
ICCV-2017

目录
1 Motivation
object detection and semantic segmentation 发展很快, 因为有 base system Faster R-CNN 和 FCN respectively,our goal in this work is to develop a comparably enabling(适应性广的) framework for instance segmentation.
instance segmentation 和 object detection 类似,都会涉及到区别同一类的不同个体
2 Innovation
Extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. 做到一个模型,三种用途 instance segmentation, bounding-box object detection, and person keypoint detection
提出了 RoIAlign 弥补 Faster R-CNN 的 end-to-end align for instance segmentation
3 Advantages
instance segmentation, bounding-box object detection, and person keypoint detection 三合一,且效果比各自单项冠军(2016 COCO)好
4 Methods
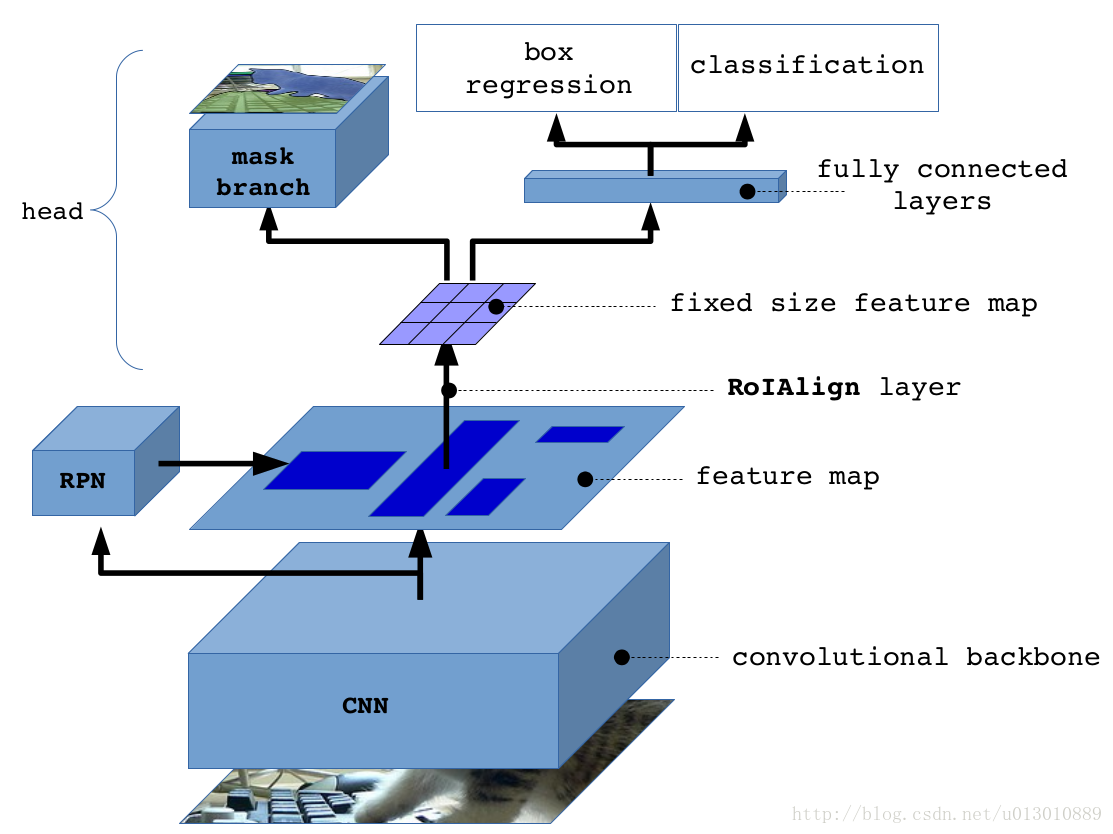
4.1 Head Architeture

左边的结构不好,R-FCN这边论文一开始就说了(this creates a deeper RoI-wise subnetwork that improves accuracy, at the cost of lower speed due to the unshared per-RoI computation. 类似RCNN的感觉,提出proposal后,对每个proposal进行后续处理),作者也推荐用右边的结构(we do not recommend using the C4 variant in practice)
Faster R-CNN has two outputs for each candidate object, a class label and a bounding-box offset,作者加了第三个 branch,让网络 output object mask. 但是 第三个 branch requiring extraction of much finer spatial layout of an object.
