前言: 首先对于数据库有一定的了解,会对于Mysql的学习有一定的帮助; 数据库主要分为 DB(数据库),DBMS(数据库管理系统),SQL(结构化查询语言,用于和DBMS通信的语言);这篇要讲的DQL(数据查询语句)是属于SQL语言中的一种语言,因此是必学的语言,希望可以有一定的帮助。
Mysql的相关知识
好处 :
1.持久化数据到本地
2.可以实现结构化查询,方便管理
数据库主要分为:
- DB(数据库),保存一系列有组织的数据容器。
- DBMS(数据库管理系统),用于对DB获得数据进行操作管理,又称为数据库软件(产品)
- SQL(结构化查询语言,用于和DBMS通信的语言):DML语言,TCL语言,DDL语言,DQL语言;
Mysql服务的启动和停止:
方式一:计算机——右击管理——服务——MySQL
方式二:通过管理员身份运行cmd命令提示行
net start mysql(启动服务)
net stop mysql(停止服务)
Mysql服务的登录和退出:
方式一:通过MySQL自带的客户端
只限于root用户
方式二:通过cmd命令提示行关闭,未配置MySQL环境变量,需在MySQL安装的bin下启动cmd
登录:
mysql 【-h主机名 -P端口号 】-u用户名 -p密码
退出:
exit或ctrl+C
MySQL的语法规范:
不区分大小写
使用“;”结尾
各子句一般分行写
关键字不能缩写也不能分行
合理使用缩进
注释:
单行注释:#注释文字
单行注释:-- 注释文字
多行注释:/* 注释文字 */
DQL语言(数据查询语句)
1.基础查询
语法:
select(选择,过滤,查看) 查询列表 from 表名;
类似于: System.out.println(打印东西);
特点:
1.查询列表可以是: 表中的字段、常量值、表达式、函数
2.查询的结果是一个虚拟的表格
(1).查询表中的单个字段
SELECT `查询列表` FROM `表`;
(2).查询表中多个字段;
SELECT 查询列表,查询列表,查询列表,查询列表 FROM 表;
(3).查询全部字段;
SELECT * FROM 表;
(4).查询常量值;
SELECT 'job';
(5).查询表达式;
SELECT 100*98;
(6).查询函数(类似于java中方法);
SELECT VERSION();
(7).起别名
特点:
1.便于理解;
2.当要查询多个字段时,出现重名的情况,使用别名可以区分开;
方式一:使用关键字AS
SELECT 查询列表 AS 别名,查询列表 AS 别名 FROM 表;
方式二:使用空格
SELECT 查询列表 别名,查询列表 别名 FROM 表;
(8).去重
运用关键字DISTINCT进行去重显示;
SELECT DISTINCT department_id FROM employees;
(9).mysql中的+号作用
作用:仅仅作为运算符;
select 100+90;两个操作数为数值型,则做加法运算
select '123'+90;只要其中一方为字符型,则会试图将字符型转换为数值型;
如果转换成功,则继续做加法运算;
转换失败,则将字符型转换为0进行加法运算;
select null+90; 只要其中一个为null,则结果肯定为null;
2.条件查询
语法(运算步骤):
select 查询列表;(3) from 表名;(1) where 筛选条件;(2)
分类:
1.按条件表达式筛选
条件运算符:> < = <>(!=) >= <=
2.按逻辑表达式筛选
逻辑运算符:and(&&) or(||) not(!)
3.模糊查询
like , between and , in , is null
一、按条件表达式筛选
#案例1:查询工资>1200的员工信息;
SELECT * FROM employees WHERE salary>12000;
二、逻辑运算符筛选
and(&&) or(||) not(!)
