索引的代价
索引是个好东西,可不能乱建,它在空间和时间上都会有消耗:
空间上的代价
每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会 占用 16KB 的存储空间,一棵很大的B+树由许多数据页组成,那就是很大的一片存储空间。
时间上的代价
每次对表中的数据进行 增、删、改 操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每 层节点都是按照索引列的值 从小到大的顺序排序 而组成了 双向链表 。不论是叶子节点中的记录,还 是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序 而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需 要额外的时间进行一些 记录移位 , 页面分裂 、 页面回收 等操作来维护好节点和记录的排序。如果 我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,会给性能拖后腿。
MySQL数据结构选择的合理性
全表遍历
这里都懒得说了。
Hash结构


上图中哈希函数h有可能将两个不同的关键字映射到相同的位置,这叫做 碰撞 ,在数据库中一般采用 链 接法 来解决。在链接法中,将散列到同一槽位的元素放在一个链表中,如下图所示:
实验:体会数组和hash表的查找方面的效率区别
@Test
public void test1(){
int[] arr = new int[100000];
for(int i = 0;i < arr.length;i++){
arr[i] = i + 1;
}
long start = System.currentTimeMillis();
for(int j = 1; j<=100000;j++){
int temp = j;
for(int i = 0;i < arr.length;i++){
if(temp == arr[i]){
break;
}
}
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start)); //time: 823
}
//算法复杂度为 O(1)
@Test
public void test2(){
HashSet<Integer> set = new HashSet<>(100000);
for(int i = 0;i < 100000;i++){
set.add(i + 1);
}
long start = System.currentTimeMillis();
for(int j = 1; j<=100000;j++) {
int temp = j;
boolean contains = set.contains(temp);
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start)); //time: 5
}Hash结构效率高,那为什么索引结构要设计成树型呢?
于排序查询的SQL需求: 分组:group by 排序:order by 比较:
哈希型的索引,时间复杂度会退化为O(n),而树型的“有序”特性,依然能够保持O(log(n)) 的高效率。 任何脱离需求的设计都是耍流氓。 多说一句,InnoDB并不支持哈希索引。
Hash索引适用存储引擎如表所示:

Hash索引的适用性:

采用自适应 Hash 索引目的是方便根据 SQL 的查询条件加速定位到叶子节点,特别是当 B+ 树比较深的时 候,通过自适应 Hash 索引可以明显提高数据的检索效率。
我们可以通过 innodb_adaptive_hash_index 变量来查看是否开启了自适应 Hash,比如:
show variables like '%adaptive_hash_index';
二叉搜索树
如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。
1. 二叉搜索树的特点
2. 查找规则

