如有错误,恳请指出。
文章目录
paper:Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training

摘要:
虽然两阶段目标检测算法近年不断发展,但是其训练过程并非完美的。作者发现了固定网络设置和动态训练过程之间存在的不一致问题,这极大地影响了性能。固定标签分配策略和回归损失函数不能适应候选框的分布变化,因此不利于训练高质量的检测器。
为此,作者提出了Dynamic R-CNN算法。基于训练时候选框的统计数据,Dynamic R-CNN可以自动调整标签分配标准(IoU阈值)和回归损失函数的形状(SmoothL1 Loss的参数)。这种动态设计更好地利用了训练样本,并推动检测器适应更多高质量的样本,其中高质量代表高IoU下的结果。
与Libra R-CNN一样,Dynamic R-CNN的关注点也是在训练过程上。
1. Introduction
对于目标检测的分类与普通的分类任务是不一样的,在目标检测中是对候选框进行分类。而如何区分候选框是正样本还是负样本,一般通过与其所对于的ground truth的IoU来判断,当超过一定的阈值时才会将候选框判定为正样本。之前阅读的Cascade R-CNN论文中有提到过,用单一的IoU阈值去训练网络会严重的限制网络的性能,且得到的候选框质量不算很高。为了得到质量比较高的候选框,一般需要设置一个比较高的阈值,而如果在训练时直接设置一个高阈值,由于正样本的敏感性,会让正样本的数量严重下降。为此,Cascade R-CNN提出了级联训练思想,通过多个回归器不断提高阈值,进而不断提高输出候选框的质量。虽然有效,但是费时。而且对于回归器还是会出现问题,因为在训练过程中,候选框的质量虽然得到了提高,但是SmoothL1损失中的参数是固定的。因此,这导致对高质量候选框的训练不足。
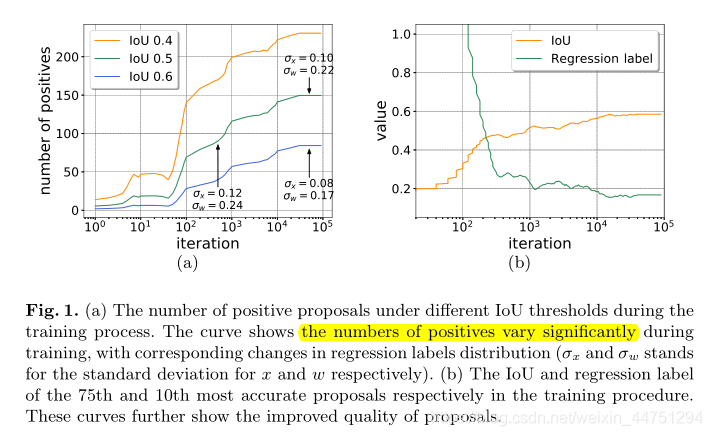
为了解决这个问题,作者首先检查一个被忽略的事实,即建议的质量确实在培训期间得到了提高,如图1所示。可以发现,即使在不同的IoU阈值下,阳性的数量仍然显著增加。
为此,作者提出了Dynamic R-CNN算法,其由两个部分组成:1)动态标签分配(Dynamic Label Assignment);2)动态SmoothL1损失(Dynamic SmoothL1 Loss);分别为分类和回归分支设计。
为了能训练出一个能更好的区别高质量IoU候选框的分类器,作者根据训练过程中的候选框分布,逐步调整正/负样本的IoU阈值。具体来说,就是将候选框的IoU阈值设置为某个百分比,因为它可以反映总体分配的质量。对于回归,作者选择改变回归损失函数的形状,自适应地拟合回归标签的分布变化,保证高质量样本对训练的贡献。然后作者根据回归标签分布调整SmoothL1损失中的 β β β,因为 β β β实际上控制小误差梯度的大小。
通过这种动态的方案,不仅可以缓解训练初期的数据稀缺问题,还可以收获高IoU训练的好处。这两个模块探索检测器的不同部分,因此可以协作实现高质量的物体检测。
2. Related Work
用这一节补充一下之前没有接触过的论文。
-
IoU-Net
检测中的分类分数不仅决定了每个候选框的语义类别,还影响边界框的准确性,因为非最大抑制(NMS)使用更可靠的边界框来抑制置信度较低的边界框,而其首先使用分类分数对预测边界框进行排序。然而,如IoU-Net所述,分类得分与定位精度的相关性较低,导致排序有噪声且性能有限。因此,IoU-Net采用了一个额外的分支来预测IoU得分和细化分类置信度。 -
Dynamic training
遵循动态训练的思想有各种各样的研究。一个广泛使用的例子是基于训练迭代调整学习速率。此外,课程学习(Curriculum Learning)和自定进度学习(Self-paced Learning)侧重于改善样本的训练顺序。对于目标检测,硬挖掘方法也可以看作是一种动态的方式。然而,这些方法没有处理目标检测中的核心问题:例如常量标签分配策略(constant label assignment strategy)。
