1. Introduction
In principle Mask R-CNN is an intuitive extension ofFaster R-CNN, yet constructing the mask branch properlyis critical for good results. Most importantly, Faster RCNNwas not designed for pixel-to-pixel alignment betweennetwork inputs and outputs. This is most evident inhow RoIPool [18, 12], the de facto core operation for attendingto instances, performs coarse spatial quantizationfor feature extraction. To fix the misalignment, we proposea simple, quantization-free layer, called RoIAlign, thatfaithfully preserves exact spatial locations. Despite being a seemingly minor change, RoIAlign has a large impact: itimproves mask accuracy by relative 10% to 50%, showingbigger gains under stricter localization metrics. Second, wefound it essential to decouple mask and class prediction: wepredict a binary mask for each class independently, withoutcompetition among classes, and rely on the network’s RoIclassification branch to predict the category. In contrast,FCNs usually perform per-pixel multi-class categorization,which couples segmentation and classification, and basedon our experiments works poorly for instance segmentation.
- Mask R-CNN是在Faster R-CNN 的基础上增加一个分支。
- Faster R-CNN不是为了pixel - to - pixel 预测,Faster R-CNN中使用RoIPool 提取空间的特征是非常粗糙的。为了(fix the mislignment, 文章提出了RoIAlign 保留精确的空间位置信息。
RoIAlign 的影响:
(1)提高mask accuracy 10%-50%。
(2)分离了mask 和类别的预测,文章用一个“二值mask”,在同一类中预测这个是否属于这类(不需要进行类别中竞争),之后,依据RoI分类的分支预测类别。
(3)相反,FCNs通常在每个像素水平上进行多类别预测(multi-class categorization),将segmentation和classfication联合起来了。但是这样对于instance segmentation 的预测结果不好。
Without bells and whistles, Mask R-CNN surpasses allprevious state-of-the-art single-model results on the COCOinstance segmentation task [28], including the heavilyengineeredentries from the 2016 competition winner. Asa by-product, our method also excels on the COCO objectdetection task. In ablation experiments, we evaluate multiplebasic instantiations, which allows us to demonstrate itsrobustness and analyze the effects of core factors.Our models can run at about 200ms per frame on a GPU,and training on COCO takes one to two days on a single8-GPU machine. We believe the fast train and test speeds,together with the framework’s flexibility and accuracy, willbenefit and ease future research on instance segmentation.Finally, we showcase the generality of our frameworkvia the task of human pose estimation on the COCO keypointdataset [28]. By viewing each key point as a one-hotbinary mask, with minimal modification Mask R-CNN canbe applied to detect instance-specific poses. Mask R-CNN surpasses the winner of the 2016 COCO keypoint competition,and at the same time runs at 5 fps. Mask R-CNN,therefore, can be seen more broadly as a flexible frameworkfor instance-level recognition and can be readily extended to more complex tasks.We have released code to facilitate future research.
2. Related Work
R-CNN: The Region-based CNN (R-CNN) approach [13]to bounding-box object detection is to attend to a manageablenumber of candidate object regions [42, 20] and evaluateconvolutional networks [25, 24] independently on eachRoI. R-CNN was extended [18, 12] to allow attending toRoIs on feature maps using RoIPool, leading to fast speedand better accuracy. Faster R-CNN [36] advanced thisstream by learning the attention mechanism with a RegionProposal Network (RPN). Faster R-CNN is flexible and robustto many follow-up improvements (e.g., [38, 27, 21]),and is the current leading framework in several benchmarks.
