如有错误,恳请指出。
文章目录
paper:Mask R-CNN
作者:Kaiming He

摘要:
其实,这篇论文中,作者是设计用来解决对象实例分割问题的,所以文章的名字可能起得不算很好,请多包含。但是在Mask R-CNN算法中,可以有效的检测出图像中的对象,同时为每个实例生成高质量的分割掩码。
Mask R-CNN是在Faster R-CNN基础上进行拓展,通过增加一个预测对象掩码的分支,与现有的边界框回归分支并行。其甚至可以处理实例分割任务,目标检测任务,人体关节检测任务。
1. Introduction
作者在这项工作中的目标是为实例分割开发一个相对可行的框架。实例分割任务需要正确检测图像中的所有对象,同时还需要精确分割每个实例。因此,实例分割任务结合了目标检测与语义分割两大任务。前者是对单个对象进行分类,并使用边界框对每个对象进行定位。后者是将每个像素分类到一组固定的类别中,而不区分对象实例,也就是相同类别的内容用同一种像素点表示即可。
Mask R-CNN结果如图所示:
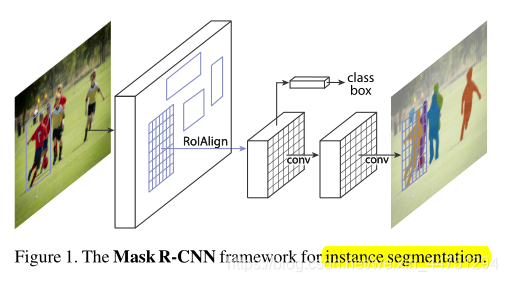
Mask R-CNN是Faster R-CNN的扩展版本,添加一个分支用于对每个感兴趣区域(RoI)进行预测分割掩码,与用于分类和包围盒回归的现有分支并行。这个mask分支由全卷积网络组成,以逐像素点(pixel-to-pixel)的方式对每一个感兴趣区域RoI预测分割掩码。
以上是一个比较直观的结构展示,正确构建掩码分支对于良好的结果至关重要。最重要的是,Faster RCNN不是为网络输入和输出之间的pixel-to-pixel对齐而设计的。这在用于处理实例的实际核心操作RoIPool时,如何执行特征提取的粗略空间量化中最为明显。为了修复错位,作者提出了一个简单的无量化层,称为RoIAlign,它忠实地保留了精确的空间位置。
其次,作者发现将掩码和类预测解耦至关重要。为此,作者独立地为每个类预测一个二进制掩码,类之间没有竞争,并依靠网络的RoI分类分支来预测类别。相比之下,FCNs通常执行每像素进行多类别分类,将分割和分类结合起来,基于实验这对于实例分割效果不佳。
2. Related Work
在RCNN有效性的驱动下,许多实例分割方法都是基于分割建议的(segment proposals)。早期的方法采用自下而上的分割。DeepMask和一些后续研究提出细分候选(segment candidates),然后由Fast R-CNN进行分类。在这些方法中,分割先于识别,这是缓慢且不太准确的。类似地,还有人提出了一种复杂的多级级联,该级联从包围盒候选框中预测分割候选框,然后进行分类。而在Mask R-CNN中,则是基于并行掩码预测与类标签预测,更简单且更灵活。
还有学者将某研究成果中的分割候选系统与目标检测系统结合起来,实现全卷积实例分割“fully convolutional instance segmentation” (FCIS)。其想法是由全卷积网络对一组位置敏感进行预测并输出一组channels,这些channels同时处理对象类、回归框和掩码,使系统速度更快。但是FCIS在重叠实例上表现出系统误差,并产生虚假边缘,表明它受到分割实例的根本困难的挑战。
