目录

一. 语音的基本特征:
语音按照发音原理可以分为清音和浊音,语音的音调、能量分布等可以用基频、谐波、共振峰等特征来分析。
1.1 语音的产生

声道:声音传播所经过的地方。
发声的声道主要是指我们的三个腔体,即咽腔、口腔和鼻腔。 语音是有声源和声道共同作用产生。
1.2 清音与浊音
定义
按照声源不同可以将语音分为两类:
- 声带振动作为声源产生的声音,叫浊音。比如“a, o, e”等
- 由气体进过唇齿等狭小区域由于空气和腔体摩擦产生的声音,叫清音。“shi、chi、xi”
频谱
清音和浊音的频谱:
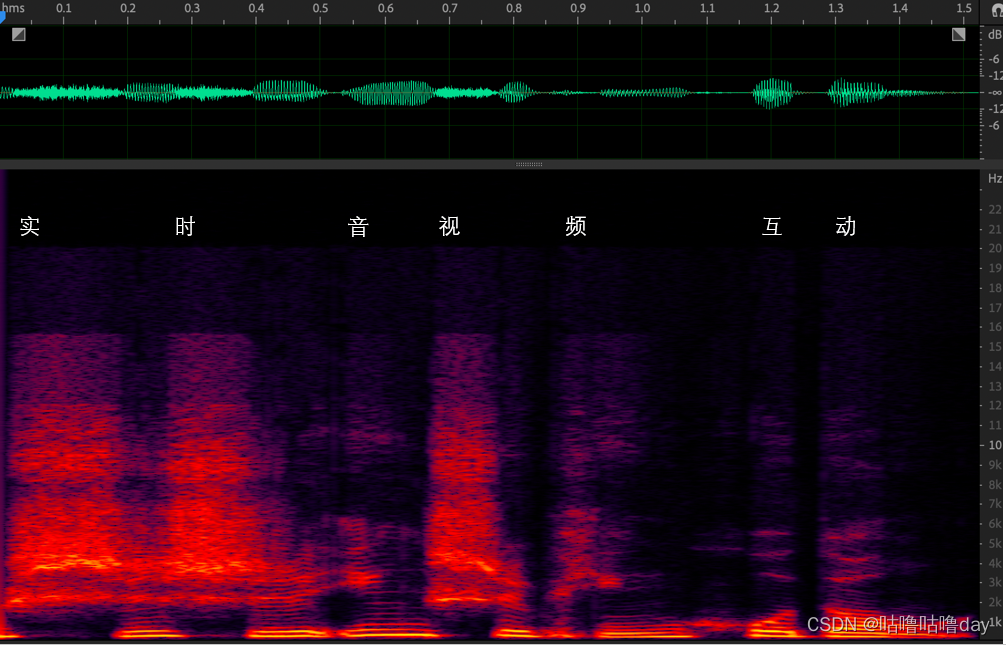
从频域中看到浊音 " 互动"明显低频能量更集中,而清音 实时和视 在频谱上显示比较均匀,高频也存在不少能量。 从这个规律可以从频谱上分析出轻易与浊音。
1.3 基频
发浊音时声带振动会产生一个声波,叫基波,并且把基波的频率叫基频(F0),对应到我们平时说的音调。 比如唱歌音调更高是你的声音基频更高。
男生基频:100~200Hz,女生在140~240Hz。 小孩300Hz,年龄基频越大越低。
1.4 谐波
声带振动产生的基波在传输过程中在声道表面反复碰撞反射,产生频率倍数于基频的声波叫谐波。

一次谐波、二次谐波等
谐波频率和基频是浊音能量集中的地方。
1.5 共振峰
首先高次谐波是低次谐波在腔体表面碰撞反射得到,并且反射会导致能量的衰减。
但由于在浊音产生的过程中,声源的振动信号通过声带时,声道也发生共鸣,与声道共振频率接近的能量被增强,远离声道共振频率的就被衰减,从而谐波的能量组成啦一组 高低起伏的形状包络。 包络的巅峰位置叫共振峰。
所以比如一个200Hz的基频,大部分能量都分布在200Hz以及200Hz的整数倍的频率上。
由于不同的发音,声道的三个腔体(咽腔、口腔、鼻腔)随发音的不同,开合、形状都会发生变化,从而形成了不同的腔体共振频率,所以共振峰的位置和峰值都不一样。 这也是语音识别背后的原理之一,即通过共振峰的位置和能量分布来识别音频代表的语音。
二. 语音信号的解析
分布基于时域和频域进行解析
2.1 窗函数
频谱泄漏
频谱泄漏:是指音频直接截断会出现 不同频率的能量分量。
为了防止频谱泄漏,所以使用加窗,即在原有信号中乘一个两端为0 的窗函数,减少截断信号的频谱泄漏。
常用的窗函数:Haning、hamming、Blackman等
如上图:加窗过程其实就是输入信号 乘以窗函数 得到两边小、中间高的新信号。
2.2 时域分析
短时过零率
每帧信号穿过0点的次数。如果是正弦信号,短时平均过零率为信号的频率 处以2倍的采样频率。
短时过零率也可以用来判断清音和浊音。 由于清音的频率集中的范围要高于浊音,所以浊音的过零率要低于清音。
短时能量
短时能量常被用来判断语音的起止位置或韵律。

