需求1:找社区
有一份数据部分如下,比如:刘备和关羽有关系,说明他们是一个团伙,刘备和张飞也有关系,那么刘备、关羽、张飞归为一个社区,以此类推。
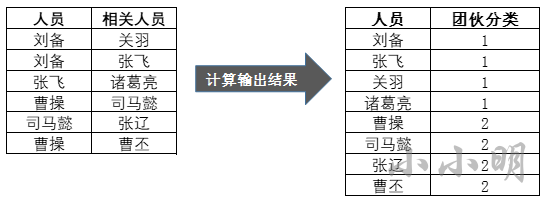
在python中这是典型的查找连通图的问题,直接的思路是使用现成的包直接调用求解连通图的算法即可。
import networkx as nx
g = nx.Graph()
data = [
['刘备', '关羽'],
['刘备', '张飞'],
['张飞', '诸葛亮'],
['曹操', '司马懿'],
['司马懿', '张辽'],
['曹操', '曹丕']
]
g.add_edges_from(data)
for sub_g in nx.connected_components(g):
sub_g = g.subgraph(sub_g)
g_node = sub_g.nodes()
print(g_node)
结果:
['刘备', '关羽', '张飞', '诸葛亮']
['曹操', '司马懿', '张辽', '曹丕']
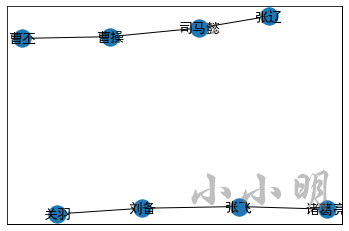
使用networkx我们还可以将图绘制出来:
from matplotlib import pyplot as plt
import networkx as nx
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
nx.draw_networkx(g)
plt.show()
需求2:统一用户识别
上述需求在使用现成的图算法的情况下还是非常简单的,下面再看看另一个问题:
每一行代表广告平台接受到的用户访问数据,但是广告商获取到唯一标识不总是一样,有时可以获取到mac地址,有时是手机号,有时设备码,这些唯一标识字段虽有缺失,但都属于同一个用户,现在需要把属于同一用户的数据找出来,并将标签进行合并。
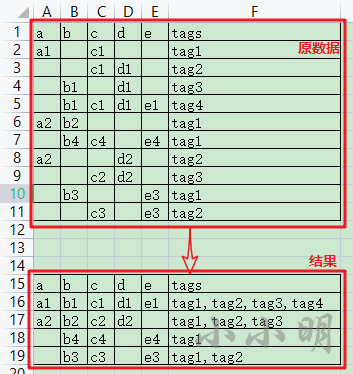
对于这个需求,我的思路是按照每个主键列分别分组,将唯一的行号索引作为关联关系的边,从而得到归属同一用户对应的行号。
首先创建数据:
import pandas as pd
df = pd.DataFrame([
['a1', None, 'c1', None, None, 'tag1'],
[None, None, 'c1', 'd1', None, 'tag2'],
[None, 'b1', None, 'd1', None, 'tag3'],
[None, 'b1', 'c1', 'd1', 'e1', 'tag4'],
['a2', 'b2', None, None, None, 'tag1'],
[None, 'b4', 'c4', None, 'e4', 'tag1'],
['a2', None, None, 'd2', None, 'tag2'],
[None, None, 'c2', 'd2', None, 'tag3'],
[None, 'b3', None, None, 'e3', 'tag1'],
[None, None, 'c3', None, 'e3', 'tag2'],
], columns=list("abcde")+["tags"])
构建图的顶点和边:
import networkx as nx
g = nx.Graph()
keylist = list("abcde")
g.add_nodes_from(df.index)
for c in keylist:
for ids in df.index.groupby(df[c]).values():
n = len(ids)
if n == 1:
continue
for i in range(n-1):
for j in range(i+1, n):
g.add_edge(ids[i], ids[j])
绘制看看效果:
nx.draw_networkx(g)
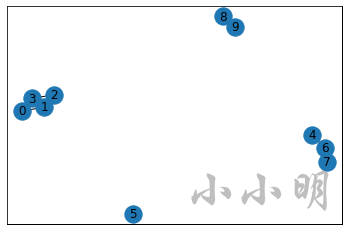
可以看到,有联系的行已经顺利的关联到一起。
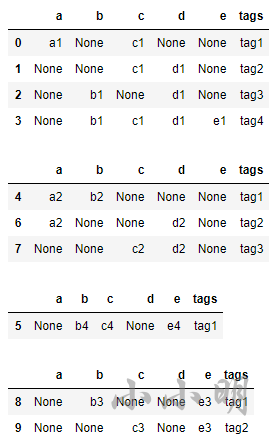
下面我们根据连通顶点的索引值对原始的datafream进行分组:
for sub_g in nx.connected_components(g):
sub_g = g.subgraph(sub_g)
g_node = list(sub_g.nodes())
df_split = df.iloc[g_node]
display(df_split)
结果:
然后将每个切片合并,下面以最后一个切片为例测试一下:
row = df_split[keylist].bfill().iloc[0]
row["tags"] = df_split.tags.str.cat(sep=",")
row
a None
b b3
c c3
d None
e e3
tags tag1,tag2
Name: 8, dtype: object
下面整理一下完整代码:
import networkx as nx
import pandas as pd
df = pd.DataFrame([
['a1', None, 'c1', None, None, 'tag1'],
[None, None, 'c1', 'd1', None, 'tag2'],
[None, 'b1', None, 'd1', None, 'tag3'],
[None, 'b1', 'c1', 'd1', 'e1', 'tag4'],
['a2', 'b2', None, None, None, 'tag1'],
[None, 'b4', 'c4', None, 'e4', 'tag1'],
['a2', None, None, 'd2', None, 'tag2'],
[None, None, 'c2', 'd2', None, 'tag3'],
[None, 'b3', None, None, 'e3', 'tag1'],
[None, None, 'c3', None, 'e3', 'tag2'],
], columns=list("abcde")+["tags"])
g = nx.Graph()
keylist = list("abcde")
g.add_nodes_from(df.index)
for c in keylist:
for ids in df.index.groupby(df[c]).values():
n = len(ids)
if n == 1:
continue
for i in range(n-1):
for j in range(i+1, n):
g.add_edge(ids[i], ids[j])
data = []
for sub_g in nx.connected_components(g):
sub_g = g.subgraph(sub_g)
g_node = sub_g.nodes()
ids = list(g_node)
df_split = df.iloc[ids]
row = df_split[keylist].bfill().iloc[0]
row["tags"] = df_split.tags.str.cat(sep=",")
data.append(row)
data = pd.DataFrame(data)
data
结果:
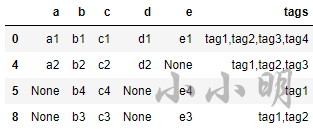
可以看到已经顺利的得到我们想要的结果。