实例分割的另一系列解决方案是由语义分割的成功驱动的。从每像素分类结果开始,这些方法试图将同一类别的像素切割成不同的实例。与这些方法的分段优先策略(segmentation-first strategy)相反,Mask R-CNN基于实例优先策略(instance-first strategy)。
3. Mask R-CNN
Mask R-CNN在概念上很简单:Faster R-CNN对每个候选对象都有两个输出,一个类标签和一个边界框偏移量,对此作者添加了第三个分支来输出对象掩码。但是额外的掩码输出不同于实例对象类标签和回归框输出,需要提取对象的更精细的空间布局。对于Faster R-CNN,其主要的缺失部分是pixel-to-pixel对齐。
3.1 Faster R-CNN
首先回顾一些Faster R-CNN结构。其包含两个步骤:
1)第一阶段称为区域建议网络(Region Proposal Network,RPN),提出候选对象边界框。
2)第二阶段本质上是Fast R-CNN,使用RoIPool从每个候选框中提取特征,并执行分类和包围盒回归。
两个阶段使用的特征可以共享,以便更快地推断。
详细的Faster R-CNN结构介绍,可以参考我另一篇笔记:目标检测算法——Faster R-CNN
3.2 Mask R-CNN
Mask R-CNN采用相同的两阶段程序:第一阶段相同(即RPN)。在第二阶段,在预测类和边界框偏移的同时,Mask R-CNN还为每个RoI输出一个二进制掩码。这与其他系统中分类依赖于掩码预测形成对比。Mask R-CNN遵循着Faster R-CNN的思想,并行应用包围盒分类和回归,在很大程度上简化了原始的 R-CNN多级处理流程。
在训练期间,我们将每个采样RoI的多任务损失定义为 L L L,公式如下:
L = L c l s + L b o x + L m a s k L = L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask
其中,分类损失 L c l s L_{cls} Lcls与回归损失 L b o x L_{box} Lbox与Fast RCNN的定义完全相同。掩码分支对每个RoI都有一个 K × M 2 K \times M^{2} K×M2维输出,它对分辨率为 m × m m × m m×m的 K K K个二进制掩码进行编码,其中 K K K表示总类别数。对此,对每像素应用sigmoid,并定义 L m a s k L_{mask} Lmask为平均二进制交叉熵损失。假如一个RoI对应着实例对象的第 k k k类,那么 L m a s k L_{mask} Lmask只针对第 k k k层掩码作计算输出,其他层的掩码输出不会造成任务损失,也就是与计算无关。
