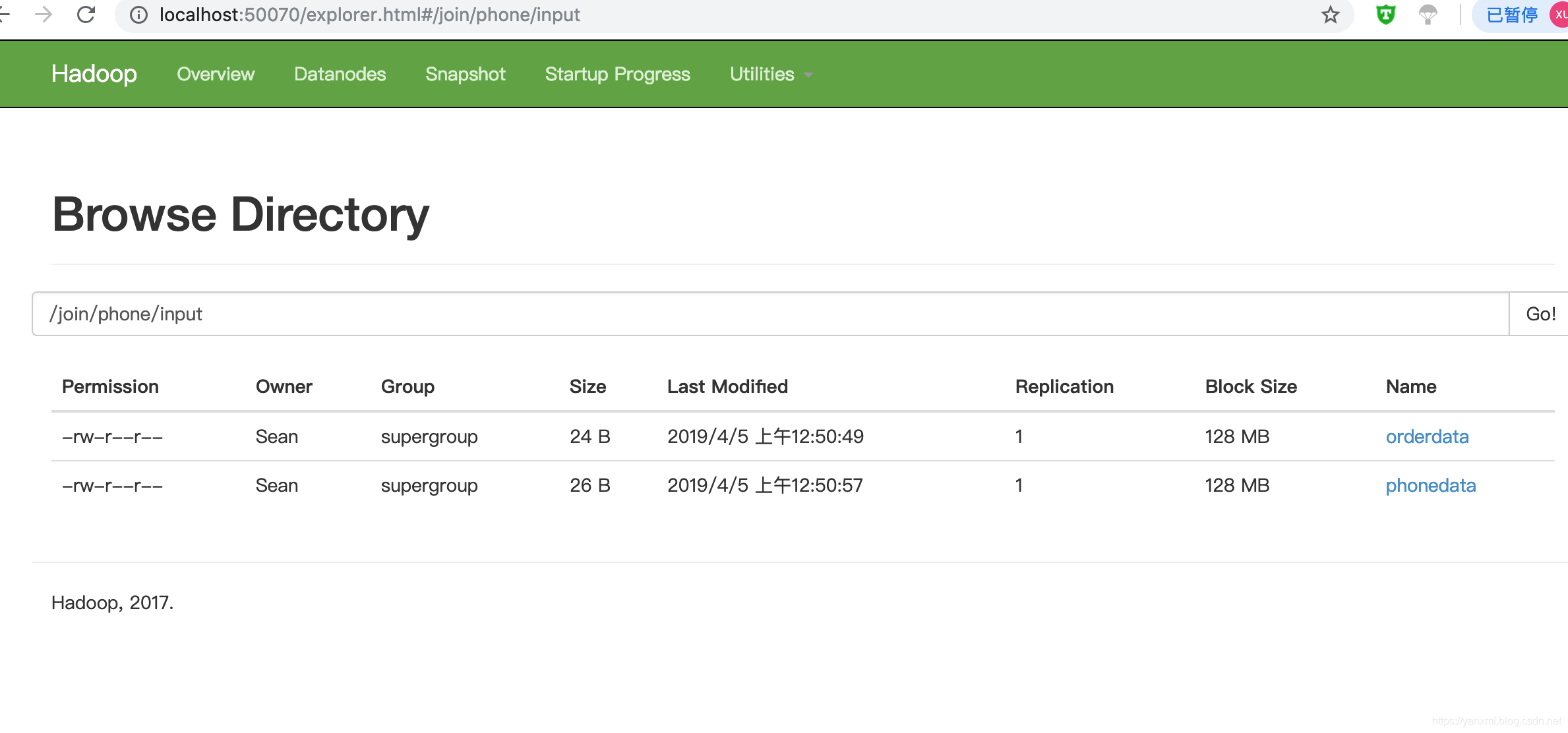
在写下方的程序之前, 同理. 我们将其放入Hadoop的HDFS上:
hadoop fs -mkdir -p /join/phone/input
hadoop fs -put orderdata /join/phone/input/
hadoop fs -put phonedata /join/phone/input/
设计&编码
在实现Join操作的时候,常见的场景是MapJoin与ReduceJoin. 两者的使用场景各不相同. 下面我们讲解下两种做法的使用场景、具体实现以及优劣点.