3. Dynamic Quality in the Training Procedure
一般来说,目标检测是复杂的,因为它需要解决两个主要任务:识别和定位。识别任务需要区分前景对象和背景,并为它们确定语义类别。此外,定位任务需要为不同的对象找到准确的边界框。为了实现高质量的物体检测,我们需要进一步探索这两个任务的训练过程如下。
3.1 Proposal Classification
如果候选框与ground-truth没有任何交集,则肯定其为负样本;而如果候选框与 ground-truth完全重合,则肯定其为正样本。但是如果候选框与ground-truth的IoU为0.5,判断其是正样本还是负样本是一个问题。
在Faster RCNN中,标签是通过使用预定义的IoU阈值将预测框的最高IoU与ground-truth进行比较来分配的。基本可以用以下公式来表示:
l a b e l = { 1 , if max IoU(b,G) ≥ T + 0 , if max IoU(b,G) < T − − 1 , otherwise (1) label = \begin{cases} 1,&\text{if $\max$ IoU(b,G) ≥ $T_{+}$} \\ 0,&\text{if $\max$ IoU(b,G) < $T_{-}$} \\ -1,&\text{otherwise} \\ \tag{1} \end{cases} label=⎩⎪⎨⎪⎧1,0,−1,if max IoU(b,G) ≥ T+if max IoU(b,G) < T−otherwise(1)
其中, T + T_{+} T+和 T − T_{-} T−是IoU的正负阈值; 1 , 0 , − 1 1,0,−1 1,0,−1分别表示正样本,负样本和忽略样本。在Faster RCNN中, T + = T − = 0.5 T_{+} = T_{-} = 0.5 T+=T−=0.5,所以正样本与负样本的本质上是手动设置的。
由于分类器的目标是区分正负样本,因此使用不同的IoU阈值进行训练将得到具有相应质量的分类器。因此,为了实现高质量的目标检测需要训练具有高IoU阈值的分类器,但是直接提高阈值会导致正样本的大量消失。Cascade R-CNN采取级联训练的方法,有效但是费时。
那么有没有办法两全其美呢?如上所述,候选框的质量实际上随着训练而提高。这个现象启发了作者在训练的时候采取渐进的方法:在开始时,RPN网络无法产生足够高质量的候选框,因此作者在第二阶段训练中使用较低的IoU阈值来更好地容纳这些低质量的候选框。随着训练的进行候选框质量不断提高,逐渐拥有了足够高质量的候选框。因此,此时可以提高阈值来训练高质量的检测器,在更高的IoU下具有更强的鉴别力。
通过进阶式的在训练中不断的提高阈值,从而达到效果,且没有像Cascade R-CNN那样额外费时。
3.2 Bounding Box Regression
边界框回归的任务是将正样本的候选框 b b b回归到ground-truth值 g g g上,这是在回归损失函数 L r e g L_{reg} Lreg的监督下学习的。为了避免边界框偏移幅度太大而造成标签变化,回归的偏移量被定义为:
δ x = ( g x − b x ) / b w δ y = ( g y − b y ) / b h δ w = log ( g w / b w ) δ h = log ( g h / b h ) (2) \begin{aligned} δ_{x} &= (g_{x}-b_{x})/b_{w} \\ δ_{y} &= (g_{y}-b_{y})/b_{h} \\ δ_{w} &= \log(g_{w}/b_{w}) \\ δ_{h} &= \log(g_{h}/b_{h}) \\ \tag{2} \end{aligned} δxδyδwδh=(gx−bx)/bw=(gy−by)/bh=log(gw/bw)=log(gh/bh)(2)
由于边界框会按照以上公式进行偏移,而这些偏移量可以会比较小。为了平衡多任务学习中的不同术语,通常用预定义的平均值和标准偏差来归一化 ∆ ∆ ∆.