创造出来的二分搜索树如下图所示:
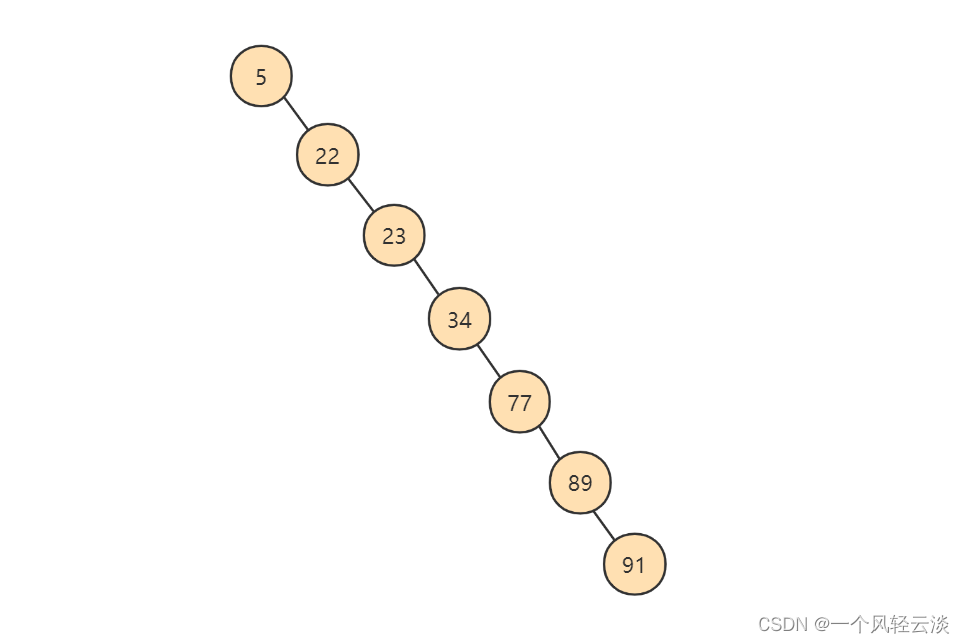
为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把 原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
AVL树
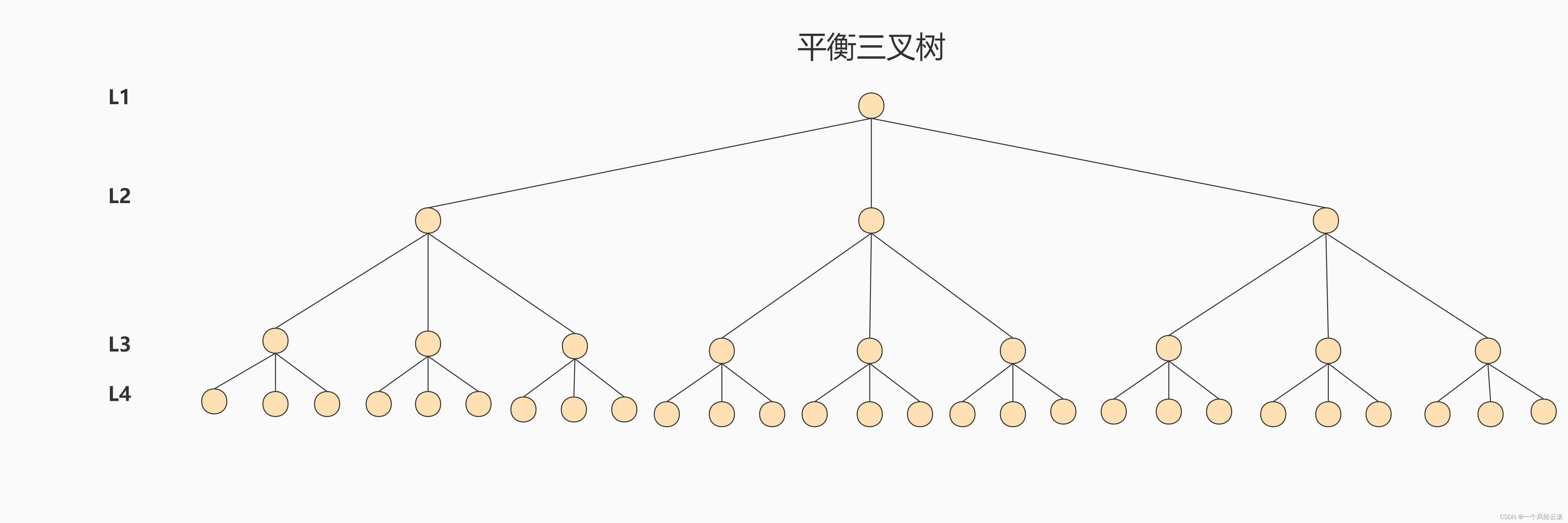
针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面 的三叉树来进行存储:
B-Tree
B 树的结构如下图所示:
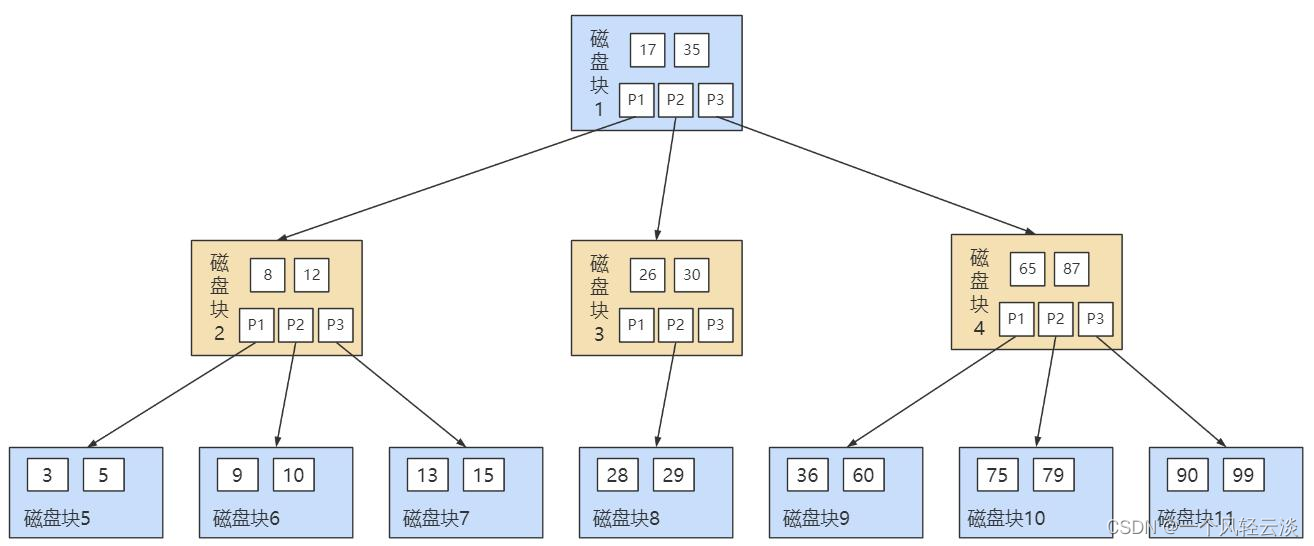
一个 M 阶的 B 树(M>2)有以下的特性:
1. 根节点的儿子数的范围是 [2,M]。
2. 每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为
[ceil(M/2), M]。
3. 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。
4. 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i] 。此时 k-1 个关键字相当于划分了 k 个范围,也就是对应着 k 个指针,即为:P[1], P[2], …,P[k],其中 P[1] 指向关键字小于 Key[1] 的子树,P[i] 指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k]
指向关键字大于 Key[k-1] 的子树。
5. 所有叶子节点位于同一层。 上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它 有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15)