应用:
- 可以区分清浊音。一般清音部分的能量要比浊音部分的能量要小很多。
- 可以区分是否存在语音。 比如,设置一个能量域值判断语音段是否为静音段条件。
- 能量的起伏在语音识别里也被用于判断韵律的特征。(比如重读音节)
结合应用与判断语音起止点位置:
将短时平均能量和短时过零率结合起来判断语音起止点位置。
在背景噪声较小情况下,短时能量比较准确;
当背景噪声较大时,短时平均过零率有较好的效果。 一般的 音频识别系统就是通过这两个参数结合,判断检测语音是否真的开始。
2.3 频域分析
短时傅里叶变换
频谱图的构建步骤:
- 加窗分帧,防止频谱泄漏
- 每一帧做快速傅里叶变换,将时域信号转成复数频域信号。
- 将傅里叶变换的结果对复数频域取模,再求对数转换成分贝(dB), 再用热力图的形式转换出来。
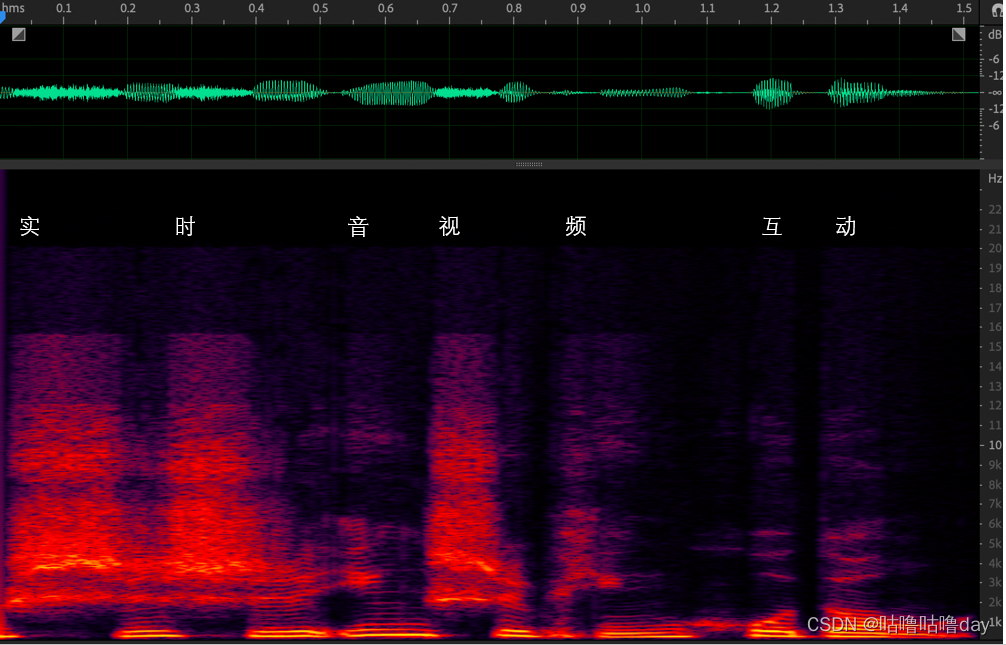
如上图 频谱横轴是时间,纵轴是频率,热力图的颜色代表频点能量大小。
梅尔谱(Mel sepctrum)
由于心理和听力系统的构造,人耳对以Hz为单位的频率并不十分敏感。我们区分的音调是以指数排列的。比如高八度就是频率乘2。 因此,对数的频率坐标能更好的反映人的实际听感。
人耳感知的响度与实际声压的对应关系:
如图人耳对4kHz的频率 对声压比较敏感,在两端的高频和低频需要更强的声压,所以跟8kHz采样有关。 4kHz也是猛兽的叫声能量分布范围。
梅尔谱的计算步骤:
- 首先,对语音信号进行预加重(平衡高低频能量)
- 然后,语音信号过STFT得到频率谱。
- 三角滤波器组对频率谱逐帧进行滤波。
三角滤波器组如下图,把频率分成若干个频段。低频人耳敏感频段,滤波器比较密集,高频不敏感的频段比较稀疏,更好的反映人耳的特性:
对梅尔谱以及进一步求倒谱系数得到的MFCC(梅尔倒谱系数),是语音领域常用的特征。
类似基于人耳听觉特性的特征还有 Bark谱、Gamma Tone Filter等。
三. 实践绘语谱图和梅尔图:
| #绘制STFT import numpy as np import librosa import matplotlib.pyplot as plt audio,sr=librosa.load('Path',sr=48000) n_fft=1024 ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1)) plt.plot(ft) plt.title('Spectrum') plt.xlabel('Frequency Bin') plt.ylabel('Amplitude') #绘制梅尔频谱 mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024) mel_spect = librosa.power_to_db(spect, ref=np.max)librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time'); plt.title('Mel Spectrogram'); plt.colorbar(format='%+2.0f dB'); |