R-CNN系列的网络是经典的目标检测和分割的网络,其中提出的一些新算法可以让人为之激动啊。下面简单介绍一下这几个网络。
论文翻译:
R-CNN:https://blog.csdn.net/itlilyer/article/details/107190083
Fast R-CNN:https://blog.csdn.net/itlilyer/article/details/107764472
Faster R-CNN:https://blog.csdn.net/itlilyer/article/details/108049850
Mask R-CNN:https://blog.csdn.net/itlilyer/article/details/108441734
R-CNN
论文
论文地址:https://arxiv.org/abs/1311.2524
R-CNN(Regions with CNN features):是13年发布的文章《Rich feature hierarchies for accurate object detection and semantic segmentation》文章中提出的,作者:Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik。
主要思想
2012年Krizhevsky等人的CNN网络加上LeCun的CNN网络中的技巧,使CNN的分类精度得到很大的提升并夺得ILSVRC的冠军。受此影响,R-CNN作者想要将CNN网络引入目标检测的任务,也是第一个将CNN网络应用于目标检测的。核心问题 是怎么将分类的结果应用到检测的任务中。为了解决这个问题,作者聚焦到两个问题上面:1)怎么通过深度网络来找到目标的位置;2)怎么使用少量标注数据来训练一个拥有大量参数的模型。
针对第一个问题,作者使用了候选区域的方式来解决在CNN中给目标定位的问题,过程主要分为三步:
1)每张输入的图片中提取2000个类别无关的候选区域);
2)然后使用CNN为每一个候选区域提取固定长度的特征;
3)最后使用特定类别的SVM进行分类。
第二个问题就是当前的数据量对于训练拥有大量参数的网络是远远不够的,作者使用的方法是先对模型进行无监督的预训练,然后进行指定类别的微调。作者通过实验证明该方法对于缺乏训练数据的情况下训练拥有大量参数的CNN网络是很有效的。
计算过程
先来一张论文中的截图:
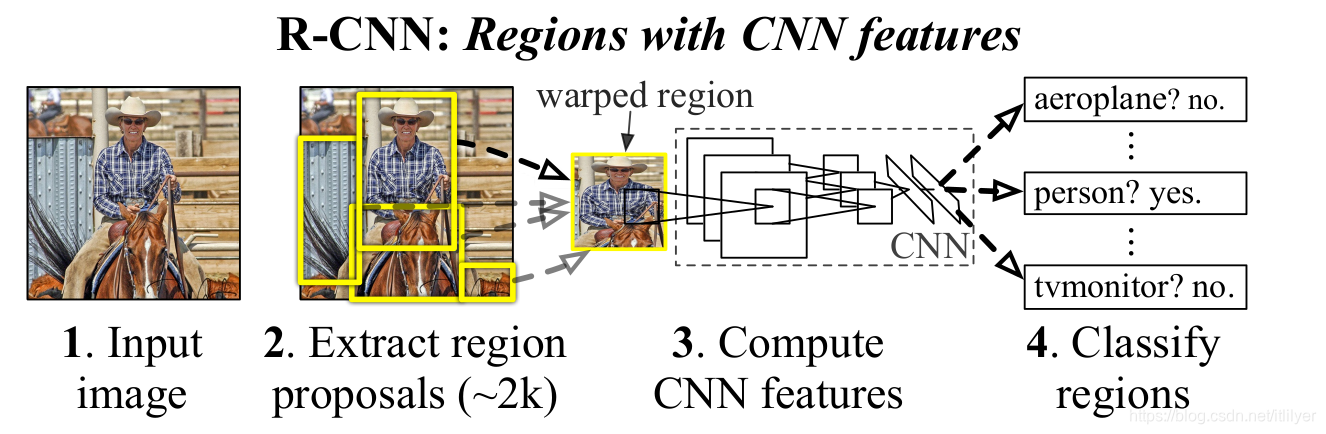 从上面图中可以看到整个流程分为四步,下面分别介绍一下:
从上面图中可以看到整个流程分为四步,下面分别介绍一下:
第一步: 输入一张图片,这个没什么好说的。
第二步: 提取候选区域。
生成候选区域的算法有很多,比如:objectness, selective search,category-independent object proposals, constrained parametric min-cuts (CPMC), multi-scale combinatorial grouping和Cireşan等。为了与之前的检测算法能够对照比较,R-CNN中作者选择的是Selective Search方法。使用Selective Search方法提取大约2000个候选区域。(Selective Search算法后面有时间单独写一篇文章介绍)。
第三步: 为每一个候选区域提取固定大小的特征图。
