何恺明大神的Mask R-CNN获得ICCV最佳论文奖。Mask R-CNN通过扩展Faster R-CNN来实现实例分割,同时还可以用于人体关键点检测。
语义分割 VS 实例分割
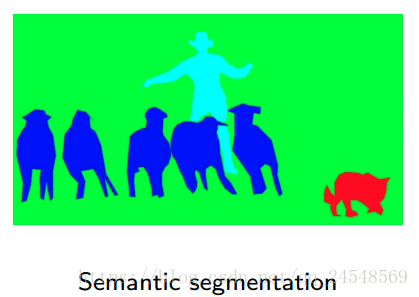
首先说说语义分割和实例分割的区别。语义分割是分割不同类别,而实例分割在分割类别的同时分割类别的实例,通过下面的图片来更好地理解二者的区别
实例分割比语义分割更难一些。

Mask R-CNN
Architecture
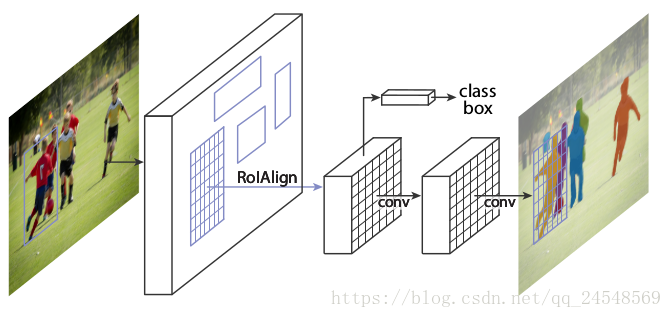
Mask R-CNN是基于Faster R-CNN的,它把Faster R-CNN的VGG换成能提取更好特征的ResNet,同时采用了FPN的特征金字塔模型。Mask R-CNN从RoI-Pooling层添加了一个mask分支,用于预测实例掩膜,这个mask是一个二值矩阵,用于表明这个RoI中哪些区域是实例,哪些不是。同时,为了避免misalignment问题,提高mask的预测精度,mask R-CNN把RoIPool换成RoIAlign。Mask R-CNN的简单结构如下图所示。
Head Architecture
Mask R-CNN的head有三个分支,如下图所示
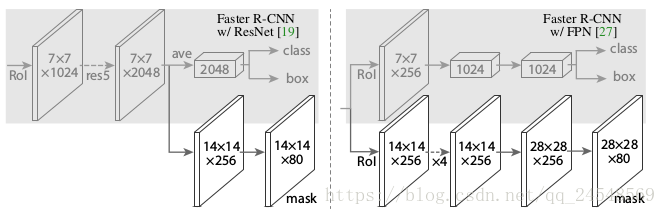
三个分支分别是class分支、box分支和mask分支。左边的表示使用ResNet作为网络的基础架构,RoI在ResNet的第4阶段后面,经过res5提取出RoI的特征,从这里开始分出两条分支,上面一条分支由于分类和bounding box回归,下面一条是mask分支。Mask分支首先进行向上采样提高feature map的空间分辨率,把通道数降到80。