大于 12,刚好符合刚才我们给出的特征。 然后我们来看下如何用 B 树进行查找。假设我们想要 查找的关键字是 9 ,那么步骤可以分为以下几步:
1. 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
2. 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
3. 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。 你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比 较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行 比较所需要的时间要多,是数据查找用时的重要因素。 B 树相比于平衡二叉树来说磁盘 I/O 操作要少 , 在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。
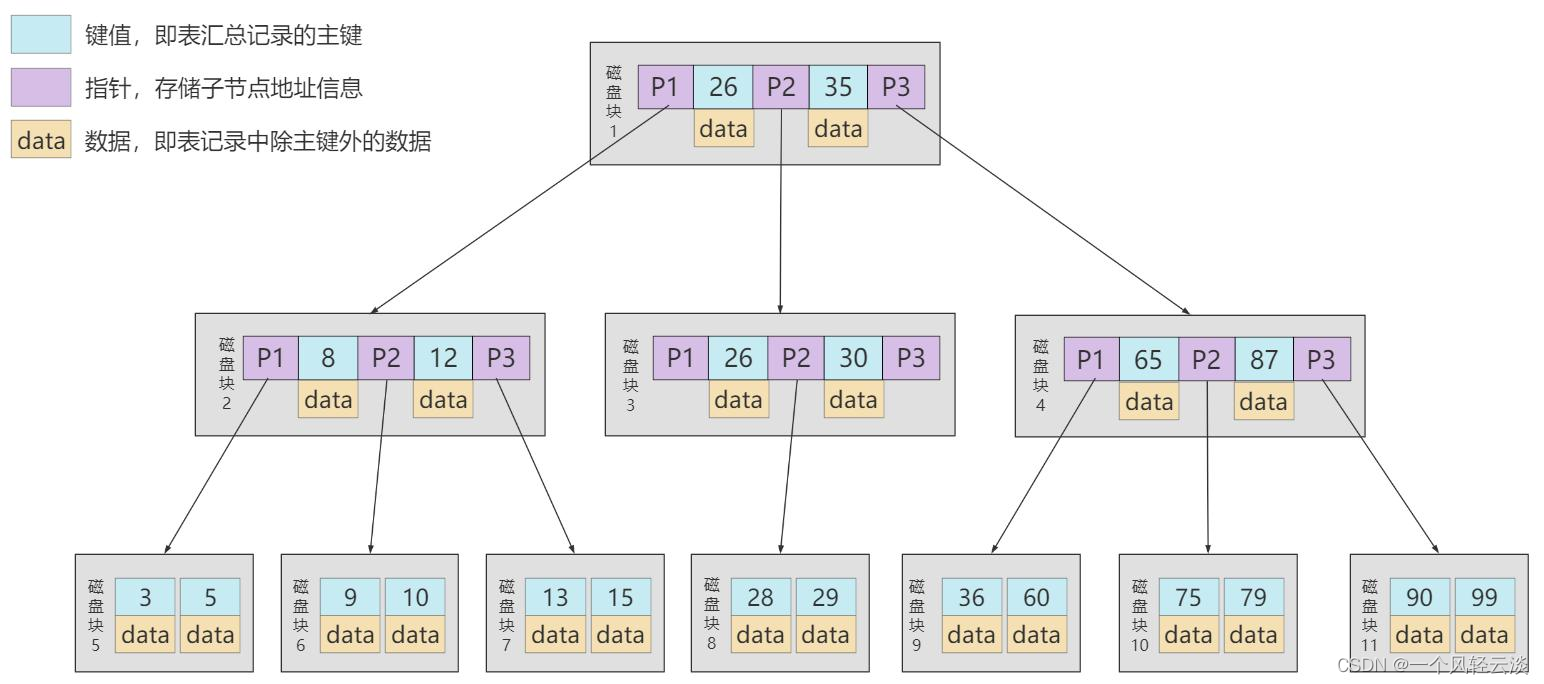
B+Tree

B+ 树和 B 树的差异:
1. 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数+1。
2. 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最 小)。
3. 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非 叶子节点既保存索引,也保存数据记录 。
4. 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大 小从小到大顺序链接。