然而,作者发现回归标签(regression labels)的分布在训练过程中是移动的。如图2所示:其中 δ δ δ是预测框相对于标注框的偏移大小,而这里作者的regression labels个人理解,感觉就是相对的偏移量参数。
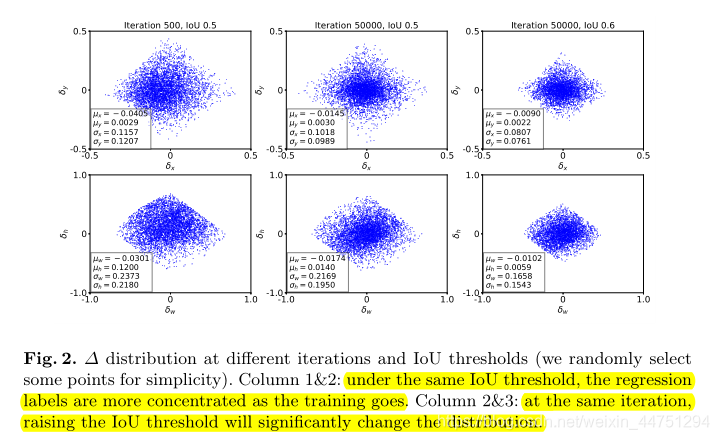
作者计算了不同迭代次数和IoU阈值下回归标签的统计量。首先,在前两列中,作者发现在相同的正样本IoU阈值下,由于候选框质量的提高,均值和stdev随着训练的进行而降低。在归一化因子相同的情况下,基于SmoothL1 Loss函数的定义,这些高质量样本的贡献将减少,这不利于高质量回归器的训练。由于均值和方差均减小,预测的偏移也会减小即损失值减小,而此时正样本的比例是在不断变大的。即相对减小了高质量的正样本在训练过程中的贡献。
而且,随着更高的IoU阈值,正样本的质量进一步增强,从而它们的贡献甚至会进一步降低,这将极大地限制整体性能。因此,为了实现高质量的目标检测,需要拟合分布变化并调整回归损失函数的形状,以补偿高质量候选框的增加。
4. Dynamic R-CNN
Dynamic R-CNN中的关键思想是:调整第二阶段的分类器和回归器,以适应候选框的分布变化。处理流程如图所示:
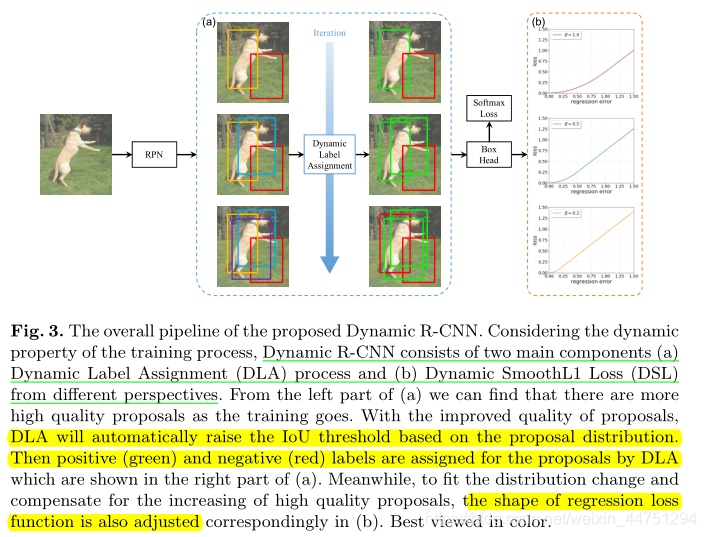
下面会分别加以说明。
4.1 Dynamic Label Assignment
基于目标检测中常用的阈值设定公式(1),Dynamic R-CNN对其进行了一定的改动,如下所示:
l a b e l = { 1 , if max IoU(b,G) ≥ T n o w 0 , if max IoU(b,G) < T n o w (3) label = \begin{cases} 1,&\text{if $\max$ IoU(b,G) ≥ $T_{now}$} \\ 0,&\text{if $\max$ IoU(b,G) < $T_{now}$} \tag{3} \end{cases} label={
1,0,if max IoU(b,G) ≥ Tnowif max IoU(b,G) < Tnow(3)
其中, T n o w T_{now} Tnow代表当前的IoU阈值。考虑到,候选框的分布会随着时间的推移而变化的动态特性,然后DLA根据候选框的统计数据自动更新,以适应这种分布变化。
