如有错误,恳请指出。
文章目录
paper:Libra R-CNN: Towards Balanced Learning for Object Detection

摘要:
相比于模型结构,相比之下如何对模型进行训练这一方面受到的关注比较少,但是其对于目标检测任务来说同样的重要。作者回顾了检测器的标准训练过程,发现了检测性能往往受到训练过程中不平衡的限制,而这种不平衡一般由三个层次组成:样本层(sample level)、特征层(feature level)和目标层(objective level)。
为了解决这个问题,作者提出了Libra R-CNN,用来平衡训练过程。Libra R-CNN由三个新组建构成:IoU平衡采样(IoU-balanced sampling)、平衡特征金字塔(balanced feature pyramid)和平衡L1损失(balanced L1 loss),分别用于降低采样、特征和目标三个层次的不平衡。
1. Introduction
不断涌现的网络结构推动了目标检测的发展,但尽管流水线架构(例如单阶段与两阶段)中存在明显的差异,但现代检测框架大多遵循共同的训练流程:即采样区域,从中提取特征,然后在标准多任务目标函数的指导下共同识别类别并细化位置。
基于这种训练流程,目标检测器训练的成功取决于三个关键方面:
1)所选区域样本是否具有代表性
2)提取的视觉特征是否被充分利用
3)设计的目标函数是否最优
作者的研究表明,典型的训练过程在所有这些方面都明显不平衡。这种不平衡问题阻碍了设计良好的模型体系结构的能力被充分利用,从而限制了整体性能,如图所示:
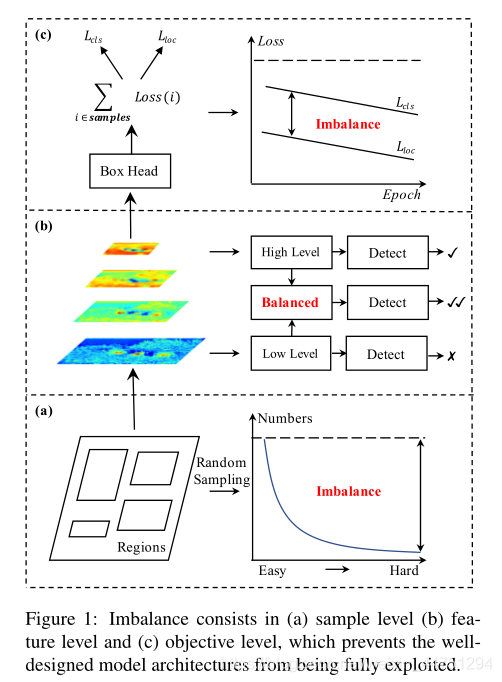
1.1 Sample level imbalance
当训练对象检测器时,困难样本特别有价值,因为它们对提高检测性能更有效。然而,随机抽样方案通常导致所选择的样本被容易样本所支配。如图1中的(a)所示,正负样本的数量之间存在严重的不平衡问题,负样本要比正样本要多得多。常用的提高困难样本关注的方法:
-
OHEM
OHEM有助于提高对困难样本的关注。然而它们通常对噪声标签很敏感,并导致相当大的内存和计算成本。 -
Focal loss
Focal loss也缓解了One-step检测器中的这个问题,但是当扩展到R-CNN时发现几乎没有改善,因为大多数容易样本被two-stage检测器中的两个挑选流程过滤掉。(yolov4中也发现Focal loss没有起到效果)
在我另外一篇笔记中有详细说明一些数据分布不均衡所采取的方法:YOLOv4中的tricks概念总结——Bag of freebies,其中的第五点有介绍到。
因此,这个问题还有待细致解决。
1.2 Feature level imbalance
主干中的深层高级特征具有更多的语义含义,而浅层低级特征更具内容描述性。FPN和PANet通过横向连接进行的特征集成推动了目标检测的发展。
- FPN:提出了横向连接,通过自上而下的途径丰富浅层的语义信息
- PANet:引入自下而上的途径,进一步增加深层的低层次信息
这些方法表明低层和高层信息对于目标检测是互补的,如何利用它们来整合金字塔表示的方法决定了检测性能。