Mask R-CNN also outputs a binary mask for each RoI
4.2 RoI Align
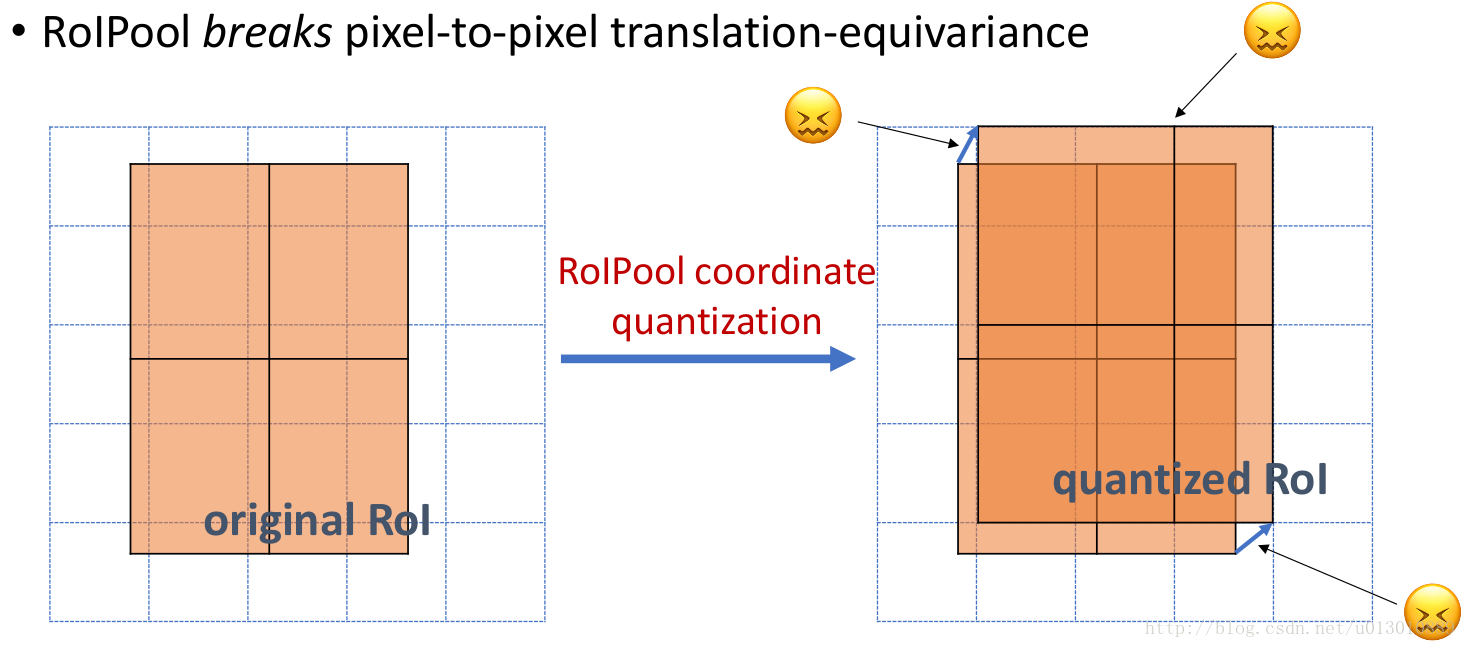
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐 ,两次量化,第一次 roi 映射 feature map 时,第二次 roi pooling 时 1
量化(quantization)如下
RoI pooling、warp、align 的区别如下:
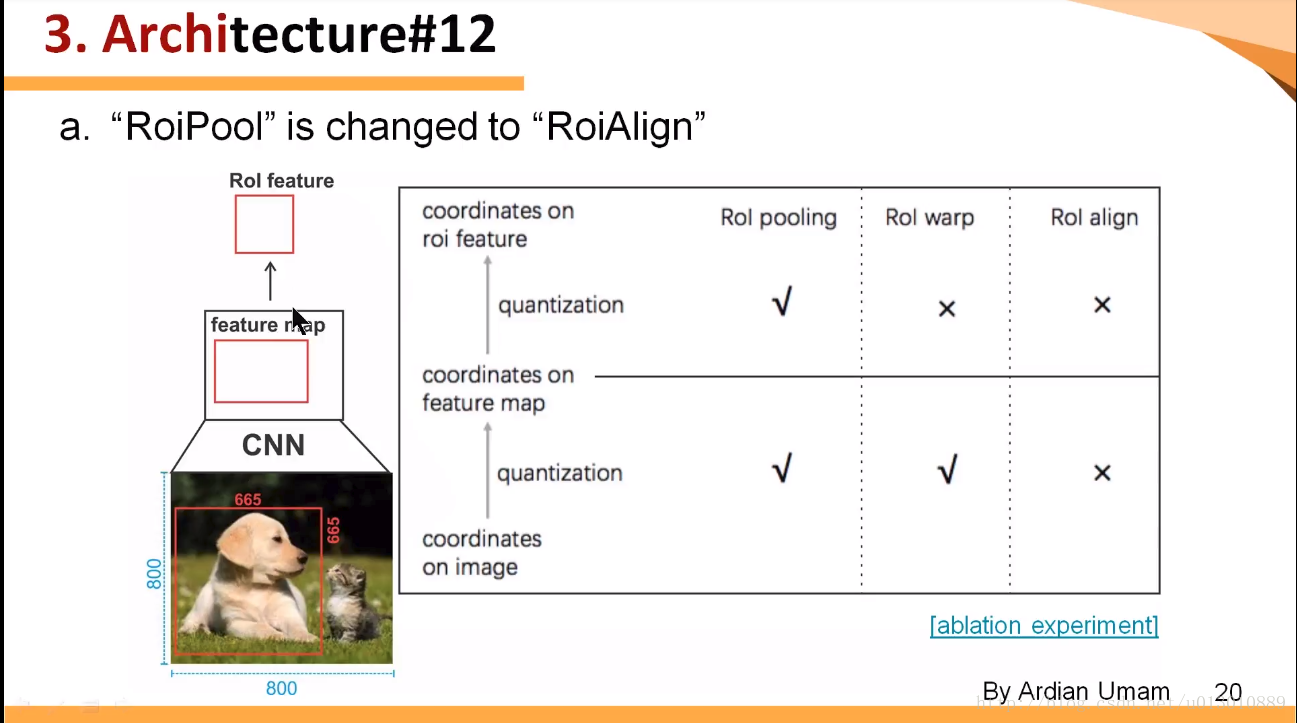
RoI Align 详解如下图中间部分

取非量化后 RoI 中的四个点,用双线性差值(周围四个像素点)确定其像素值,然后四个加起来求平均
4.3 Train
Multi-task loss: , is defined only on positive RoIs
mask branch has a dimensional output for each RoI,K classes and m×m resolution
- RoI 的 positive IoU at least 0.5 and negative otherwise
- 如同 fast rcnn 一样,采用 image-centric sampling 而不是 RoI centric sampling 来训练
- RoI-centric sampling:从所有图片的所有RoI中均匀取样,这样每个SGD的mini-batch中包含了不同图像中的样本。(SPPnet采用)
- image-centric sampling: (solution)mini-batch采用层次取样,先对图像取样,再对RoI取样,同一图像的RoI共享计算和内存2。