具体的操作过程是,对于每一批次的训练时会得到候选框的IoU集合 I I I,然后作者会提取这个集合中的前 K K K个最高的IoU值,取这前 K K K个最高的IoU值的均值来作为下一批次训练的阈值。也就是说,每经过了一定的迭代次数 C C C,评判正负样本的IoU阈值会不断增加。也就是随着训练的进行, T n o w T_{now} Tnow会不断增加,反映了候选框质量的提高(因为采用的是前 K K K个候选框的IoU均值作为 T n o w T_{now} Tnow的)。
具体的操作其实不算很难,所以几乎没有增加额外的复杂度,相比Cascade R-CNN级联处理,思想是类似的,但是做法简单得多。
4.2 Dynamic SmoothL1 Loss
目标检测的定位任务由常用的SmoothL1损失来监督,它可以表述如下:
s m o o t h L 1 ( x , β ) = { 0.5 ∣ x ∣ 2 / β , if |x|<β ∣ x ∣ − 0.5 β , otherwise (4) smooth_{L_{1}}(x,β) = \begin{cases} 0.5|x|^{2}/β,&\text{if |x|<β} \\ |x|-0.5β,&\text{otherwise} \tag{4} \end{cases} smoothL1(x,β)={
0.5∣x∣2/β,∣x∣−0.5β,if |x|<βotherwise(4)
其中,这里 x x x代表回归标签, β β β是一个超参数控制。作者认为在这个范围内,应该使用更柔软的损耗函数:如L1损耗,而不是原来的L2损耗。考虑到训练的鲁棒性, β β β被默认设置为1.0,以防止由于网络在早期训练不良而导致的爆炸损失。其中改变β导致不同的损耗和梯度曲线,如下图所示:
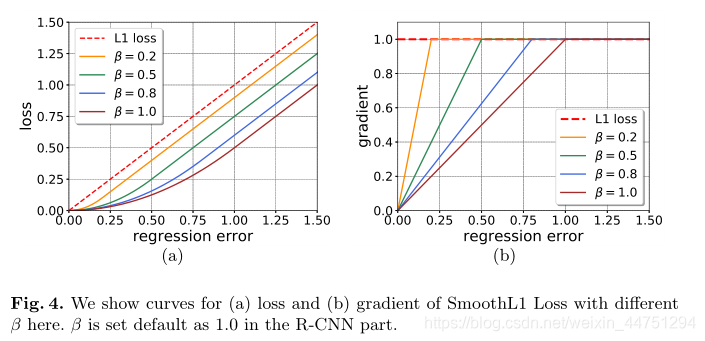
在图中可以发现,当 β β β值较小时,其回归速率会更快,其梯度也更陡。所以较小的 β β β实际上加速了梯度大小的饱和,我理解为可以比较快的收敛,从而使得更精确的样本对网络训练的贡献更大。
如第3.2节所分析的,现在需要拟合分布变化并调整回归损失函数,以补偿高质量的样本。因此,作者提出了动态SmoothL1损失(Dynamic SmoothL1 Loss,DSL)来改变损失函数的形状,以逐渐关注高质量的样本,其公式如下:
s m o o t h L 1 ( x , β n o w ) = { 0.5 ∣ x ∣ 2 / β n o w , if | x ∣ < β n o w ∣ x ∣ − 0.5 β n o w , otherwise (5) smooth_{L_{1}}(x,β_{now}) = \begin{cases} 0.5|x|^{2}/β_{now},&\text{if |$x|<β_{now}$} \\ |x|-0.5β_{now},&\text{otherwise} \tag{5} \end{cases} smoothL1(x,βnow)={