1. R-CNN
R-CNN(the region-based cnn)用bounding-box检测目标候选区域,在独立的RoI中进行评估。Fast, Faster RCNN都是在RCNN基础上进行改造的。
2. Instance Segmentation
3. MASK RCNN
Faster RCNN的每个候选目标有两个输出,一个是分类的label,另一个是bounding-box的offset。MASK RCNN增加了第三个分支,输出目标mask, 比Faster R-CNN更加精细
Faster RCNN:
stage1:RPN提出候选目标的bounding-box,
stage2:从每个候选bounding-box中,用RoIPool提取特征,并进行分类和bounding-box回归。结构如下图所示。【21】https://arxiv.org/pdf/1611.10012.pdf 该文章有关于Faster RCNN和其他框架的比较
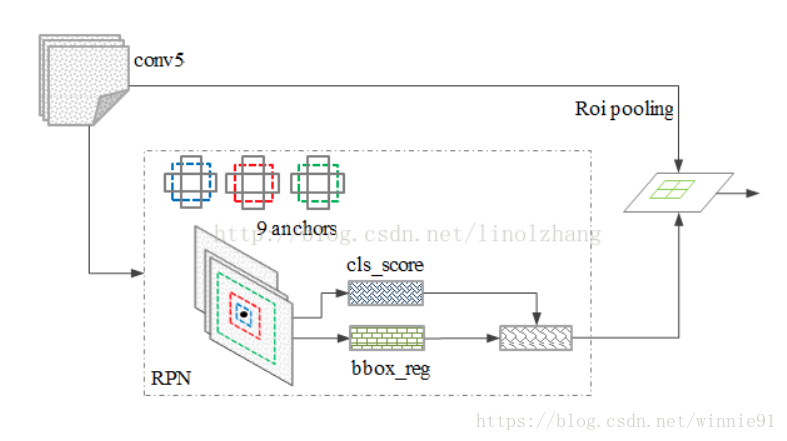

Mask RCNN
stage1,2 与faster RCNN一致,只是在stage2 (预测class 和box offset)的同时,Mask RCNN 对每一个RoI输出二值Mask。这个和现在多数的系统不太一样,多数的系统中,分类是给予mask的received的【33,10,26】。
每一个抽样RoI的malti-task loss: L= L(cls)+L(box)+L(mask)。L(cls)和L(box)的定义和fast RCNN中的一致。mask 分支对每一个RoI的输出维度是Km^2,K个masks(类别)分辨率m×m。这里采用per-pixel sigmoid,定义L(mask)是average binary cross-entropy loss。当一个RoI和真实值k-class进行比较时,Lmask是只受k-thmask影响的,k个masks之间互相不影响。
由此看出,Lmask的定义可以 让network产生每个类的masks,这些类别之间互相不竞争。文章依据专用的分类分支进行预测类别并选择输出的mask。这就让mask 和class 预测分离了呢。和FCNs相比较,有大大的不同,FCNs中,对每一个像素用softmax进行分类,比如有K个类,那就会把这个像素点分成0,1,2,3...K个值,并用multinominal (多项)cross-entropy loss进行loss 的计算。FCNs中masks cross classes compete。在该文章中,每个像素sigmoid用binary loss进行计算。
MASK Rrepresatation
MASK对输入的物体进行空间框架输出(encodes)。所以,不像class labels或者box offsets一样将目标输出成向量,mask可以提取空间结构pixel to pixel级别的。
从每个RoI中,用FCN预测m×m mask。这就使得mask分支的每一层都可以得到明确的m×m目标空间框架,不需要折叠成vector(我猜这个向量是二维的,所以没有空间信息),向量就缺少空间维度了。
这种pixel-to-pixel 行为需要RoI特征(RoI特征是一个非常小的特征图)能够和每个对应像素的空间对应。所以有了RoIAlign。
RoIAlign:
RoIPool是从每个RoI提取小特征图的标准操作。RoIPool首先将一个RoI浮点数量化成特征图的离散值,采用maxpool进行特征提取。打个比方:在一个连续的坐标x上,计算 [x/16],16是特征图的stride,[.]四舍五入。量化就是:将其细分成bins(比如7*7)。具体的RoI原理:https://blog.csdn.net/lanran2/article/details/60143861。为什么除以stride看这里:https://www.cnblogs.com/soulmate1023/p/5557161.html 。这种量化方法在RoI和提取的特征中,会产生misalignments。
这里引用一段别人的描述:https://blog.csdn.net/diligent_321/article/details/78397693
(1)RPN网络中的regression分支预测出候选区域的坐标,由RPN网络的损失函数可以看出,预测坐标的值是相对于输入图像尺寸而言的,而且预测坐标是浮点值,所以要进行取整操作才能得到候选区域,文章中用的是”quantize”,其实就是取整运算;
(2)将RoI划分成一些容器(bins),然后分别对每一个容器中的像素进行max pooling操作,但是在划分容器的时候,比如将RoI划分成7×7的大网格时,如果RoI的长宽不是7的倍数的话,就会存在四舍五入的运算,所以这里也有量化操作。
那么问题来了,上面的两个量化对模型有什么影响呢?对于分类和回归任务而言,自然是没有什么影响的,但是对于segmentation任务而言,由于输出图像中的像素是对输入图像分割的结果,所以像素之间要存在一一映射关系,不能有上面的取整运算。我们设想一下,假设在输出mask图之前进行了取整操作,那么输出图中的某些像素必然不能对应到真实的groundtruth了,那么肯定会影响图像分割的准确性。
所以提出了RoIAlign layer。移除了RoI边缘或bins的量化环节(采用x/16代替[x/16]),文章采用bilinear interpolation 双线性插值法来计算在特征图中每一个个RoI bin中的4个固定采样点的值,并整合四个采样点的值得到结果(max或者average)。如下图所示:虚线网格表示特征图,实线是一个RoI(2*2bin),黑点表示4个采样点。RoIAlign就是采用使用附近的特征图上的四个网格上的值进行双线性插值计算每个采样点。没有任何量化。

Network Architecture
在(i)convolutional backbone 用来提取整副图特征的网络结构和(ii)用来bounding-box识别的head网络结构里分别用了mask 预测。
在ResNet和ResNeXt上都做了测试。用network-depth-feature命名backbone结构。ResNet有50层。Faster-R-CNN 是用ResNets在最后的convolutional层的4th阶段提取特征的,这里命名为C4。那么这个backbone就叫 ResNet-50-C4
head网络,我们遵循之前的Faster RCNN的结构,增加了一个平行mask运作。
3.1 Implementation details
文章设置了超参
training: IoU>0.5 那么这个RoI是positive的。Lmask只有positive RoI上有定义。mask target 是RoI和真实mask的交集。文章采用中心图片训练(image-centric)training。图片resized to 800 pixels,每个mini-batch有两张图,一个GPU。每张图有N个采样RoIs,positive的量和negative比值是1:3(不知道这个怎么推出来的)。在C4 backbone中,N=64,FPN中N= 512。我们在8个GPUs上训练(mini-batch size = 16)160k iterations,learning= rate =0.02,在120k iteration时下降到10。weight decay = 0.0001 ,momentum = 0.9。
RPN anchors 5个尺度,3 种长宽比,RPN是单独训练的,没有和Mask RCNN共享特征,除非另有规定。本文中,他们是共享的。
先写到这,后续会分析代码