- Each mini-batch has 2 images per GPU and each image has N sampled RoIs,positive:negative = 1:3,N = 64 for C4 backbone and 512 for FPN(见图3)
- RPN anchors 5 scales and 3 aspect ratios
4.4 Inference
- Proposal = 300 for C4,and 1000 for FPN,然后丢到 box prediction branch, 接NMS
- Mask branch applied to the highest scoring 100 detection boxes,与训练的时候不同,但是加速
- Mask branch 能预测 K 个 masks per RoI,但是只用 k-th mask,k是 classification branch 的结果
- Mask 会 resize 到 RoI 的大小,二值化的 thresold 为0.5
5 Experiments:Instance Segmentation
evaluate using mask IoU
5.1 Main Results
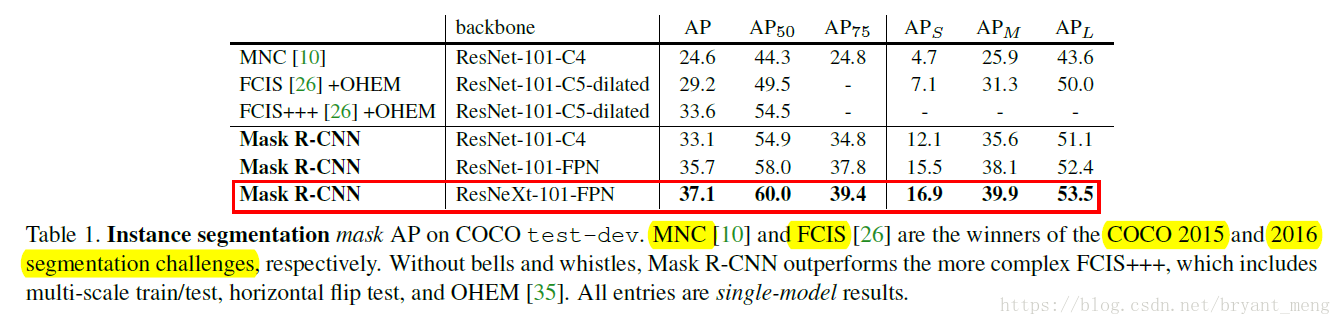
outperform COCO2015、2016的 instance segmentation 冠军

Mask RCNN VS FCIS,FCIS exhibits systematic artifacts on overlapping instances 而 Mask RCNN 没有。

5.2 Ablation Experiments
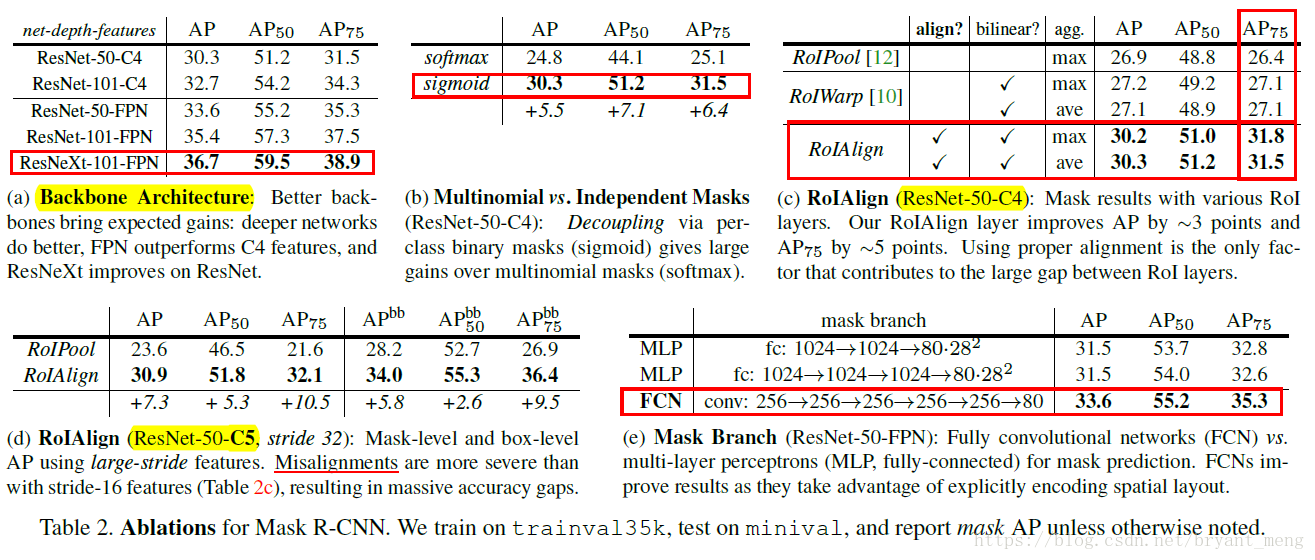
- Backbone:benefit from depth(50 vs 101),FPN and ResNeXt(表2 a)