用于:需要多个条件表达式来进行判断时;
三、模糊查询
1.like(查找含有某种特殊的范围)
特点:一般和通配符搭配使用,可以判断字符型和数值型;
通配符:
'% '为任意多个字符,也包含0字符;
'_ '为任意单个字符;
案例1:查询表中包含了字符a的列表信息
select * from 表 where 筛选条件 like ‘%a%’;
案例2: 查询表中中第二个字符为_的列表信息;
select 查询列表 from 表 where 筛选条件 like ‘_\_%’;
转译字符 mysql中'\'为自带的转译字符,将特殊字符转换为普通字符;我们也可以通过自己来自定义转译字符,但需要后面用ESCAPE 关键字来进行说明;
select 查询列表 from 表 where 筛选条件 like ‘_$_%’ ESCAPE ‘$’;
2.between and(查询某范围的)
between 100 and 120 == >=100 and <=120;
①使用between and 可以提高语句的简洁度;
②包含两个临界值;
③两个临界值位置不能交换;
案例1: 查询员工编号在100到120之间的员工信息
select * from 员工表 where 员工id列表 between 100 and 120;
3.in(查询包含某一类的)
说明:判断某字段的值是否属于in列表中的某一项;
特点:
①使用in可以提高语句的简洁度;
②in列表的值类型必须一致或者兼容;
③in列表不能使用通配符;
案例1:查询员工的工种编号是IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号;
select 查询员工名列表,查询工种编号列表 from 员工表 where 工种编号列表
in('IT_PROG','AD_VP','AD_PRES');
4.is null(判断是否为null值)
注意:=或者<>不能用于判断null值;
用于:is null 或者 is not null 用于判断null值,可读性较高;
补充:isnull函数,用于:判断某字段或表达式是否为null,是返回1,否返回0;
5.安全等于 :<=>
说明:可读性较小,既可以判断null值,也可以判断普通数值;
3.排序查询
语法:
select 查询列表
from 表
[where 筛选条件]
order by 排序列表 asc(升序)|desc(降序);
特点:
1. 如果不写默认是升序;
2. order by 子句中可以支持单个字段,多个字段,表达式,别名,函数进行排序
3.order BY 子句一般放在查询语句的最后面,进行查询最后的排序。(limit子句除外)
#案例1:查询员工信息,要求按工资降序或者升序排序
SELECT * FROM 员工表 ORDER BY 工资列表 DESC/ASC;
#案例2: 按照年薪的高低来显示员工的信息和年薪[可以通过别名来进行排序]
SELECT *,工资列表*12*(1+IFNULL(年薪列表,0)) 年薪
FROM employees
ORDER BY 年薪 DESC;
IFNULL(需要判断为null的列,更换查询到的null);
#案例3:查询员工先按照工资进行升序,再按照员工编号降序[按多个字段排序]
SELECT *
FROM 员工表
ORDER BY 工资列表(主要) ,员工编号 DESC (次要);
相当于主要排序方法和次要排序方法
4.常见函数
概念: 类似于java中的方法,将一组的逻辑语句封装在方法体中,对外暴露方法名
好处:1.隐藏了实现细节 2.提高代码的重要性
调用:select 函数名(实参列表) 【from 表】;
特点:
① 叫什么(函数名)
②干什么(函数功能)
分类:
1.单行函数
如:concat、length、ifnull等
特点:给一个值返回一个值
2.分组函数
功能:做统计使用,又称为统计函数、聚合函数、组函数
特点:给一组值返回一个值;
单行函数
1、字符函数(函数可以嵌套使用)
concat: 拼接
案例1:select concat(last_name,'_',first_name) 姓名 from employees;
substr: 截取子串
说明:substr(str(放入要截取的字符串),pos(从指定的索引处开始(该sql语言字符索引从1开始)))
substr(str,pos,len(为从指定索引处,往后截取指定的字符长度的字符));
upper: 转换成大写
lower: 转换成小写
trim: 去前后指定的空格和字符
注意:不会清楚字符之间的空格或字符.