作者对 L m a s k L_{mask} Lmask的定义允许网络为每个类生成掩码,而没有类之间的竞争。依靠专用的分类分支来预测用于选择输出掩码的类标签,这将掩码和类预测解耦。这与将FCNs应用于语义分割时的常见做法不同,后者通常使用每像素softmax和多项式交叉熵损失,这样就会导致跨阶层的分类与掩码分类具有竞争性。这一步的改变对获得良好的效果比较关键,尤其需要注意。
3.3 Mask Representation
遮罩对输入对象的空间布局进行编码。因此,与类别标签或边界框偏移不可避免地被全连接层折叠成短输出向量不同,提取掩码的空间结构可以自然地通过卷积提供的pixel-to-pixel的对应来解决。
具体来说,作者对每一个RoI使用FCN来预测一个分辨率大小为 m × m m \times m m×m的掩码。这允许掩码分支中的每个层保持显式的 m × m m × m m×m对象空间布局,而不会将其折叠为缺少空间维度的矢量表示。不像以前的方法使用全连接层的掩码预测,Mask R-CNN使用全卷积表示需要更少的参数,更准确的实验证明。
对于处理后得到的RoI来说,是一个尺度比较小的特征图。而pixel-to-pixel的方式要求RoI特征能够很好的对齐,以清晰地保持每像素的明确空间对应。这促使作者开发了以下在掩码预测中起关键作用的RoIAlign层。
3.4 RoIAlign
在Faster RCNN中,RoIPool是将提取出的RoI进行统一池化为7x7尺度大小特征图的标准操作。RoIPool首先将一个浮点数RoI量化为特征图的离散粒度,然后将这个量化的RoI细分为空间仓,这些空间仓本身被量化,最后聚合每个仓覆盖的特征值(通常通过max pooling)。简单的说,RoIPool就是将 w × h w \times h w×h的特征图,统一标准地池化为7x7大小的结果。这些量化在RoI和提取的特征之间引入了不对准。虽然这可能不会影响分类,分类对于小的转换是稳健的,但是它对预测像素精确的掩码有很大的负面影响。
为了解决这个问题,作者提出了一个RoIAlign层,它消除了RoIPool的苛刻量化,将提取的特征与输入适当对齐。作者避免对RoI边界或面元进行任何量化(即使用x/16而不是[x/16]),然后使用双线性插值计算每个RoI bin中四个规则采样位置的输入特征的精确值,并汇总结果(使用最大值或平均值)。
对于RPN网络输出的RoI,一般是会在特征图上进行了些许偏移如实现框所示,这个偏移的边界框同样会包含多个特征点。我的理解是,一般在对原目标映射在特征图上时会出现浮点数坐标,如图所示:
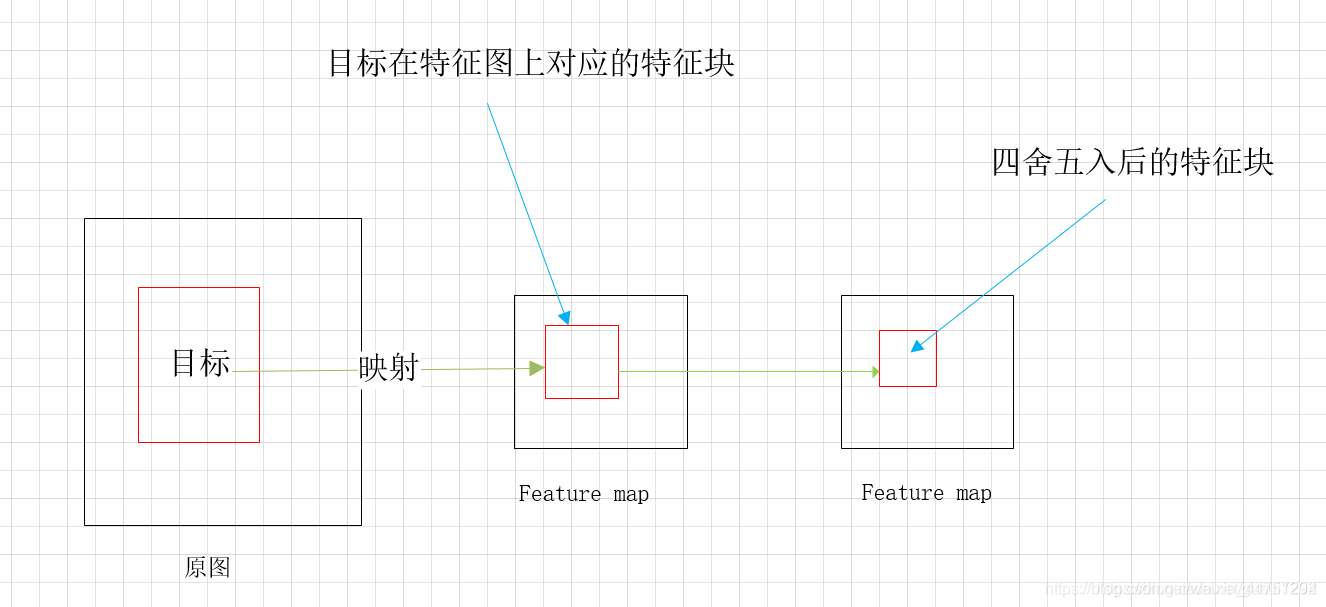
(图片来源于https://blog.csdn.net/gusui7202/article/details/84799535)
由上可以看到,由于偏移后的边界框与RoI区域,一般都是随机性的,所以划分为kxk个bin的时候不一定能够整除,如图所示:
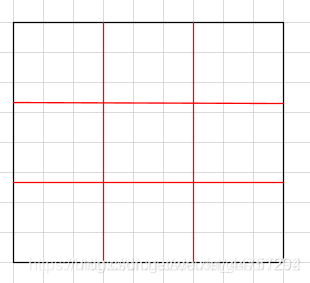