右边表示使用FPN作为网络的基础架构,res5在FPN中默认使用,所以在金字塔特征做分类和回归。下面的分支表示mask分支,虚线“×4”表示4次连续的卷积操作。这里Mask分支最后的feature map大小为28×28,比左边的更大,我也不知道为什么。
RoIAlign
Mask R-CNN成功的关键是RoIAlign,因为RoIAlign为RoI提供了更加精确的空间位置信息,使得Mask R-CNN的bounding box AP和mask AP比其他先进的网络更高。
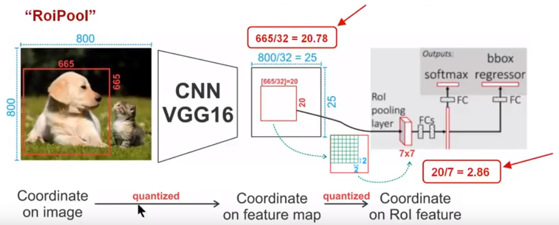
Fast(er) R-CNN使用的RoIPool对feature map进行了两次量化
第一次量化是把原图变为feature map,假设原图大小为800×800,图中狗的RoI大小为665×665,使用VGG16把原图缩小了32倍,那么feature map大小为
,同时RoI缩小为
,取RoI时不可能使用浮点数,因此需要取整,比如取20,这是第一次量化。这就产生了误差,如下图所示
对
进行向下取整导致原来的RoI平移以对齐feature map,从而造成误差。
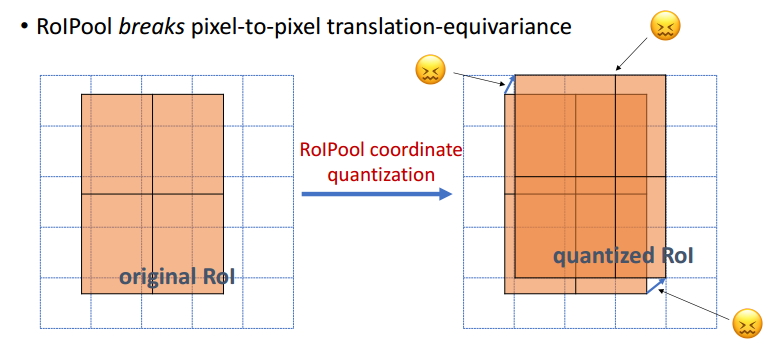
第二次量化是RoIPool把RoI的feature map转成固定大小(7×7)。现在RoI的feature map大小为20×20,要变成7×7要缩小 ,在这个过程中不可避免地有取整操作,因此这是第二次量化。
这两次量化过程会造成空间信息的丢失,比如第一次量化会产生 的像素误差。这两次量化过程引入misalignment问题,对bounding box预测和mask预测产生负面影响。