ReduceJoin
一开始, 最容易想到的就是ReduceJoin. 将类别对象&一组对象放入一个Mapper内进行操作. 这个地方使用的技巧是设置相同的Key, 这样一个类别的一组对象就会以Iterator的形式传入一个集合内进行处理了.
我们定义三个类:
- OrderInfoBean 订单类
- PhoneTypeBean 手机类别类
- HadoopTransferBean 转换类
其中HadoopTransferBean是用于将订单类与类别类进行封装, 用于传输所用. 本来想使用Writeable接口进行实现的, 但是Hadoop貌似不支持这样做.
几个类别的基本编码如下所示:
// OrderInfoBean.java
/**
* 存放处理后的join结果Bean.
*
* */
public class OrderInfoBean implements Writable{
private int orderId;
private int phonetype;
private String phoneName;
public OrderInfoBean(){}
public OrderInfoBean(int orderId, int phonetype, String phoneName){
this.orderId = orderId;
this.phonetype = phonetype;
this.phoneName = phoneName;
}
public int getOrderId() {
return orderId;
}
public void setOrderId(int orderId) {
this.orderId = orderId;
}
public int getPhonetype() {
return phonetype;
}
public void setPhonetype(int phonetype) {
this.phonetype = phonetype;
}
public String getPhoneName() {
return phoneName;
}
public void setPhoneName(String phoneName) {
this.phoneName = phoneName;
}
// write的顺序要与read的顺序对应.
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(orderId);
out.writeInt(phonetype);
out.writeUTF(phoneName);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.orderId = in.readInt();
this.phonetype = in.readInt();
this.phoneName = in.readUTF();
}
@Override
public String toString() {
//123-1-xiaomi
return orderId+" "+phonetype+" "+phoneName;
}
}
// PhoneTypeBean.java
public class PhoneTypeBean implements Writable{
private int phonetype;
private String phoneName;
public PhoneTypeBean(){}
public PhoneTypeBean(int phonetype, String phoneName){
this.phonetype = phonetype;
this.phoneName = phoneName;
}
public int getPhonetype() {
return phonetype;
}
public void setPhonetype(int phonetype) {
this.phonetype = phonetype;
}
public String getPhoneName() {
return phoneName;
}
public void setPhoneName(String phoneName) {
this.phoneName = phoneName;
}
// write的顺序要与read的顺序对应.
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(phonetype);
out.writeUTF(phoneName);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.phonetype = in.readInt();
this.phoneName = in.readUTF();
}
@Override
public String toString() {
//123-1-xiaomi
return phonetype+" "+phoneName;
}
}
// 封装类
public class HadoopTransferBean implements Writable{
private OrderInfoBean infoBean;
private PhoneTypeBean typeBean;
public HadoopTransferBean(){}
public HadoopTransferBean(OrderInfoBean infoBean){
this.infoBean = infoBean;
}
public HadoopTransferBean(PhoneTypeBean tyepeBean){
this.typeBean = tyepeBean;
}
public OrderInfoBean getInfoBean() {
return infoBean;
}
public void setInfoBean(OrderInfoBean infoBean) {
this.infoBean = infoBean;
}
public PhoneTypeBean getTypeBean() {
return typeBean;
}
public void setTypeBean(PhoneTypeBean typeBean) {
this.typeBean = typeBean;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(JSON.toJSONString(infoBean));
out.writeUTF(JSON.toJSONString(typeBean));
// out.writeUTF();
// out.write(ByteUtils.toByteArray(infoBean));
// out.write(ByteUtils.toByteArray(typeBean));
}
@Override
public void readFields(DataInput in) throws IOException {
this.infoBean = JSON.parseObject(in.readUTF(), OrderInfoBean.class);
this.typeBean = JSON.parseObject(in.readUTF(), PhoneTypeBean.class);
// this.infoBean = ByteUtils.toObject(in.readByte());
// this.infoBean = ByteUtils.toObject(in.readByte());
}
}
好了, 有了上面三个封装类之后, 我们可以编写具体的逻辑.
- Mapper端: 我们将带处理文件放入一个统一的目录, 通过文件的头部名称辨别数据类型;
- Mapper端: 将需要外链接的类作为key放入返回的context
key中.