0.5∣x∣2/βnow,∣x∣−0.5βnow,if |x∣<βnowotherwise(5)
类似于DLA,DSL现在会根据能够反映定位精度的回归标签的统计来改变 β β β的值。假定候选框的偏移量参数 δ δ δ集合为 E E E,每进行一定的迭代次数,从集合 E E E中挑选前 K K K个最小的参数量的中值,去对 β n o w β_{now} βnow进行更新。从后面的算法流程图感觉,其实这里的 β n o w β_{now} βnow就等于回归参数前 K K K个最小值的中值。选择中值而不是分类中的平均值是因为作者在回归标签中发现了更多的异常值(outliers)。
看完这里其实有点晕,但是简单来说就是随着训练回归参数是会改变的,均值与方差不断的变小,这同时会造成原式中 β β β的变化。而固定不变的将 β β β设置为1,确实是会影响网络的性能的。所以,这里作者根据不断变化的回归参数动态的改变 β β β以实现补偿。而 β β β的取值就等于当前前 K K K个最小回归参数的中值。
小结:
阈值与 β β β的取值如下所示:
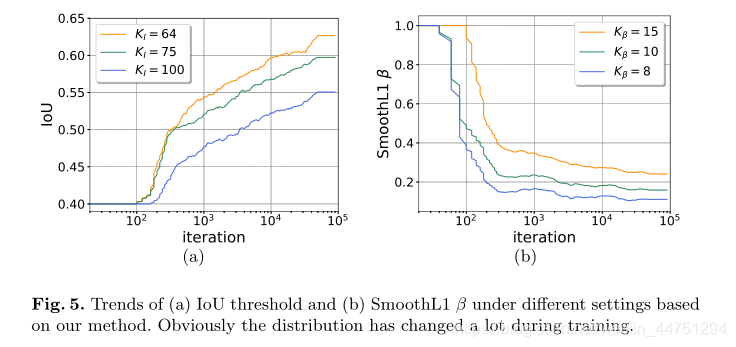
这里再再补充,随着不断训练,回归参数的均值与标准差是不断减小的,而为了平衡这种差异,回归损失的β就不应该保持1不变,而是应该随着数据分布的变化而变化,所以作者取前 K K K个最小值的中值作为 β β β值。所以 β β β值也是在不断减小的。而不断减小的 β β β可以加速梯度幅度的饱和,从而使得更精确的样本对网络训练贡献更大。(不过关于这一点,我还是不清楚,为什么断减小的 β β β可以使得使得更精确的样本对网络训练贡献更大,虽然实验结果却是如此)
算法流程图如下所示:

5. Result
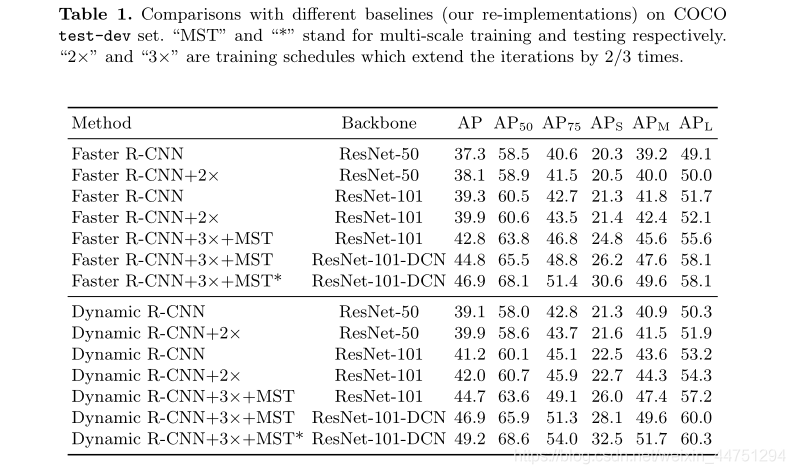
- 与其他baseline的对比:
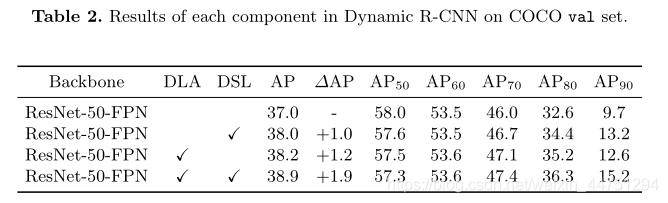
- 两个模块的作用:
- 与SOTA的对比:
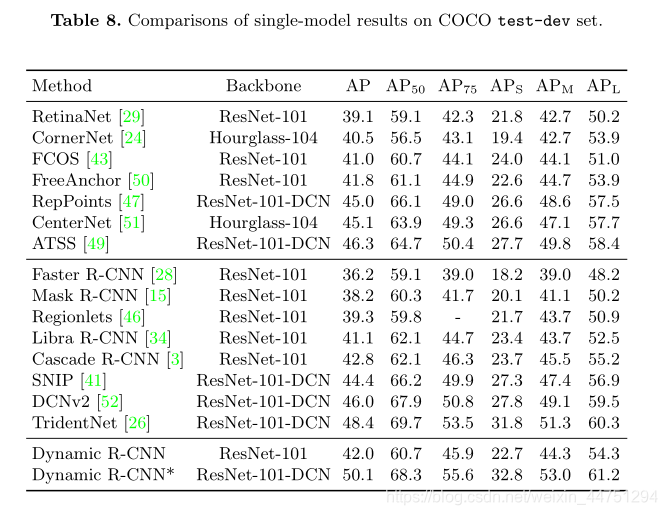
效果好像还不错,与DCN配合使用达到了50的mAP。
总结:
作者的关注点与Libra RCNN一样,关注与训练过程中的动态问题。提出动态的提高阈值训练,且动态的降低SmoothL1损失函数中的β,来提高网络性能。