案例:select trim('a' from'aaaaaaa杨aaaa不悔aaaaa');
ltrim:去左边空格
rtrim: 去右边空格
'replace': 替换(所有替换)
案例:select replace('周芷若爱上张无忌周芷若','周芷若','赵敏');
lpad: 左填充用指定的字符长度实现左填充指定长度;
如果指定长度小于所需要填充的字符,则从左往右显示指定字符长度的字符;
案例:select lpad('殷素素',10,'*');
select lpad('殷素素',2,'*');
rpad: 右填充 则从左往右显示指定字符长度的字符;如果指定长度小于所需要填充的字符,则从左往右显示指定字符长度的字符;
案例:select rpad('殷素素',10,'*');
select rpad('殷素素',2,'*');
instr: 返回子串第一次出现的索引,如果找不到返回值为0;
案例:select INSTR('杨不悔爱上了殷六侠','殷六侠');
length: 获取字节个数,汉字的字节个数有不同的字符集,
utf8为一个汉字三个字节,JBK占两个字节;
2.数学函数
round: 四舍五入
案例: select round(1.57,D(确保保留小数点后几位));
select round(1.55)将小数点四舍五入转换为整数;
rand: 随机数
floor: 向下取整(返回值为小于等于参数的最大整数);
ceil: 向上取整(返回值为大于等于参数的最小整数);
mod: 取余(mod(被除数,除数));
truncate: 截断(truncate(参数,D(小数点保留后几位)))
案例:select truncate(1.263,1);
3、日期函数
now: 当前系统日期+时间
now();
curdate: 当前系统日期
curdare();
curtime: 当前系统时间
curtime();
DIFFRENCE(日期,日期)用于计算日期之间的相差天数
可以获取指定部分的年,月,日,小时,分钟,秒
YEAR(参数)年;month(参数) 月;.....;
str_to_date: 将字符转换成日期 str_to_date(日期参数,日期格式);
date_format: 将日期转换成字符 date_format(日期,日期字符格式);
monthname:以英文形式返回月
时间参数格式:
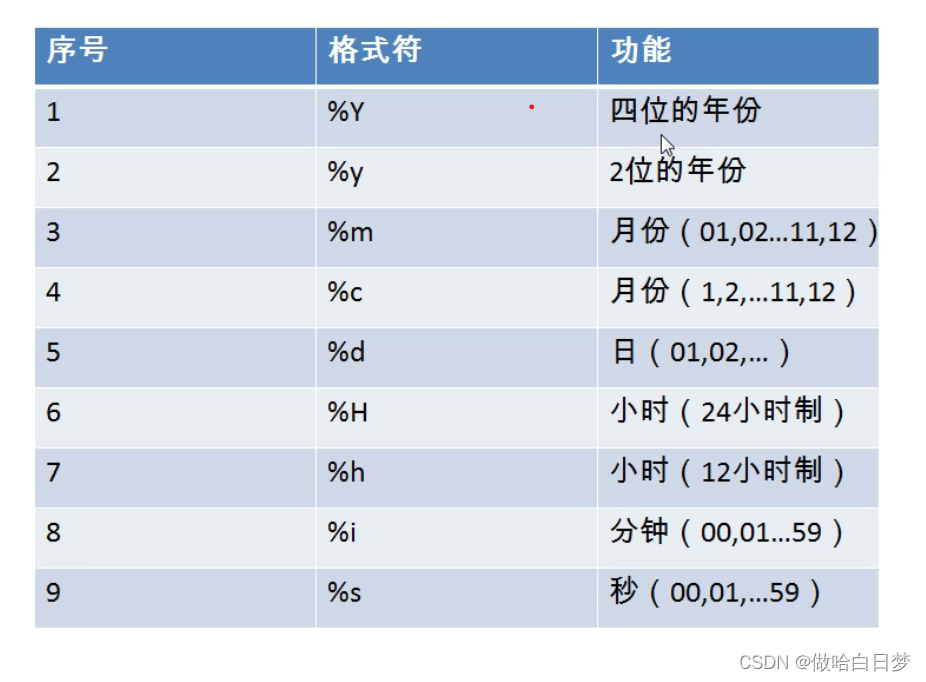
4、流程控制函数
if 处理双分支
案例: select if(10>5,'大','小');
case语句 处理多分支(注意处理时,需要加以字符型或者数值型的区分)
情况1:处理等值判断(当作为表达式时,只能显示值)
case 要判断的字段或者表达式
when 常量1 then 要显示的值1或者语句1;
when 常量2 then 要显示的值2或者语句2;
....
else 要显示的值n或者语句n;
end
情况2:处理条件判断(等同if else...)
