R-CNN,Fast R-CNN,Faster R-CNN演化过程与原理详解_大胡子爷爷黎曼的小弟的博客-CSDN博客文章来源于视频https://www.bilibili.com/video/BV1af4y1m7iL1 、R-CNN1.1 算法流程(可分为四个步骤)一张图像生成1K~2K个候选区域(使用Selective Search方法,以下简称SS方法)对每个候选区域,使用深度网络提取特征特征送入每一类的SVM(支持向量机)分类器,判断是否属于该类使用回归器精细修正候选框位置R-CNN的流程图如上图所示,输入原图像后,先使用SS方法在图像选中一千到两千个候选框,将这么多个候选框分别送入卷积神经 https://blog.csdn.net/lukas_ten/article/details/115189752?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-115189752-blog-82839714.pc_relevant_multi_platform_whitelistv6&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-115189752-blog-82839714.pc_relevant_multi_platform_whitelistv6&utm_relevant_index=2
https://blog.csdn.net/lukas_ten/article/details/115189752?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-115189752-blog-82839714.pc_relevant_multi_platform_whitelistv6&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-115189752-blog-82839714.pc_relevant_multi_platform_whitelistv6&utm_relevant_index=2
一、R-CNN:

步骤:
- 用selective search的方法选出许多候选框;
- 对每个候选框分别执行卷积操作,提取特征;
- 把卷积做好的特征放到SVM支持向量机分类器和Bbox reg的回归器 (Bounding-box regression即边界框回归,用来微调检测框窗口和ground truth 窗口);
缺点:
- 候选框没有共享卷积神经网络,不同的框要构造不同的神经网络(因为卷积层虽然不要求图片大小,但是全连接层有要求,即输入输出大小相同);
- 分类用svm做,很麻烦;
- 特别费时,一次训练需要84小时,检测一张图片要84秒;
一、Region proposal:给定一张输入image找出objects可能存在的所有位置。用到的方法是基于滑窗的方式和selective search。
- 基于滑窗的方式:在目标检测时,为了定位到目标的具体位置,通常会把图像分成许多子块,然后把子块作为输入,送到目标识别的模型中。分子块的最直接方法叫滑动窗口法。滑动窗口的方法就是按照子块的大小在整幅图像上穷举所有子图像块。这种方法产生的数据量想想都头大。
- 基于区域region proposal:和滑动窗口法相对的是另外一类基于区域的方法。selective search就是其中之一!首先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。
二、Bounding-box regression 边框回归的作用:
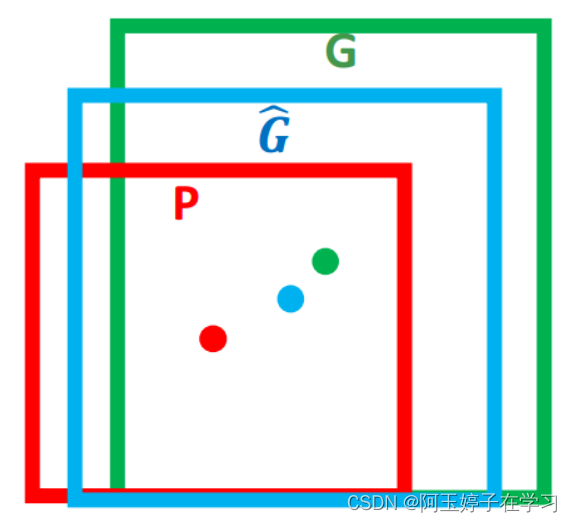
绿色的框表示Ground Truth, 红色的框为Selective Search提取的Region Proposal。
即便红色的框被分类器识别为飞机,但由于红色的框定位不准(IoU<0.5),那么这张图相当于没有正确的检测出飞机。 如果我们能对红色的框进行微调,使得经过微调后的窗口跟Ground Truth 更接近, 定位会更准确。 Bounding-box regression 就是用来微调这个窗口的。
三、Bounding-box regression 边框回归的目标:窗口一般使用四维向量(x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。 对于下图 , 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth,边框回归目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。

