MASK R-CNN是何凯明大神之作,这里就自己的理解记录一下MASK R-CNN的简单流程,以便自己复习参考,如有错误望大家指正。
MASK R-CNN是由R-CNN, Fast R-CNN,Faster R-CNN进化而来的,具体每个算法的简单剖析可以参考
https://blog.csdn.net/jiongnima/article/details/79094159
在实例分割Mask R-CNN框架中,主要完成了三件事情:
1) 目标检测:直接在结果图上绘制了目标框(bounding box)。
2) 目标分类:对于每一个目标,需要找到对应的类别(class),区分到底是人,是车,还是其他类别。
3) 像素级目标分割:在每个目标中,需要在像素层面区分,什么是前景,什么是背景。
Mask R-CNN(区域卷积神经网络)框架分三部分:第一部分全图通过backbone网络提取特征图;第二部分扫描图像并生成proposals(可能包含对象的候选区域);第三部分对proposals进行分类并生成边界框和掩码。它是在Faster R-CNN的基础上添加了一个mask分支,对于每个ROI使用一个small FCN来完成像素级的分割的。
MASK R-CNN的整体框架如下图所示:
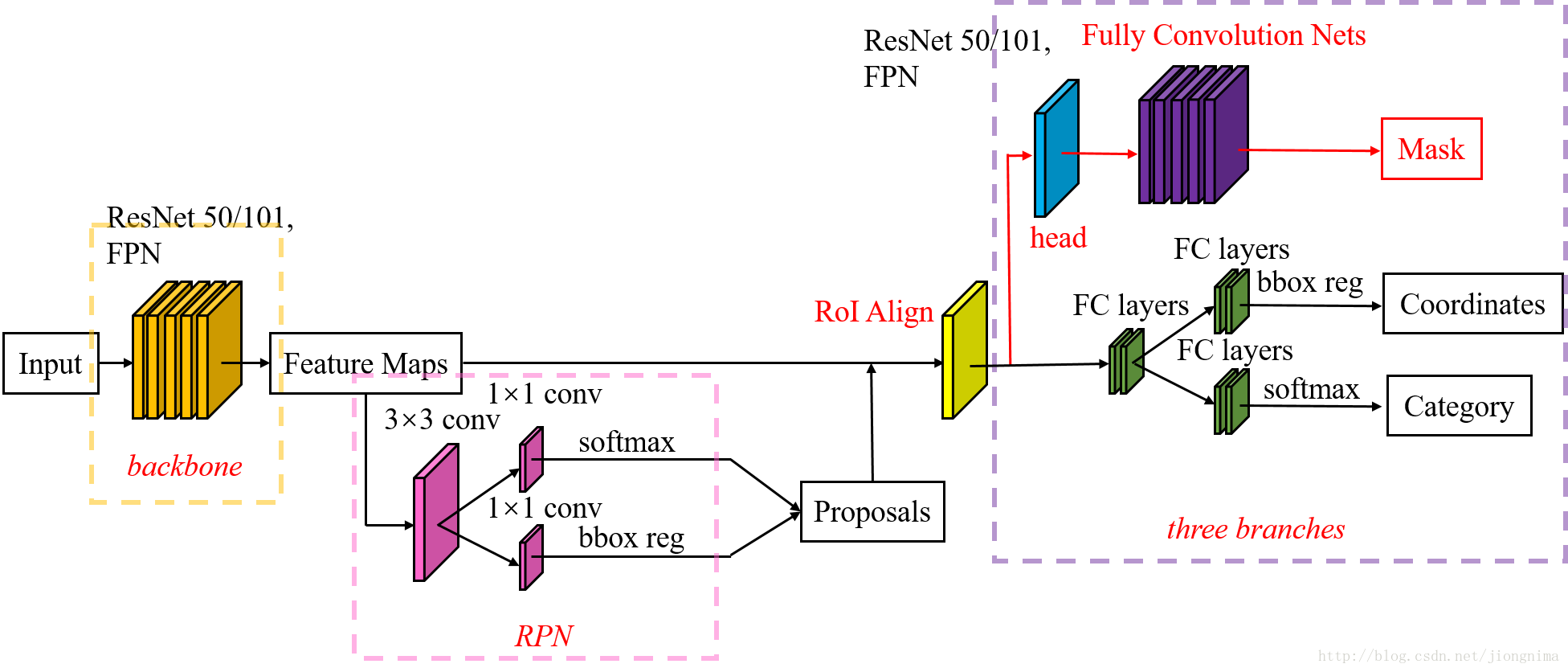
图片参考地址:https://blog.csdn.net/jiongnima/article/details/79094159
(1)使用一个CNN神经网络对全图提取特征
这是一个标准的卷积神经网络(通常是ResNet50或ResNet101),我们用它来提取特征。 较低层检测低级特征(边缘和角落),后续层检测更高级别的特征(汽车,人物,天空)。
(2)提取的特征图送入RPN,修正目标区域

RPN是一个轻量级的神经网络,以滑动窗口的方式扫描图像并找到包含对象的区域。在每个滑动窗口中都会有9种初始anchor包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1)。滑动窗口就是分布在图像区域上的红框,如上图所示。不过,这只是一个简化的视图。实际上,由于共享特征图的大小约为40×60,RPN生成的初始anchor的总数约为20000个(40×60×9)。对于生成的anchor,RPN要做的事情有两个,第一个是判断anchor到底是前景还是背景,意思就是判断这个anchor到底有没有覆盖目标;第二个是为属于前景的anchor进行第一次坐标修正。
RPN扫描速度有多快?其实很快。滑动窗口允许它并行扫描所有区域(在GPU上)。此外,RPN不会直接扫描图像(即使我们在图像上绘制锚点以便说明)。相反,RPN扫描骨干网络生成的Feature map。这允许RPN有效地重用提取的特征并避免大量的重复计算。根据Faster-RCNN的论文,RPN运行大约10 ms。在Mask RCNN中,我们通常使用更大的图像和更多的锚点,因此可能需要更长的时间。针对每个锚点,RPN有两个输出:

1.锚点的种类:前景或背景。前景类意味着该框中可能有一个对象。
2.边界框细化:前景锚点(也称为正锚点)可能没有完全正对该对象。 因此,RPN会输出一个很小的微量变化(百分比):(x, y, width, heigh),以更好地适应物体。
使用RPN预测,我们选择可能包含对象并优化其位置和大小的顶部锚点。如果几个锚点重叠太多,我们会保留具有最高前景分数的锚点并丢弃其余的(称为非极大值抑制:Non-max Suppression)。在这之后我们会得到进入下一阶段的最终提案(感兴趣的区)。
参考:https://blog.csdn.net/qq_15969343/article/details/80167215
(3)在Mask R-CNN中的RoI Align之后有一个"head"部分,主要作用是将RoI Align的输出维度扩大,这样在预测Mask时会更加精确。在Mask Branch的训练环节,作者没有采用FCN式的SoftmaxLoss,反而是输出了K个Mask预测图(为每一个类都输出一张),并采用average binary cross-entropy loss训练,当然在训练Mask branch的时候,输出的K个特征图中,也只是对应ground truth类别的那一个特征图对Mask loss有贡献。
anchor边框修正的训练方法和RoI Align的详细介绍见https://blog.csdn.net/jiongnima/article/details/79094159