在得到2000个候选框后就需要使用CNN为候选框提取特征图了。R-CNN中使用AlexNet作为特征提取的网络,由于AlexNet网络要求输入的大小为227227,但是提取出来的候选区域大小是不同的,这里作者选择了最简单的处理方式——不管原始的候选区域的大小,直接缩放成227227的大小,并且在缩放前在候选区域的周围pad一圈原始图片的像素(文中pad了16个像素)。
CNN为每一个候选区域提取了4096维的特征向量。
第四步: 使用SVM进行分类。
我们使用训练好的SVM分类器为每一个提取的特征向量为每个类别都进行评分,然后给出图片中所有评分的区域。然后为每个类型执行一次非极大值抑制。
优缺点
优点: 检测速度比之前的检测方法快了很多
1)所有类别共享CNN参数,也就是说在计算中参数变少了,就会使计算更快,计算候选区域和区域特征所花费的时间分摊到所有类别上:GPU上为13s/image,CPU上为53s/image。
2)CNN提取的特征图维度小,只有4096,比UVA检测系统的360K小了很多。
缺点:
1)训练分多步:1.要对预训练的网络进行fine-tune;2.要为每一个类别分别训练一个SVM分类器;3.要单独使用Selective Search方法生成候选区域;4.要用regressors对框进行边框回归。
2)训练时间和空间消耗大:训练SVM和regressor时,需要将从图片中提取的特征图保存到硬盘中
3)测试时执行也比较慢,首先要生成候选区域,然后为每个候选区域分别计算特征值会存在大量的重复计算。
Fast R-CNN
论文
论文地址:https://arxiv.org/abs/1504.08083
主要思想
Fast R-CNN是在R-CNN和SPPNet的基础上发展而来的。使用了一些新的方法来加快训练和测试的速度同时又能够提上检测精度。上一章节中介绍了R-CNN的主要缺点,Fast R-CNN主要针对这些缺点来进行改进。
提出了端到端一个阶段的目标检测方法,替代了R-CNN的多阶段方法,为了实现单阶段的检测做了如下的改进:
- 将一个完整图片和一组Proposal作为输入,而不是R-CNN中通过Selective Search选出的候选区域作为输入。首先, 网络会对整张图片通过CNN网络提取特征图; 然后通过传入的Proposal坐标从计算的特征图中取出候选框。这样只进行一次特征提取不会像R-CNN那样重复计算每个候选区域的特征图。
- 新增了RoI pooling层解决Proposal大小不一致的问题
- 使用多任务的loss计算,整个网络在训练时的loss是分类和回归两个分支的和,当然会带上系数。
- 网络的CNN网络使用的是VGG16。
- 使用SVD分解加速检测
- 使用softmax替代SVM
计算过程
先来一张论文中的图:
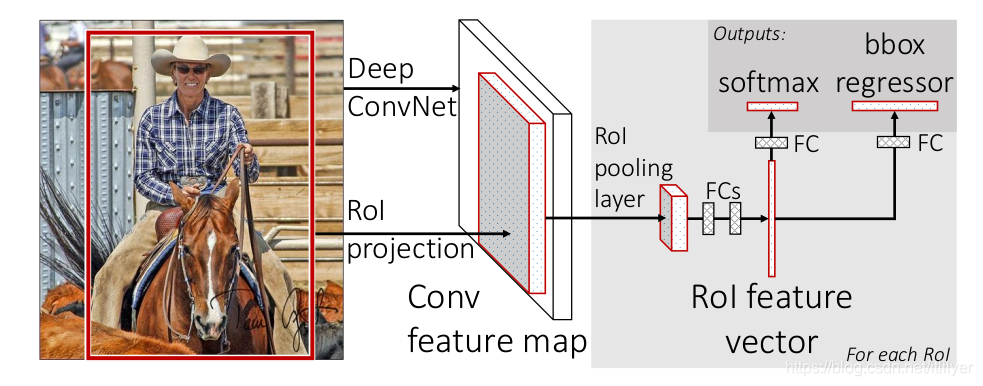 从图中可以看出
从图中可以看出
第一步: 使用Selective Search选出候选区域。
第二步: 将图片与第一步中选出的候选区域信息一起传给Fast R-CNN网络。
第三步: 通过VGG16网络提取图片的特征图
第四步: RoI pooling层将映射到特征图上的候选区域通过max Pool操作输出固定shape的特征图,具体计算过程在另一篇文章有介绍:https://blog.csdn.net/itlilyer/article/details/108666073
