论文地址:https://arxiv.org/abs/1712.00726
文章内容:
-
论文总览
-
算法要点
-
双线性插值
论文总览:
Mask R-CNN是在Faster R-CNN基础上加了一个分支,来预测ROI的分割mask,是与分类和回归分支并列的分支。主要的一个改进是将ROI Pooling改为ROI Align,提升了mask的准确率。

算法要点:
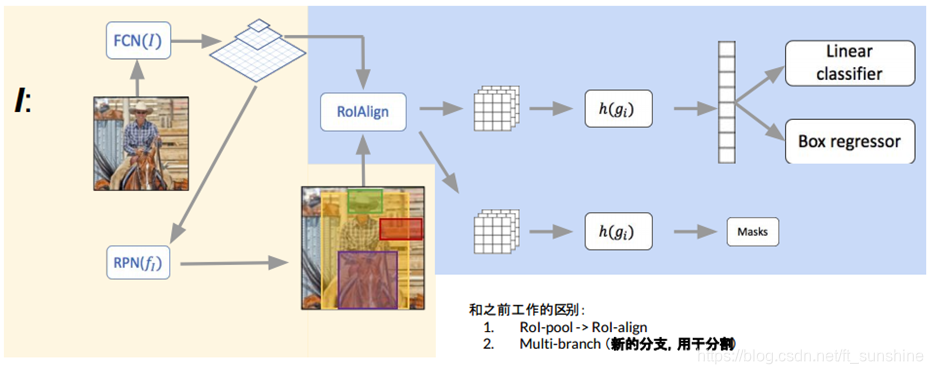
Mask R-CNN分两个阶段:第一阶段由RPN提出候选框,第二阶段是做分类、回归、分割。
Loss:
![]() 多任务损失函数
多任务损失函数
前两个损失函数与Faster R-CNN一样,L(mask)是平均二值交叉熵,分割分支对每个ROI会产生K*m*m个维的输出,在m*m分辨率上有K个二分类masks,每个像素点都应用了sigmoid,这样的好处是为每个类别都产生mask,不会在类别之间产生竞争,互不干涉。需要注意的是,计算loss的时候,并不是每个类别的sigmoid输出都计算二值交叉熵损失,而是该像素属于哪个类,哪个类的sigmoid输出才要计算损失。并且在测试的时候,是通过分类分支预测的类别来选择相应的mask预测。这样,mask预测和分类预测就彻底解耦了。
ROI Align:
Faster R-CNN存在的问题是:特征图与原始图像是不对准的(mis-alignment),所以会影响检测精度。而Mask R-CNN提出了RoIAlign的方法来取代ROI pooling,RoIAlign可以保留更精确的空间位置。
首先,我们为什么要用ROIAlign呢 ?
ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式,很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment) 的问题。
这两次量化分别为:
region proposal的x,y,w,hx, y, w, hx,y,w,h通常是小数,但是为了方便操作会把它整数化。
将整数化后的边界区域平均分割成k×k个单元,对每一个单元的边界进行整数化。
两次整数化(量化)的过程如下图所示:(图片来自知乎文章)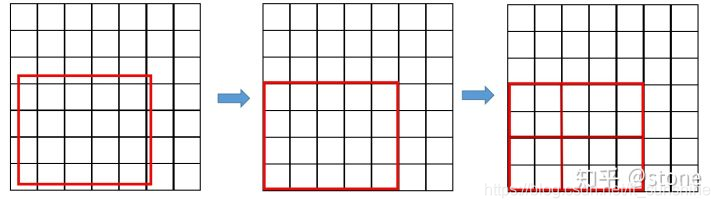
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为 “不匹配问题(mis-alignment)。
为了解决这个问题,ROI Align方法取消整数化操作,保留了小数,使用双线性插值的方法获得坐标为浮点数的像素点的数值。但在实际操作中,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后进行池化,而是重新进行设计。 下面我们通过两个例子来说明:

例子1
如下图所示,虚线部分表示feature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。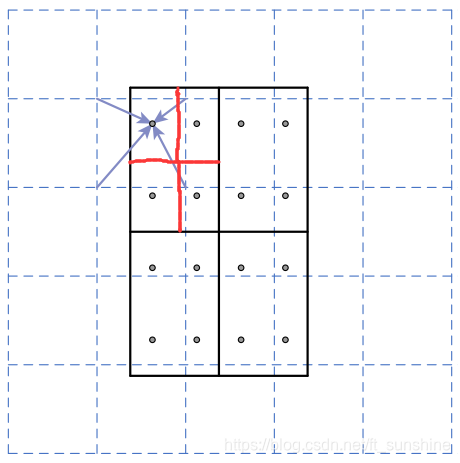
需要说明的是,在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。
例子2
下面我们再通过一个更直观的例子具体分析一下上述区域不匹配问题,如下图所示: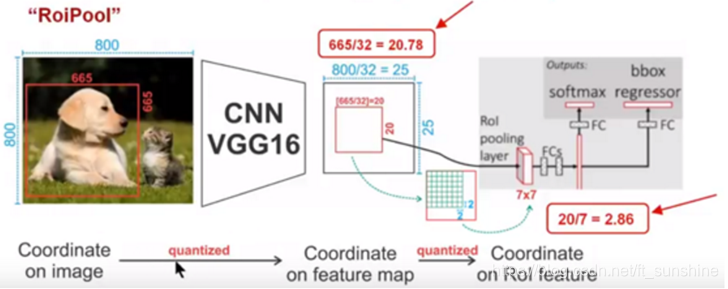
如上图所示,这是一个Faster-RCNN检测框架。输入一张800∗800的图片,图片上有一个665∗665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数。于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化为7∗7的大小,因此将上述包围框平均分割成7∗7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。如下:
ROI Align操作如下:
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k×k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题
ROI Align 的反向传播
常规的ROI Pooling的反向传播公式如下:
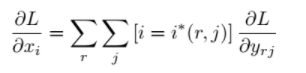
这里,xi代表池化前特征图上的像素点;yrj代表池化后的第r个候选区域的第j个点;i*(r,j)代表点yrj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点Xi的像素值(即满足i=i*(r,j)),才在xi处回传梯度。
类比于ROIPooling,ROIAlign的反向传播需要作出稍许修改:首先,在ROIAlign中,xi*(r,j)是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 xi*(r,j) 横纵坐标均小于1的点都应该接受与此对应的点yrj回传的梯度,故ROI Align 的反向传播公式如下:
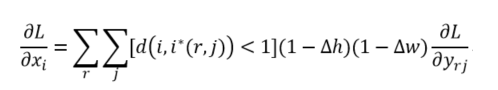
上式中,d(.)表示两点之间的距离,Δh和Δw表示 xi 与 xi*(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。
双线性插值:
为什么要用双线性插值法
在图像的放大和缩小的过程中,需要计算新图像像素点在原图的位置,如果计算的位置不是整数,就需要用到图像的内插,我们需要寻找在原图中最近得像素点赋值给新的像素点,这种方法很简单是最近邻插法,这种方法好理解、简单,但是不实用,会产生是真现象,产生棋盘格效应,更实用的方法就是双线性插值法。
一维线性插值
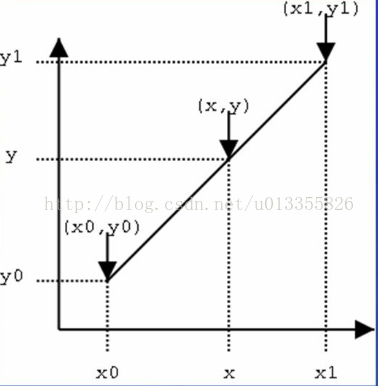
我们已经知道(x0,y0)与(x1, y1)的值,并且已知 x 的值,要求 y 的值。根据初中的知识:
我们可以得到: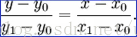
令:

则:
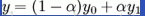
双线性插值法的推导过程
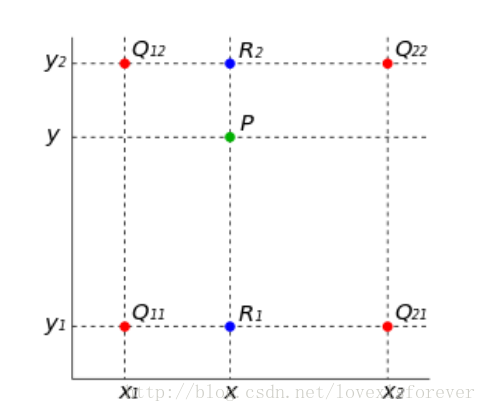
双线性插值是做了二次一维的线性插值,我们用四个最近邻估计给定的灰度。
计算方法
首先,在X方向上进行两次线性插值计算,然后在Y方向上进行一次插值计算。
在图像处理的时候,我们先根据
srcX=dstX* (srcWidth/dstWidth),
srcY = dstY * (srcHeight/dstHeight)
来计算目标像素在源图像中的位置,这里计算的srcX和srcY一般都是浮点数,比如f(1.2, 3.4)这个像素点是虚拟存在的,先找到与它临近的四个实际存在的像素点
(1,3) (2,3)
(1,4) (2,4)
写成f(i+u,j+v)的形式,则u=0.2,v=0.4, i=1, j=3
在沿着X方向差插值时,f(R1)=u(f(Q21)-f(Q11))+f(Q11)
沿着Y方向同理计算。
或者,直接整理一步计算,
f(i+u,j+v) = (1-u)(1-v)f(i,j) + (1-u)vf(i,j+1) + u(1-v)f(i+1,j) + uvf(i+1,j+1)
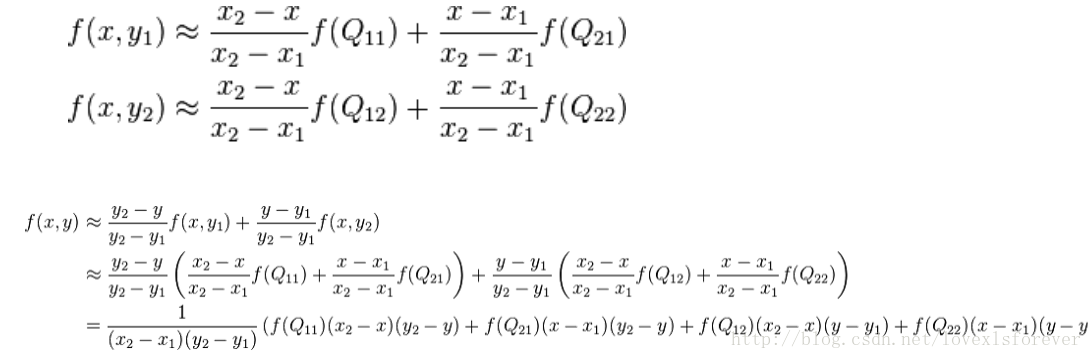
https://blog.csdn.net/u011918382/article/details/79455407
https://blog.csdn.net/qq_37577735/article/details/80041586(双线性插值法)