基本编码如所示:
static class PhoneOrderInfoMapper extends Mapper<LongWritable, Text, IntWritable, HadoopTransferBean>{
@Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, IntWritable, HadoopTransferBean>.Context context)
throws IOException, InterruptedException {
HadoopTransferBean bean = null;
int outkey = 0;
String line = value.toString();
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
// 通过文件名称判断是哪种类型的数据
if(name.startsWith("order")){
String []fields = line.split(" ");
// orderid - phonetype
// 注意这边是将fields[1]作为key输出出去 目的在于能将其与类型一同分到一个结点上去.
outkey = Integer.parseInt(fields[1]);
OrderInfoBean orderBean = new OrderInfoBean(Integer.parseInt(fields[0]),Integer.parseInt(fields[1]),null);
bean = new HadoopTransferBean(orderBean);
}else{
// 手机种类类型的数据处理.
// phonetype - phoneName
String []fields = line.split(" ");
outkey = Integer.parseInt(fields[0]);
PhoneTypeBean phoneTypeBean = new PhoneTypeBean(Integer.parseInt(fields[0]), fields[1]);
bean = new HadoopTransferBean(phoneTypeBean);
}
context.write(new IntWritable(outkey), bean);
}
}
上方需要特别注意的是:outkey = Integer.parseInt(fields[1]);和outkey = Integer.parseInt(fields[0]);. 通过指定相同的手机类型编号, 将其分配到一起.(基本的数据类型见业务场景部分.)
- Reducer端: 取出封装为
HadoopTransferBean类型数据, 并辨别其到底是订单表数据还是手机类别表数据. (注: 订单表数据应当是多个, 手机类别表数据应当为1个. 这是业务的逻辑决定的.) - Reducer端: 将数据拆分后, 重新组装丰富
订单表内的手机类别名称字段.随后,将其写入输出.
其相关的编码如下所示:
static class PhoneOrderInfoReducer extends Reducer<IntWritable, HadoopTransferBean, OrderInfoBean, NullWritable>{
@Override
// 产品唯一, 订单
protected void reduce(IntWritable key, Iterable<HadoopTransferBean> values,Reducer<IntWritable, HadoopTransferBean, OrderInfoBean, NullWritable>.Context context)throws IOException, InterruptedException {
OrderInfoBean resultBean = new OrderInfoBean();
PhoneTypeBean typeBean = new PhoneTypeBean();
List<OrderInfoBean> list = new ArrayList<>();
// 疑问? 为什么另一种的订单类型为空?
for(HadoopTransferBean bean:values){
// 传入的数据类型为OrderInfoBean类型的
if(bean.getInfoBean() != null){
OrderInfoBean orderBean = new OrderInfoBean();
try {
BeanUtils.copyProperties(orderBean, bean.getInfoBean());
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
list.add(orderBean);
}else if(bean.getTypeBean() != null){
try {
BeanUtils.copyProperties(typeBean, bean.getTypeBean());
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
// 拼接两类数据
for(OrderInfoBean orderBean:list){
orderBean.setPhoneName(typeBean.getPhoneName());
context.write(orderBean, NullWritable.get());
}
}
}
- Driver类的编写(指定并生成Job)
public class PhoneOrderInfoDriver {
public static void main(String []args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name", "yarn");
conf.set("mapreduce.framework.name", "local");
conf.set("yarn.resourcemanager.hostname", "localhost");
conf.set("fs.defaultFS", "hdfs://localhost:9000/");
Job job = Job.getInstance(conf);
// job.setJar("/");
// job.setJar("/Users/Sean/Documents/Gitrep/bigdata/hadoop/target/hadoop-0.0.1-SNAPSHOT.jar");
// 指定本程序jar包所在地址
job.setJarByClass(PhoneOrderInfoDriver.class);
//指定本业务job需要使用的mapper业务类
job.setMapperClass(PhoneOrderInfoMapper.class);
job.setReducerClass(PhoneOrderInfoReducer.class);
// 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(HadoopTransferBean.class);
// 指定最终输出数据的kv类型
job.setOutputKeyClass(OrderInfoBean.class);
job.setOutputKeyClass(NullWritable.class);
// 设置匹配器
// job.setPartitionerClass(ProvincePartitioner.class);
// job.setInputFormatClass(cls);
// 当数目小于分片数目时候 会报错. 多余时,则有的分片内为空.