第五步: 得到固定大小的特征图后就可以给后面的全连接层,最后有两个分支:预测类别和边框回归。
优缺点
优点:。主要是与R-CNN和SPPNet相比
1)除了生成候选区域外可以实现端到端的流程打通,训练时间缩短,不会占用硬盘空间
2)不需要单独训练SVM和regressor。
3)共享权重,不需要重复计算每个候选区域的特征图。
**缺点: **
1)生成候选区域仍然使用的Selective Search,仍然会消耗很多的时间,称为了整个算法的瓶颈
Faster R-CNN
论文
论文地址: https://arxiv.org/abs/1506.01497
主要思想
Fast R-CNN和SPPNet暴露出生成候选区域成了目前目标检测网络的瓶颈。针对这个问题,作者提出了自己的解决方案——引入了RPN(Region Proposal Network)网络。
- 引入RPN网络替代Selective Search,解决生成候选区域的性能瓶颈。RPN的相关介绍可以参考:https://blog.csdn.net/itlilyer/article/details/109818142
- RPN和Fast R-CNN网络一起训练,共享CNN网络,将RPN和Fast R-CNN真正的合并成一个网络。
计算过程
照例,上图:
 第一步: 使用CNN网络(例如VGG16)来提取整张图片的feature map
第一步: 使用CNN网络(例如VGG16)来提取整张图片的feature map
第二步: 将特征图传入RPN网络, 生成RoI
第三步: 将第一步的Feature map和第二步的RoI传给后面的RoI pooling
第四步: 将RoI Pooling的结果传给全连接层
第五步: 全连接层的结果分别给bbox边框回归分支和softmax分类的分支
优缺点
优点:
1)当然第一个优点就是性能比以前的网络快(所有网络都是这样的吧:)),可以达到实时检测的标准
2)FPN和Fast R-CNN共享卷积层,可以端到端进行训练,
缺点:
- 经过RoI pooling后会出现misalignment的问题,但对于预测框影响不大,对于语义分割影响较大;同时RoI Pooling有一个bug,就是加入RoI的大小比RoI Pool的输出小的时候会被直接忽略掉。
Mask R-CNN
论文
论文地址:https://arxiv.org/abs/1703.06870
主要思想
maskrcnn的主体思路是在faster rcnn基础上增加一个实例分割的分支。那主要做了哪些改进呢?
1)用RoIAlign代替RoIPool,解决RoIpool的misalignment的问题,会影响分割的精度
计算过程
惯例,来张图:

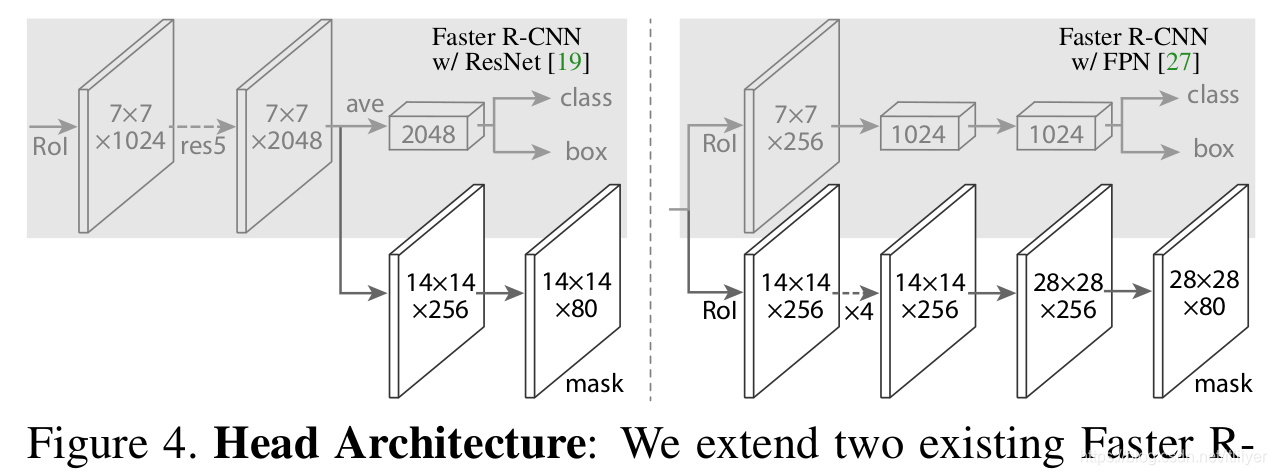
作者根据提取图片特征图的不同backbone和对每个RoI实现框预测和mask预测(第二个图)分了多种架构,这里我们以Resnet-FPN为backbone介绍。
第一步: 使用resnet50网络提取图片的特征图
第二步: 特征图经过FPN网络,输出多尺度的特征金子塔,作为RPN的输入
第三步: RPN使用特征金字塔生成RoI
第四步: 根据上图中的两种head 结构分别进行框的识别(分类和回归)和mask预测
优缺点
优点
- 使用RoIAlign代替RoIpool,提升了实例分割的精度,还解决了上面提到的bug