case
when 条件1 then 要显示的值1或者语句1;
when 条件2 then 要显示的值2或者语句2;
else 要显示的值n或者语句n;
5、其他函数
version: 版本
database: 当前库;
user: 当前连接用户;
password('字符'):返回该字符的加密形式;
MD5('字符'):返回该字符的MD5加密形式;
二、分组函数
分类:
sum 求和 、avg平均值、max 最大值、min 最小值、 count 计算个数(不为null的)
特点:
1.sum、avg一般用于处理数值型
max、min、count可以处理任何类型其中字符型最大最小是通过字符型排序获得的
2.以上的分组函数都忽略null值。
3.可以和distinct搭配实现去重的运算;
4.count函数详细介绍
count() from employees; 用于计算有个多少对象,行数;
count(参数) from employees; 通过增加一列,对于每行进行多一个参数,也用于计算行数;
效率:
MYISAM存储引擎下,count()效率较高
INNODB存储引擎下,count()和count(1)效率差不多,比count(字段)效率高
一般用count()用于统计行数
5. 和分组函数一同查询的字段有限制,要求是group by后的字段
5.分组查询
语法:
select 分组函数,列(要求出现在group by的后面)
from 表
[where 筛选条件]
group by 分组的列表
[order by 子句]
注意: 查询列表必须特殊,要求是分组函数和group by 后面出现的字段
特点:
1.分组查询中的筛选条件可以分为两类
数据源 位置 关键字
分组前筛选 原始表 放在group by子句的前面 where
分组后筛选 分组后的结果表 放在group by子句的后面 having
①分组函数做筛选条件肯定放在having子句中
②能够分组前筛选的,就优先考虑使用分组前筛选
2.group by 子句支持单个字段分组,也支持多个字段分组(多个字段以逗号隔开,没有先后顺序),表达式或函数(用的较少);
3.排序:所排序的顺序放在分组函数的最末尾;
注意:在进行分组查询时,要注意查询的列表是谁为分组的列表;
6.连接查询(重点)
含义:又称多表查询,多表连接:
使用情况:当我们需要查询的字段是来自多个表时,或者涉及多个表时;
出现问题(笛卡尔乘积现象): 表1 有m行,表2有n行,结果为m*n行;
发生原因: 因为当两个表进行连接输出时,会对于第一个表中每一个列去另一个表中去寻找想匹配的,
然而并没有添加限制条件,筛选条件,会导致每一个都匹配,因此会产生笛卡尔乘积现象;
如何避免: 添加有效的连接条件
分类:
一、sql92标准
sql92标准;仅仅支持内连接
内连接:
1.等值连接
(1).语法:
SELECT
查询列表1,
查询列表2
FROM
表1 别名,
表2 别名
WHERE 连接条件;
(2).为表起别名
好处:1.提高语句的简洁度
2.区分多个重名字段
注意:如果为表起了别名,则查询的字段不能使用原来的表名去限定;
(3).可以加筛选
(4).可以加分组
特点:
①多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配之前所学的,排序,分组,筛选等
2.非等值连接:与等值连接通过where进行筛选条件范围来进行连接查询;
3.自连接
二.sql99标准语法(推荐)
sql99标准(推荐);支持内连接+外连接(仅支持左外和右外连接)+交叉连接
按功能分类:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接
右外连接
全外连接
交叉连接
语法:
select 查询列表
from 表1 别名 (连接类型)
join 表2 别名
on 连接条件
(where 筛选条件)
(group by 分组)
(having 筛选条件)
(order by 排序)
(重点)内连接:内连接类型:inner
(重点)外连接:
左外(重点):left (outer)
右外(重点):right(outer)
全外:full (outer)
交叉连接:cross
(1)内连接:
语法:
select 查询列表
from 表1 别名
inner join 表2 别名
on 连接条件
(where 筛选条件)
(group by 分组)
(having 筛选条件)
(order by 排序)
特点:
① 添加排序,分组,筛选
②inner可以省略
③筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
④inner join连接和sql92的等值连接效果是一样的,都是查询多表的交集;
1.非等值连接和等值连接
语法:
select 查询列表
from 表1 别名
inner join 表2 别名
on 连接非等值条件
(where 筛选条件)
(group by 分组)
(having 筛选条件)
(order by 排序)
2.自连接
#案例: 查询员工的名字、上级名字
SELECT 别名1.员工名 , 别名2.员工名(对应e表的上级名字)
FROM 员工表 别名1
JOIN 员工名 a ON 别名1.上级编号=别名2.员工编号;
(2) 外连接
应用场景:用于查询一个表中有,另一个表中没有的记录。其中有主表和从表之分;
特点:
1.外连接的查询结果主要为主表中的所有记录;
如果从表中有与它匹配,则匹配其值,反之则返回null值;