二、Fast R-CNN

步骤:
- 先执行卷积操作,这样可以特征共享卷积,一张图像只做一次卷积,加快了速度;
- 对原图像Selective search找到一系列框,再在特征图上找到对应的是原始图像上的框;
- Rol Pooling 之后,得到的特征大小一样的图像然后经过全连接层;
- 回归加分类;
缺点:
步骤2中原始图像的框先要对原图像做处理,找到一系列框,这个过程大概耗费两秒时间(只能在CPU中计算),然后再在特征图上通过特征图上的某一块,找到原图像对应的框。
R-CNN产生大量的region proposals导致处理速度慢,这就是ROI pooling提出的根本原因。
一、ROI pooling层:
能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
- 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
- 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
二、ROI pooling具体操作如下:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作;
ROI Pooling 就是将大小不同的feature map 池化成大小相同的feature map,利于输出到下一层网络中。
三、ROI pooling example:
1、我们有一个8*8大小的feature map,一个ROI,以及输出大小为2*2;
2、region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
3、将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到:
4、对每个section做max pooling,可以得到:



三、Faster R-CNN

Faster R-CNN = RPN + Fast R-CNN,红色圈和Fast R-CNN一样,而Faster R-CNN加入了RPN来提取候选框,替换了selective search算法,克服了提取候选框时间久的问题。
步骤:
- 对图像做卷积操作;
- 卷积完之后产生的特征图做RPN层操作,由特征图产生候选框;对候选框做2分类,是物体的留下,不是物体的删除。对留下来的候选框和已标签的候选框做回归,计算出loss;
- ROI pooling;
- 然后做n分类,然后和已标签的候选框做回归。
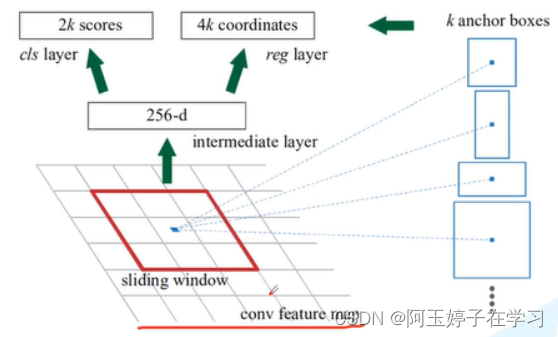
一、RPN结构:
1、在全局特征图上有一个滑动窗,每一个sliding window会选中K个候选框(anchor box)。之后把特征图经过两个全连接层进行展平,得到intermediate layer,这里利用的是ZF网络也就是前面提到的backbone,深度为256,如果用VGG16网络,则这里深度为512。再分别送入分类器和回归器,得到分类概率和边界框回归参数。
- 分类器: 针对每个anchor box生成两个概率,一个是前景概率,另一个是背景概率。(注意:这里概率只分为前景和背景两类,与前面N+1类不同)这里K个anchor box对应就会生成2K个概率(2K scores);
- 回归器: 针对每个anchor box生成四个回归参数,分别是坐标和宽高。这里K个anchor box对应生成4K个回归参数;
2、anchor box:
anchor box有三种尺度(128, 256, 512)和三种比例(1:1, 1:2, 2:1), 不同的尺度和比例决定了anchor box的大小和形状,如下9个anchor box大小和形状各不相同。
3、sliding window:
窗口采用的是3x3的卷积,步长和填充为1,这样滑动窗口可以遍历图像的每一个点,其所得的shape与feature map一模一样。
对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩下2K个候选框。