但是,将它们集成在一起的最佳方法是什么?作者的研究表明,综合特征应该具有来自每个分辨率的平衡信息。但是上述方法中的顺序方式将使综合特征更多地关注相邻分辨率,而较少关注其他分辨率。在信息流中,非相邻层次的语义信息在每次融合时会被稀释一次。
因此,作者提出的方法依赖于集成的平衡语义特征来增强原始特征。以这种方式,每个分辨率都将信息从其他分辨率中分离出来,从而平衡信息流并使特征更具区别性。
1.3 Objective level imbalance
有研究表明,基于多任务学习的模型的性能强烈依赖于每个任务损失之间的相对权重。而检测器需要执行两个任务,即分类和定位。因此,训练目标包含两个不同的目标。如果它们没有得到适当的平衡,一个目标可能会受到损害,导致整体性能不佳。
训练过程中涉及的样本也是如此。如果它们没有得到适当的平衡,由简单样本产生的小梯度可能会淹没在由硬样本产生的大梯度中,从而限制了进一步的细化。因此,需要重新平衡所涉及的任务和样本,以实现最佳收敛。而作者的方法重新平衡所涉及的任务和样本,以实现更好的收敛。
小结:
为了减轻这些问题造成的不利影响,作者提出了Libra R-CNN算法,明确地在上面讨论的所有三个层次上实施平衡。这个框架集成了三个新组件:
1)IoU-balanced sampling:根据困难样本的与指定ground-truth的IoU来挖掘硬样本,也就是提高注意力。
2) balanced feature pyramid:其使用相同的深度集成的平衡语义特征来加强多级特征。
3)balanced L1 loss:提升关键梯度,以重新平衡所涉及的分类、整体定位和精确定位。
作者的主要贡献:
1)系统地回顾了检测器的训练过程,揭示了限制检测性能的三个层次的不平衡问题。
2)提出了Libra RCNN,这是一个通过结合三个新的组成部分来重新平衡训练过程的框架:IoU平衡采样、平衡特征金字塔和平衡L1损失。
3)在MS COCO上测试了所提出的框架,与最先进的检测器(包括单级和两级检测器)相比,不断获得显著的改进。
2. Libra R-CNN Methodology
Libra R-CNN的目标是使用整体平衡设计来缓解检测器训练过程中存在的不平衡,从而尽可能挖掘模型架构的潜力,其整体架构如下图所示:
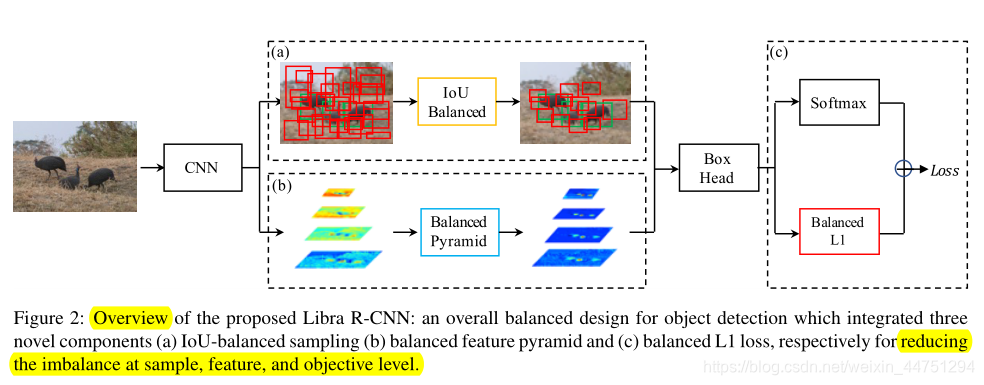
2.1 IoU-balanced Sampling
对于RPN网络提供的候选框中仍然存在大量的样本,在这些负样本中有困难的负样本也有简单的负样本。其中困难的负样本就是被判断为假阳性的概率高,所以传统的双阶段的硬样本挖掘需要对这些困难样本进行复杂计算得出结果。而如果是简单对RPN网络提供的候选框进行随机抽样,明显效果不会是最好的,所以希望能够尽量的挑选多一些的困难负样本。
基于这个问题,现在从一个基本问题开始:训练样本与其对应的ground truth之间的重叠是否与其难度相关联?这里主要考虑困难负样本,作者从实验发现,超过60%的困难负样本具有大于0.05的重叠,但是随机采样只为我们提供了大于相同阈值的30%的训练样本,如图所示:
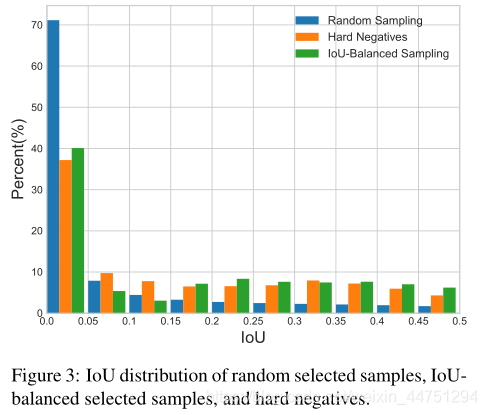
这种极端的样品不平衡将许多困难负样本埋藏在成千上万个简单负样本中。