// job.setNumReduceTasks(5);
// // 指定job的输入文件所在目录
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// // 指定job的输出结果
// FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定job的输入文件所在目录
FileInputFormat.setInputPaths(job, new Path("/join/phone/input"));
// 指定job的输出结果
FileOutputFormat.setOutputPath(job, new Path("/join/phone/output"));
Path outPath = new Path("/join/phone/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
// 将job中配置的相关参数, 以及job所用的java类所在的jar包,提交给yarn执行
// job.submit();
//
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
运行结果(注意这里的输出,是根据你写入类的toString()方法决定的,并且可以自定义OutputFormat类.这在前面的章节内我们已经说过了.):
localhost:Desktop Sean$ hadoop fs -cat /join/phone/output/part-m-00001
Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8
19/04/05 16:48:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 1 xiaomi
2 2 huawei
3 1 xiaomi
4 1 xiaomi
5 3 iphone
6 1 xiaomi

MapJoin
在上文, 我们注意讲述了如何通过ReduceJoin进行完成传统的Join操作. 但是这样会导致一个问题. 那就是,数据资源分配不均匀的问题.
在下方的图片中, 有3个MapperTask和2个ReducerTask. 其中pid0001的放入Reducer1内, pid00002的放入Reducer2内. 我们发现Reducer1的负载为10, Reducer2的负载为2.
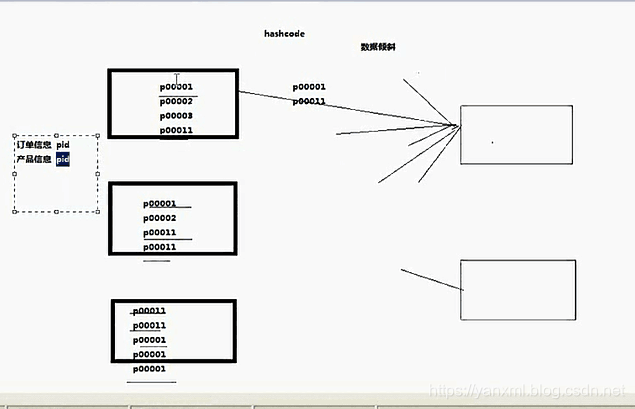
明显的负载不均衡, 这也就是常说的数据倾斜问题. 解决数据倾斜的办法非常简单. 使数据变得均匀分配. (Ps: 貌似像废话,什么都没说. 汗) 对于这个问题的解决办法主要有2:
- 将数据重新切分, 不使用以
key为主要分配标准的切法. 但是又想要保持之前的业务逻辑有点不太可能, 需要寻找一种可靠的切法. 又要将订单表与匹配的手机类别放在一起会复杂化逻辑.(不是不可以, 比如一块内处理多少的数据. 并且将其切成两份. 比如:<订单块1><订单块2><类别1>分成<订单块1><类别1>/<订单块2><类别1>, 从原来的1个Reducer上变成分配到2个Reducer上.) - 使用缓存技术. 像我们的
手机类别表的数据量不是特别多的时候,可以使用这种策略. 这种Join的方式, 其数据的处理主要是在Mapper端进行完成的, 我们将其称为MapJoin.
其代码主要如下所示:
public class MapJoinPhoneOrderInfoDriver {
// 1. setup() 2. map() 3. cleanup()
// 通过阅读父类Mapper的源码发现 setup方法是在maptask处理数据之前调用一次 可以用来处理一些初始化操作.
static class MapJoinPhoneOrderInfoMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
// 使用一个HashMap缓存一个产品信息表
Map<String, String> pdInfoMap = new HashMap();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context)throws IOException, InterruptedException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("phonedata")));
String line;
while(StringUtils.isNotEmpty(line = br.readLine())){
String []fields = line.split(" ");
pdInfoMap.put(fields[0], fields[1]);
}
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String orderLine = value.toString();
// 设置只读取订单类型的文件.