外连接的结果:为内连接的结果+主表中有而从表没有的记录。
2.左外连接,left jion 左边为主表
右外连接,right jion 右边为主表
3.左外和右外交换其表顺序,结果可以一致
4.全外连接=内连接的结果+表1或表2中一个有一个没有的
(3)交叉连接(等同sql92标准中笛卡尔乘积)
7.子查询(重点)
含义:出现在其他语句中的select语句,称之为子查询或者内查询,外部的查询语句称之为主查询或外查询。
分类:
按子查询出现的位置:
select后面:
仅仅支持标量子查询
from后面:
支持表子查询
where或having后面:(重点)
主要支持标量子查询(单行),列子查询(多行);但也支持行子查询,且少用
exists后面(相关子查询):
支持表子查询
按结果集的行列数不同:
标量子查询(结果集只有一行一列的)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集不限要求,一般多行多列)
一、where或having后面
1、标量子查询(单行子查询)
2、列子查询(多行子查询)
3、行子查询(多列多行)较为少用
特点:
①子查询放在小括号里
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用(> < >= <= = <>)
列子查询,一般搭配着多行操作符使用(in、any/some、all)
④子查询的执行优先于主查询执行
1.标量子查询
案例:谁的工资比Abel的工资高?
①首先先查询到abel的工资
SELECT salary(工资列表)
FROM employees(员工表)
WHERE last_name= 'Abel'
②然后通过abel的工资找到比他高的工资
SELECT salary,last_name
FROM employeeS
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name= 'Abel'
);
#注意事项:非法使用标量子查询
#1.标量子查询为单行子查询(即搭配了单行操作符的),不能查询到多行多列
#2.注意查询的范围
2.列子查询(多行子查询)
返回多行
使用到多种操作字符
操作字符:
(*)IN/NOT IN 等于列表中任意一个
ANY|SOME 和子查询返回的某一个值比较
ALL 和子查询返回的所有值进行比较
#案例:返回location_id是1400或1700的部门中的所有员工姓名
#①首先需要查询的是1400或1700的部门编码
SELECT department_id
FROM departments
WHERE location_id IN(1400,1700)
#②查询员工的姓名,要求部门编号是①列表中某一个
SELECT last_name
FROM employees
WHERE department_id IN(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
行子查询(结果集为一行多列或多行多列)
#案例:查询员工编号最小且工资最高的员工信息
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_Id),MAX(salary)
FROM employees
);
二、放在select的后面
仅仅支持标量子查询
#案例:查询每个部门的员工个数
SELECT d.*,(
SELECT COUNT(*)
FROM employees e
WHERE e.department_id=d.department_id
GROUP BY department_id
) 个数
FROM departments d;
三、from后面
要求:当子查询充当一张表时,必须起别名
四、exists后面(相关子查询)
语法:exists(完整的查询语句)
结果:1或0
用于:判断子查询语句是否有值;
8.分页查询(重点)
基本应用场景:当显示的数据过多,一页无法显示全,则需要进行分页提交sql请求
语法:
select 查询列表
from 表
{
[join type] join 表2
on 连接条件
where 筛选条件
group by分组字段
having 筛选条件
order by 排序}
limit offset(显示的条目的起始索引,默认的起始索引从0开始),size(要显示的条目个数);
特点:
①limit语句放在查询语句的最后
②公式:
要显示的页数page,每页的条数目size
语法:
select 查询列表
from 表
limit (page-1)*size,size;
#案例1:查询前五条员工信息
SELECT *
FROM employees
LIMIT 0,5;
9.联合查询
(其关键字)union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
........
应用场景:
要查询的结果来自多个表中,且表之间没有直接的连接关系,但所需查询信息一致;
特点:
1、要求多条查询语句的查询列数一致
2、要求多条查询语句的查询每一列的类型和顺序一致
3.union关键字默认去重,使用union all可以包含重复项;
#案例:查询部门编号大于90或者邮箱包含a的员工信息
SELECT * FROM employees WHERE department_id>90(部门编码>90)
UNION SELECT * FROM employees WHERE email LIKE '%a%';