基于这一观察,作者提出了IoU平衡采样:一种简单但有效的硬挖掘方法,无需额外成本。假设现在需要从 M M M个对应的候选中抽取 N N N个负样本。随机抽样下每个样本的选择概率为:
p = N M p = \frac{N}{M} p=MN
为了提高困难负样本的选择概率,作者根据IoU将采样间隔平均分成 K K K个区间。所以 N N N个要求的负样本被平均分配到每个箱中,然后再统一从中挑选样本。因此,得到了IoU平衡采样下的选择概率为:
p k = N K ∗ 1 M k , k ∈ [ 0 , K ) p_{k} = \frac{N}{K}*\frac{1}{M_{k}},k∈[0,K) pk=KN∗Mk1,k∈[0,K)
其中, M k M_{k} Mk是由 k k k表示的相应区间中的采样候选数,这里作者设置 K = 3 K=3 K=3,也就是将IoU采样间隔分为了3个区间。
由上图3可以看出,IoU平衡采样可以引导训练样本的分布接近困难负样本的分布。实验还表明,实验结果对K不敏感,具有更高IoU的样本往往更有可能被选择。可以了解到,通过这种采样方法,明显比随机抽样的结果挑选的困难负样本要好。
此外该方法也适用于困难正样品。然而在大多数情况下并没有足够的候选样本将该程序扩展到正样本中。为了使平衡抽样程序更全面,我们对每个ground truth抽样相等的正样本作为替代方法。
2.2 Balanced Feature Pyramid
与以前使用横向连接集成多级特征的方法不同,作者的关键思想是使用相同的深度集成的平衡语义特征来增强多级特征。它包括四个步骤,重新调整,整合,提炼和加强,具体结构如图所示:
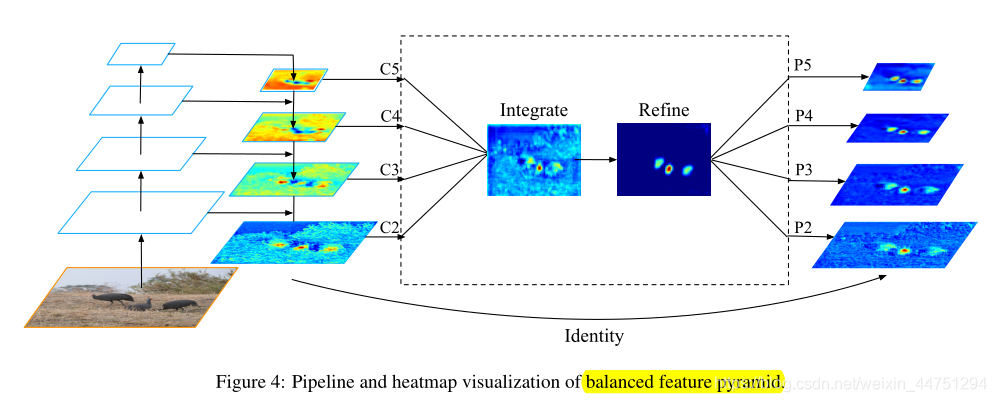
预测特征层为 l l l的层级被定义为 C l C_{l} Cl,预测特征层总层级数为 L L L,其中涉及最高层级与最低层级定义为 l m a x l_{max} lmax与 l m i n l_{min} lmin,如上图中的 C 2 C_{2} C2具有最大的图片分辨率尺度。为了集成多级特征层并同时保留它们各自的语义层次,作者首先将多级特征 { C 2 , C 3 , C 4 , C 5 } \{C_{2},C_{3},C_{4},C_{5}\} {
C2,C3,C4,C5}调整到中间大小(Integrate),即与 C 4 C_{4} C4相同的大小,分别使用插值和最大池化处理,对于小尺寸的特征图可以进行池化处理,而对于大尺度的特征图可以进行双线性插值处理。通过简单的平均获得平衡的语义特征,可以表示为:
C = 1 L ∑ l = l m i n l m a x C l C = \frac{1}{L}\sum_{l=l_{min}}^{l_{max}}C_{l} C=L1l=lmin∑lmaxCl
然后,使用相同但相反的过程对获得的特征进行重新缩放,以增强原始特征。在此过程中,每层预测特征层从其他预测特征层获得相同的信息。请注意,此过程不包含任何参数。作者观察到这种非参数方法的改进,证明了信息流的有效性。
在上诉重新缩放之前,平衡的语义特征可以进一步提炼(Refine),使其更具区别性。作者发现直接使用卷积的提炼和非局部模块(non-local module)都工作良好,但是非局部模块工作更稳定。因此,本文使用嵌入的高斯非局部注意(embedded Gaussian non-local attention)作为提炼步骤,这提炼步骤有助于增强集成特性并进一步改善结果。