RoIAlign可以避免misalignment的影响。首先,对原图进行缩放时保留小数位,不进行取整,比如原图中的某个坐标x,卷积后缩小n倍,对应的坐标变为
,而不是
。接着的池化操作是这样的
上图虚线网格表示特征feature map,每个角表示一个feature map点。实线网格表示要提取的RoI,这个RoI网格分成4个bin,每个bin有4个采样点,采样点的数目可以是其他数字,但是文中说4个采样点是最好的。每个采样点的值由附近的feature map点通过双线性插值得到。然后再对每个bin的点进行max或average池化,得到bin的值。
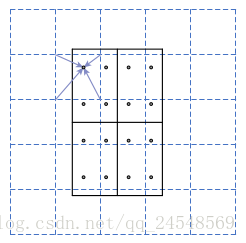
下面几幅图片1直观地展示了RoIAlign是如何实现的
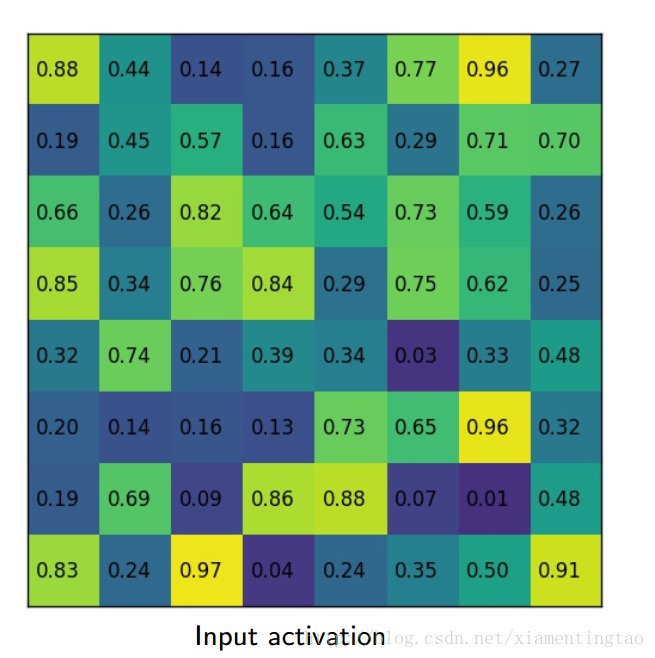
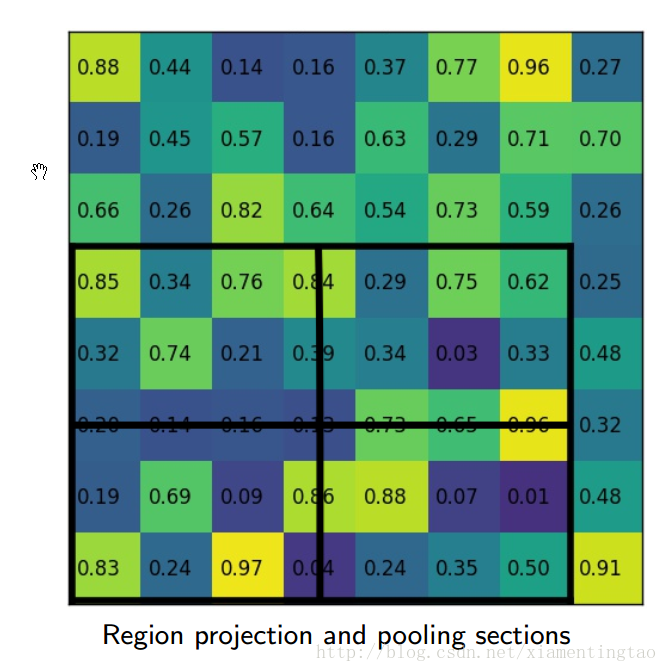
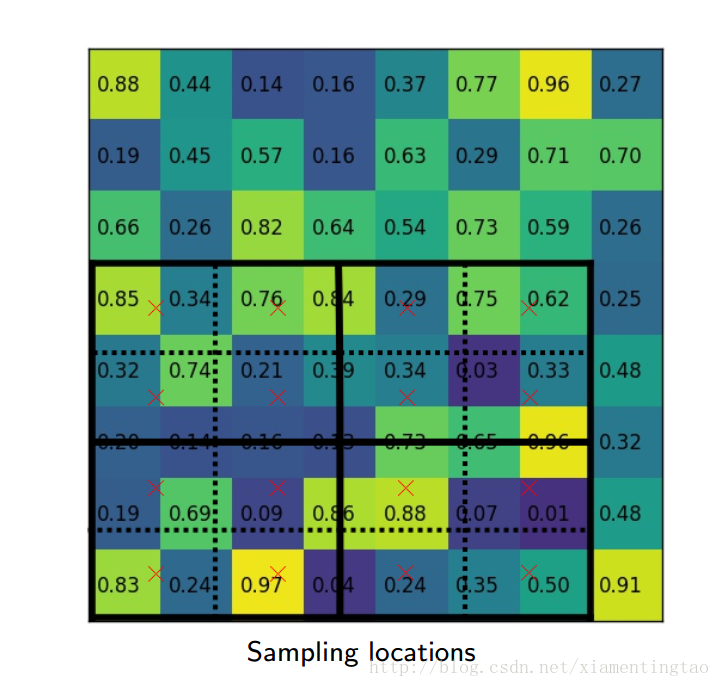
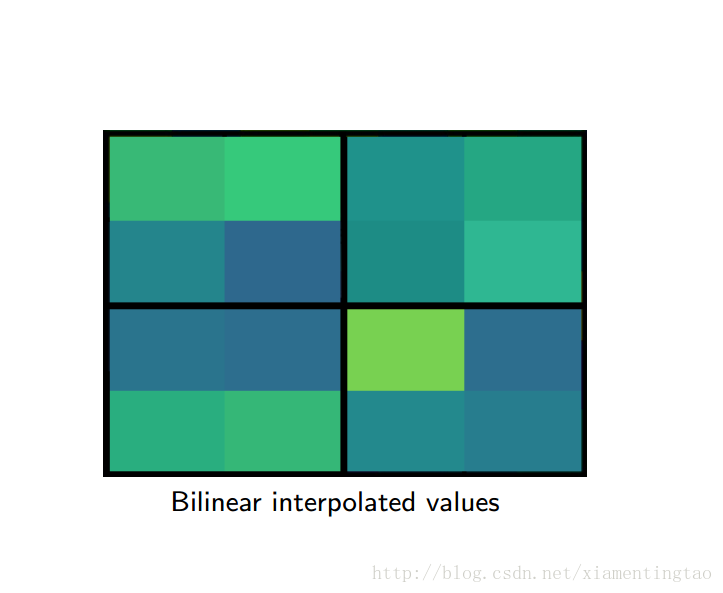
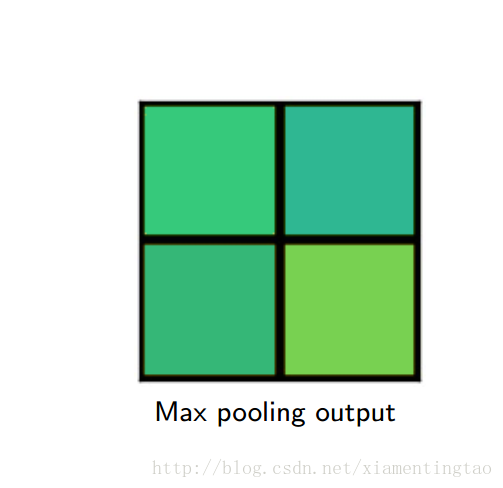
文中通过实验表明RoIAlign在mask R-CNN中其关键的作用
可以看到使用RoIAlign比使用RoIPool的AP更高。

Loss function
Mask R-CNN的损失函数是
其中
和
同Faster R-CNN。假设mask的大小为m×m,有k个类别,mask 分支最后输出长
的预测结果,每个值表示第k类的mask取1的概率。论文中使用per-piixel sigmoid,
取ground-truth class k的mask的平均二元交叉熵损失。
Result
最后看看mask R-CNN在COCO数据集中取得的成果。