(图片来源于https://blog.csdn.net/gusui7202/article/details/84799535)
对于量化严重的RoIpool可能会进行如下所示的操作:
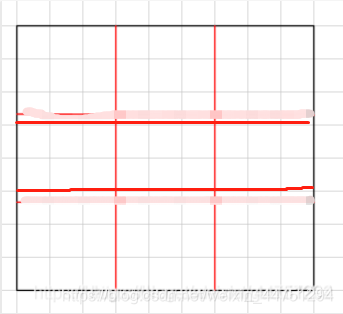
这样就会出现量化误差,RoIAlign所做的其实很简单,只是保持原有的分区不变,而对于浮点坐标只是进行双线性插值进行处理而已。使得可以对分区进行均匀区分。而在池化时,提取出每个区域的中心点,使用双线性插值就可以得到此时区域的值。9个Bin格,9个中心点,9个特征值。
而作者注意到,只要不执行量化,结果对精确的采样位置或采样多少点不敏感。所以,也就是,不需要对每个区域的中心值进行采样,其他位置也可以,关键就是要不进行量化操作即可。在作者原文中,就使用双线性插值计算每个RoI bin中四个规则采样位置的输入特征的精确值,并汇总结果(使用最大值或平均值),如图所示:

RoIAlign带来了很大的改进,这证明了对齐的关键作用。
3.5 Network Architecture
Mask R-CNN的结构为:
1)卷积主干架构用于整个图像的特征提取。
2)边界框识别(分类与回归)和掩码预测的网络头,分别应用于每个RoI。
结构如图所示:

3.6 Implementation Details
按照现有的Fast/Faster R-CNN工作设置超参数,虽然是为了目标检测而设置,但是对于实例分割中同样有用。
3.6.1 Training
当预测框与gt box的IoU大于0.5时,被认为是正样本,而只有正样本才有掩码损失 L m a s k L_{mask} Lmask,掩码目标是RoI与其关联的ground-truth mask之间的交集。其中,对于不带FPN结构设置RoI数量为64,带有FPN结构设置RoI数量为512,正负样本比例为1:3,而RPN的anchor有5个面积大小与3个比例,。
3.6.2 Inference
在推断时,候选框对于C4主干网是300,而对于FPN是1000。然后在这些候选框上运行box预测分支(包含分类与回归),然后是非最大抑制处理。然后将掩码分支应用于最高得分的100个检测框(这不同于训练中使用的并行计算),掩码分支可以预测每个RoI的 k k k个掩码,但是这里只使用第 k k k个掩码,其中 k k k是分类分支预测的类。然后将m×m浮点数掩码输出调整到RoI大小,并在0.5的阈值下进行二进制化。
4. Result
- 实例分割效果:
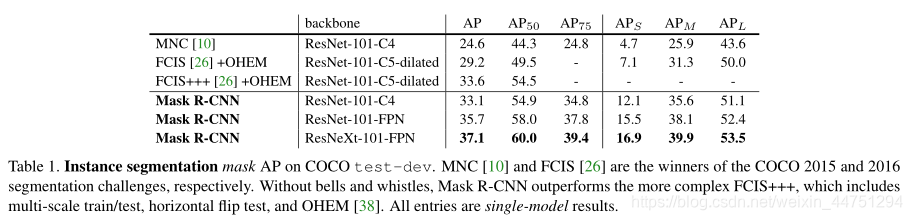
- 目标检测效果:
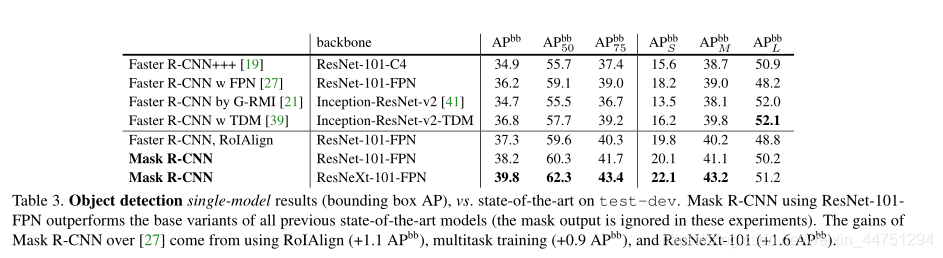
总结:
在Faster R-CNN的基础上进行了改进使得可以处理实例分割任务。提出了RoIAlign来替换掉RoIPool,使得处理检测任务性能更好。
所以,个人认为,Mask R-CNN作为一种新的目标检测算法,其实只是改进了RoIPool,进一步强调了对其的重要性。