通过这种方法,从低级到高级的特征被同时聚集。输出的预测特征层 { P 2 , P 3 , P 4 , P 5 } \{P_{2},P_{3},P_{4},P_{5}\} { P2,P3,P4,P5}各自用于目标检测,这与FPN一样。还值得一提的是,平衡特征金字塔(balanced feature pyramid)可以与FPN或者PAFPN互补工作,没有任何冲突。
ps:在这个过程中,设计到non-local module,这个出现在非局部神经网络(Non-local Neural Networks),非局部通用网络结构,由何恺明提出,non-local指的就是感受野可以很大。对于non-local module的说明之后会进行补充。
2.3 Balanced L1 Loss
自Fast R-CNN以来,分类和定位问题在多任务损失的指导下被同时解决,其被定义为:
L p , u , t u , v = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L_{p,u,t^{u},v}=L_{cls}(p,u)+\lambda[u≥1]L_{loc}(t^{u},v) Lp,u,tu,v=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
其中, L c l s L_{cls} Lcls与 L l o c L_{loc} Lloc分别对应于识别和定位的目标函数。 L c l s L_{cls} Lcls中的预测类别和目标类别表示为 p p p和 u u u, t u t^{u} tu对应的 u u u类的预测边界框结果, v v v是回归目标边界框, λ λ λ用于调整多任务学习下的损失权重。这里将损失大于或等于1.0的样本称为异常值(outliers),其他样本称为内联值(inliers)。
平衡相关任务的一个自然解决方案是调整它们的损失权重。然而,由于回归目标无界,直接提高局部化损失的权重会使模型对异常值更加敏感。这些异常值可视为困难样本,会产生过大的梯度,对训练过程有害。而与异常值相比,内联值对整体梯度的贡献很小,可以被视为简单样本。更具体地说,与异常值相比,内联值对每个样本平均只贡献30%的梯度。考虑到这些问题,我们提出了平衡L1损耗,表示为 L b L_{b} Lb。
Balanced L1 loss源自传统的smooth L1 loss,其中拐点被设置为将内联器与外联器分开,并将1.0设置为异常值outliers产生的最大梯度,如下图(a)所示:
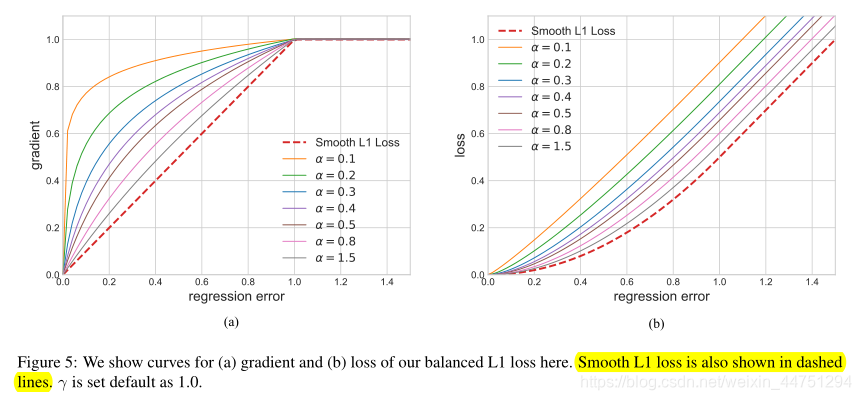
平衡L1损失的关键思想是促进关键的回归梯度,即来自内联器(精确样本)的梯度,以重新平衡所涉及的样本和任务,从而在分类、整体定位和精确定位中实现更平衡的训练。本地化损失 L l o c L_{loc} Lloc分配平衡L1损失定义为:
L l o c = ∑ i ∈ { x , y , w , h } L b ( t i u − v i ) L_{loc}=\sum_{i∈\{x,y,w,h\}}L_{b}(t^{u}_{i}-v_{i}) Lloc=i∈{
x,y,w,h}∑Lb(tiu−vi)
其相应的梯度公式如下:
∂ L l o c ∂ w ∝ ∂ L b ∂ t i u ∝ ∂ L b ∂ x \frac{∂L_{loc}}{∂w} ∝ \frac{∂L_{b}}{∂t^{u}_{i}} ∝ \frac{∂L_{b}}{∂x} ∂w∂Lloc∝∂tiu∂Lb∝∂x∂Lb
基于上面的公式,作者设计了一个改进的梯度公式:
∂ L b ∂ x = { α ln ( b ∣ x ∣ + 1 ) , if |x|<1 γ , otherwise \frac{∂L_{b}}{∂x} = \begin{cases} α\ln(b|x|+1),&\text{if |x|<1} \\ γ,&\text{otherwise} \end{cases} ∂x∂Lb={
αln(b∣x∣+1),γ,if |x|<1otherwise
由上图(a)显示,在 α α α因子的控制下,平衡L1损耗增加了inliers的梯度。较小的 α α α为inliers增加了更多的梯度,但outliers的梯度不受影响。此外,为了调整回归误差的上界,引入了由 γ γ γ控制的整体提升倍率,这可以帮助目标函数更好地平衡所涉及的任务。控制不同方面的两个因素相互增强,达到更均衡的训练。b用于确保等式中两个公式的 L b ( x = 1 ) L_{b}(x = 1) Lb(x=1)值相同。
通过积分上面的梯度公式,我们可以得到平衡的L1损耗:
L b ( x ) = { α b ( b ∣ x ∣ + 1 ) ln ( b ∣ x ∣ + 1 ) − α ∣ x ∣ , if |x|<1 γ ∣ x ∣ + C , otherwise L_{b}(x) = \begin{cases} \frac{α}{b}(b|x|+1)\ln(b|x|+1)-α|x|,&\text{if |x|<1} \\ γ|x|+C,&\text{otherwise} \end{cases} Lb(x)={
bα(b∣x∣+1)ln(b∣x∣+1)−α∣x∣,γ∣x∣+C,if |x|<1otherwise
其中参数 γ γ γ、 α α α和 b b b受下列约束:
α ln ( b + 1 ) = γ α\ln(b+1)=γ αln(b+1)=γ
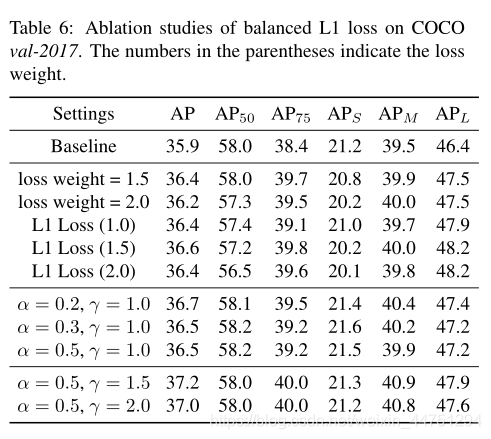
在实验中,默认参数设置为 α = 0.5 α = 0.5 α=0.5和 γ = 1.5 γ = 1.5 γ=1.5
小结:
至于作者如何提出这个改进的梯度公式的,在文中好像没有提及,可能我的数学水平还不够…对于这一点,直观上的小结就是作者将原来的smooth L1 loss改变为Balanced L1 loss。其中:
- smooth L1 loss公式为:
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^{u},v)=\sum_{i∈\{x,y,w,h\}}smooth_{L_{1}}(t^{u}_{i}-v_{i}) Lloc(tu,v)=i∈{ x,y,w,h}∑smoothL1(tiu−vi) - balanced L1 loss公式为:
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } L b ( t i u − v i ) L_{loc}(t^{u},v)=\sum_{i∈\{x,y,w,h\}}L_{b}(t^{u}_{i}-v_{i}) Lloc(tu,v)=i∈{ x,y,w,h}∑Lb(tiu−vi)
而其中:
- smooth L1定义为:
s m o o t h L 1 ( x ) = { 0.5 x 2 , if |x|<1 ∣ x ∣ − 0.5 , otherwise smooth_{L_{1}}(x) = \begin{cases} 0.5x^{2},&\text{if |x|<1} \\ |x|-0.5,&\text{otherwise} \end{cases} smoothL1(x)={ 0.5x2,∣x∣−0.5,if |x|<1otherwise - balanced L1定义为:
L b ( x ) = b a l a n c e d L 1 ( x ) = { α b ( b ∣ x ∣ + 1 ) ln ( b ∣ x ∣ + 1 ) − α ∣ x ∣ , if |x|<1 γ ∣ x ∣ + C , otherwise L_{b}(x) =balanced_{L_{1}}(x)= \begin{cases} \frac{α}{b}(b|x|+1)\ln(b|x|+1)-α|x|,&\text{if |x|<1} \\ γ|x|+C,&\text{otherwise} \end{cases} Lb(x)=balancedL1(x)={ bα(b∣x∣+1)ln(b∣x∣+1)−α∣x∣,γ∣x∣+C,if |x|<1otherwise
简单来说,就是将 b a l a n c e d L 1 ( x ) balanced_{L_{1}}(x) balancedL1(x)替换了 s m o o t h L 1 ( x ) smooth_{L_{1}}(x) smoothL1(x)
3. Result
-
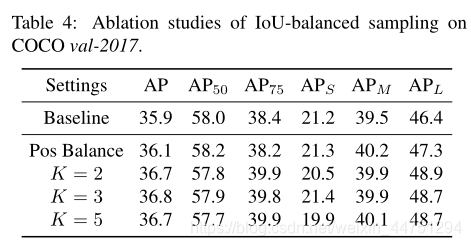
在困难负样本随机挑选时,划分的区间k=3时效果最好:
-
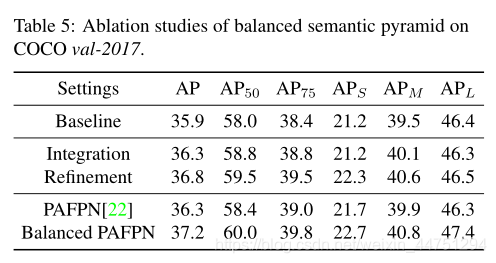
提出的balanced semantic pyramid的作用:
-
新定义的balanced L1的作用:
-
与SOTA的对比:
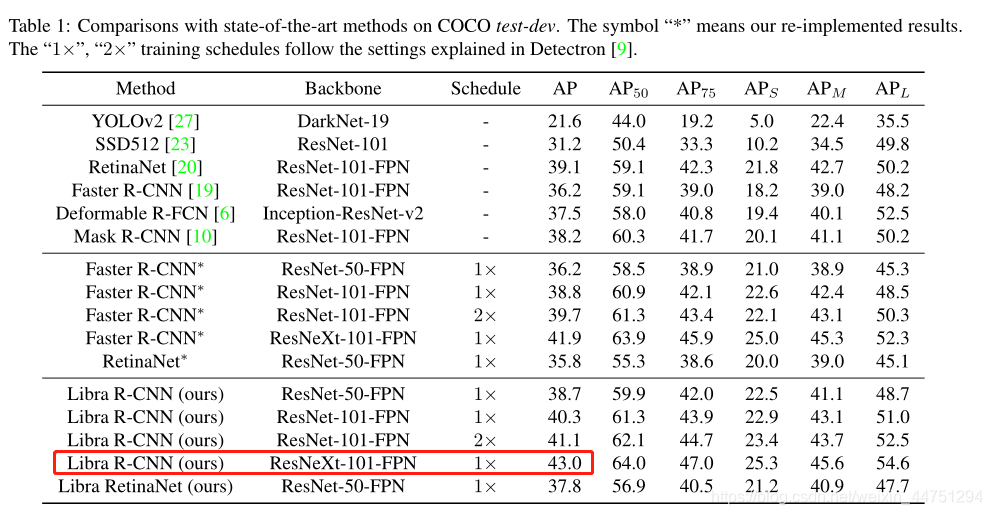
总结:
相比于网络结构的改变,作者将注意力放在了训练过程的改进上,提出3点改进:
1)通过对随机抽样负样本时设置分区进行抽样,增加了困难样本被挑选的概率。
2)对FPN结构进行改进,提出了Balanced FPN。其过程是对全部的预测特征层直接进行集成并进一步提炼处理,再之后就是池化或者双线性插值变化为FPN的类似输出,这对于性能竟然是有帮助的,证明了信息流的有效性。
3)抛弃传统的smooth L1函数,创造了balanced L1函数,并将其使用在边界框回归损失函数上,同样提高了性能。