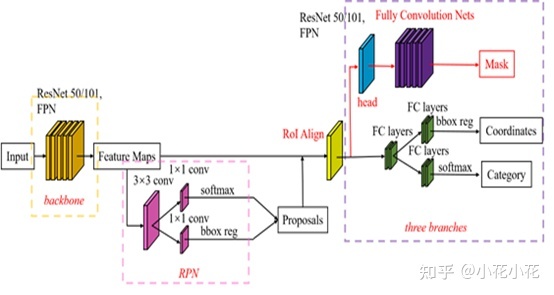
四、Mask R-CNN
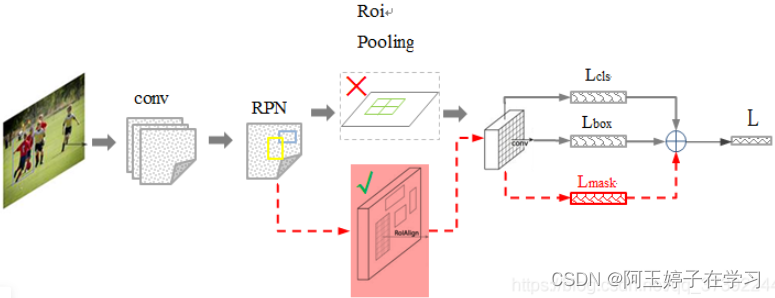
Mask R-CNN是在Faster R-CNN的基础上添加了一个预测分割mask的分支,如上图所示。
其中黑色部分为原来的Faster-RCNN,红色部分为在Faster-RCNN网络上的修改。将RoI Pooling 层替换成了RoIAlign层;添加了并列的FCN层(mask层);
Mask R-CNN算法主要是Faster R-CNN+FCN,更具体一点就是ResNeXt+RPN+RoI Align+Fast R-CNN+FCN;
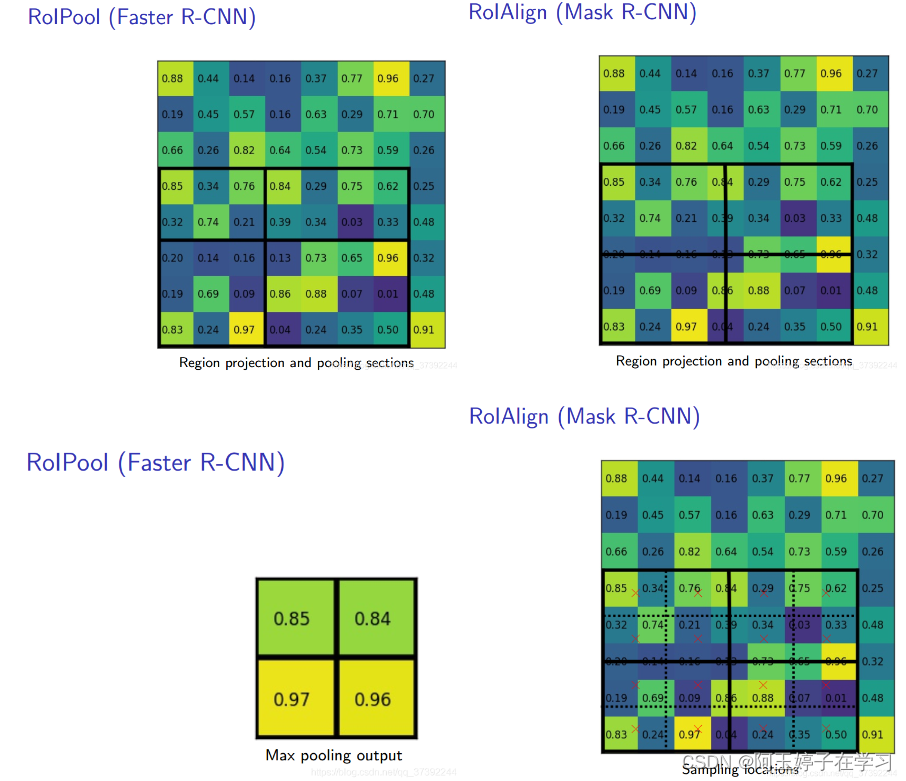
1、RoI Pooling 和RoIAlign的区别
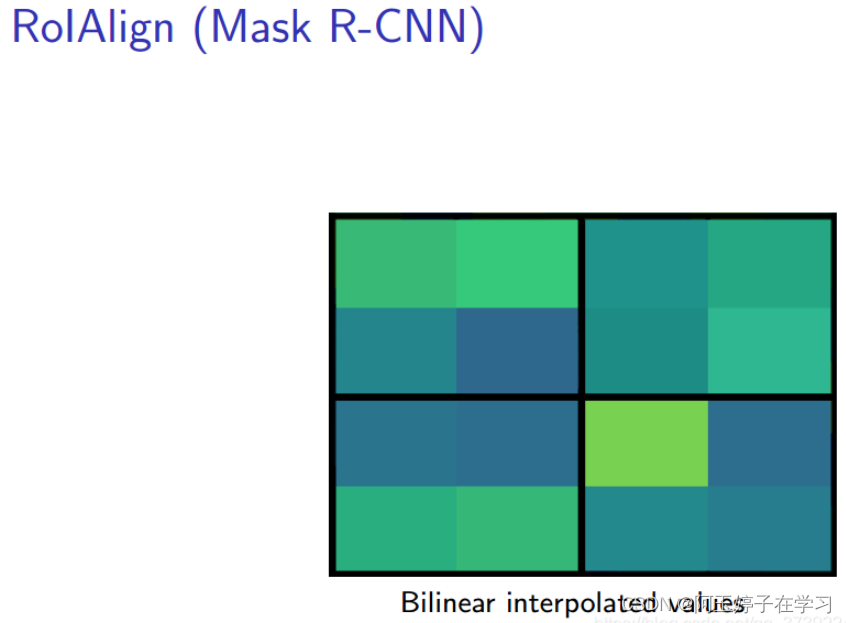
ROIAlign技术并没有使用量化操作,即不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。
那么如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。