String []fields = orderLine.split(" ");
String name = pdInfoMap.get(fields[1]);
Text k =new Text();
k.set(orderLine + " "+name);
context.write(k, NullWritable.get());
}
}
public static void main(String []args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException{
Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name", "yarn");
conf.set("mapreduce.framework.name", "local");
conf.set("yarn.resourcemanager.hostname", "localhost");
conf.set("fs.defaultFS", "hdfs://localhost:9000/");
Job job = Job.getInstance(conf);
// job.setJar("/");
// job.setJar("/Users/Sean/Documents/Gitrep/bigdata/hadoop/target/hadoop-0.0.1-SNAPSHOT.jar");
// 指定本程序jar包所在地址
job.setJarByClass(MapJoinPhoneOrderInfoDriver.class);
//指定本业务job需要使用的mapper业务类
job.setMapperClass(MapJoinPhoneOrderInfoMapper.class);
// 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 指定map端的join操作不需要reduce阶段, 设置reduce阶段的数目为0
job.setNumReduceTasks(0);
// 指定最终输出数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(NullWritable.class);
// 缓存一个文件到所有到maptask的目录classpath
// job.addArchiveToClassPath(archive);
// 缓存一个文件到task结点的工作目录.
// job.addCacheArchive(uri);
// 缓存普通文件到task的classpath
// job.addFileToClassPath(file);
// job.addCacheFile(uri);
// 将产品表文件 缓存到task工作结点到工作目录中.
job.addCacheFile(new URI("hdfs://localhost:9000/join/phone/input/phonedata"));
// 当数目小于分片数目时候 会报错. 多余时,则有的分片内为空.
// job.setNumReduceTasks(5);
// // 指定job的输入文件所在目录
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// // 指定job的输出结果
// FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 指定job的输入文件所在目录(或者准确定位为某个单独的文件.)
FileInputFormat.setInputPaths(job, new Path("/join/phone/input/orderdata"));
// 指定job的输出结果
FileOutputFormat.setOutputPath(job, new Path("/join/phone/output"));
Path outPath = new Path("/join/phone/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
// 将job中配置的相关参数, 以及job所用的java类所在的jar包,提交给yarn执行
// job.submit();
//
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
值得注意的是:
- Driver端: 我们将
手机类别表放入通用的缓存空间job.addCacheFile(new URI("hdfs://localhost:9000/join/phone/input/phonedata"));. - Mapper端: 我们在
setup()方法时,将手机类别表加载到内存中了. - Reducer端: 本次, 未使用到
Reducer. 我们通过job.setNumReduceTasks(0);将其设置为0.
缓存相关
在上防的Driver中, 我们通过缓存加载资源. 本小节简单的介绍下Job的几种缓存类型.
// 缓存一个文件到所有到maptask的目录classpath
// job.addArchiveToClassPath(archive);
// 缓存一个文件到task结点的工作目录.
// job.addCacheArchive(uri);
// 缓存普通文件到task的classpath
// job.addFileToClassPath(file);
// job.addCacheFile(uri);
// 将产品表文件 缓存到task工作结点到工作目录中.
job.addCacheFile(new URI("hdfs://localhost:9000/join/phone/input/phonedata"));
Q & A
异常1:
Error: java.lang.ClassCastException: >com.yanxml.bigdata.hadoop.mr.join.reducejoin.HadoopTransferBean cannot be cast to com.sun.corba.se.spi.ior.Writeable at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:56) at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:1) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Error: java.lang.ClassCastException: com.yanxml.bigdata.hadoop.mr.join.reducejoin.HadoopTransferBean cannot be cast to com.sun.corba.se.spi.ior.Writeable at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:56) at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:1) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Container killed by the ApplicationMaster. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143 Error: java.lang.ClassCastException: com.yanxml.bigdata.hadoop.mr.join.reducejoin.HadoopTransferBean cannot be cast to com.sun.corba.se.spi.ior.Writeable at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:56) at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:1) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Error: java.lang.ClassCastException: com.yanxml.bigdata.hadoop.mr.join.reducejoin.HadoopTransferBean cannot be cast to com.sun.corba.se.spi.ior.Writeable at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:56) at com.yanxml.bigdata.hadoop.mr.join.reducejoin.PhoneOrderInfoDriver$PhoneOrderInfoMapper.map(PhoneOrderInfoDriver.java:1) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)解决措施:
static class PhoneOrderInfoMapper extends Mapper<LongWritable, Text, IntWritable, Writeable>转变为static class PhoneOrderInfoMapper extends Mapper<LongWritable, Text, IntWritable, HadoopTransferBean>. 个人猜测这是因为传递数据的类型不能是接口类型导致.(猜测). 用于传输的数据只能是实体类.(Writerable为接口类型)
Reference
[1]. Markdown创建表格