- Multinomial vs Independent Masks:简单的说就是 sigmoid vs softmax,sigmod 是 class-specific 的,争对每一类,二分类,而 softmax 是 class- agnostic,争对每个像素, 用softmax 然后 multinomial logistic loss(表2 b,c)
- RoIAlign:对 max还是average pooling insensitive,所以作者都采用的是average pooling,相对 RoI pooling 效果有明显提升(表2 c,d),(c)的backbone 为 ResNet-50-C4,stride 为16,(d)中采用的是 ResNet-50-C5,stride 为 32,(d)比(c)的效果好,AP 30.9 vs 30.3,用FPN的话效果会进一步提升。
- Mask branch: FCN 比 MLP (FC)好
5.3 Bounding Box Detection Results
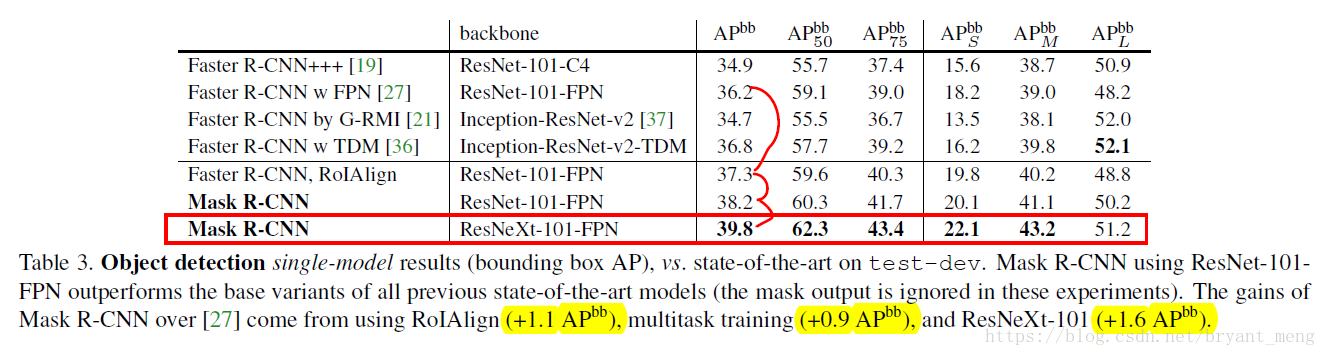
注意到 去掉mask 和 加上mask的区别在于,solely due to the benefits of multi-task training
table1 中, instance segmentation 的 AP 为 37.1
This indicates that our approach largely closes the gap between object detection and the more challenging instance segmentation task.
5.4 Timing
our design is not optimized for speed
Mask R-CNN for Human Pose Estimation 以及 Experiments on Cityscapes(instance segmentation)这篇博客就不在讨论了,有兴趣的可以去看下原文。