矩阵
第二章矩阵代数
矩阵代数
定义
一个规模为 m × n \;m×n\; m×n的矩阵 M \;M\; M,是由 m \;m\; m行 n \;n\; n列实数所构成的矩阵阵列。行数和列数的乘积代表了矩阵的维度。矩阵中的数字则称作元素或者元。通过双下标表示法 M i j \;M_{ij}\; Mij指定元素的行和列就可以确定出对应的矩阵元素, M i j \;M_{ij}\; Mij表示的是矩阵的第 i \;i\; i行、第 j \;j\; j列元素。
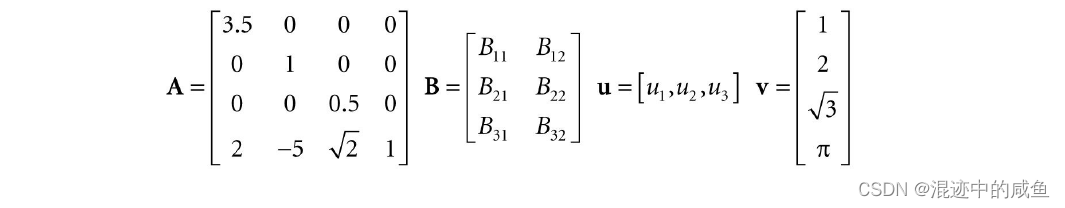
A A A是一个 4 × 4 4×4 4×4矩阵, B B B是一个 3 × 2 3×2 3×2矩阵, u u u是一个 1 × 3 1×3 1×3, v v v是一个 4 × 1 4×1 4×1矩阵。我们可以清晰地看到, u u u, v v v是俩种特殊的矩阵,分别只由一行元素或一列元素构成。由于它们常用与矩阵的形式来表示一个向量,例如,我们就可以自由的使用 ( x , y , z ) (x,y,z) (x,y,z)与 [ x , y , z ] [x,y,z] [x,y,z]俩种方式,这俩种向量,我们分别称他们为行向量或列向量。
在某些情况下,我们倾向于把矩阵的每一行都看做一个向量。例如,可以把矩阵写作:
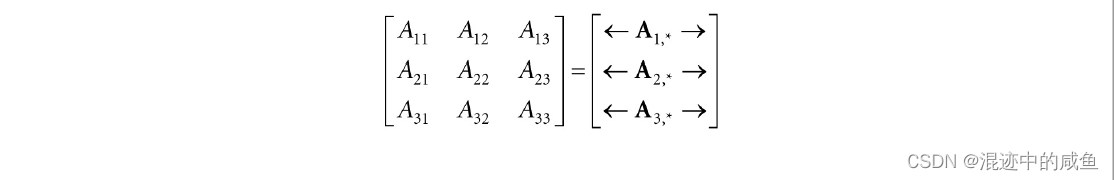
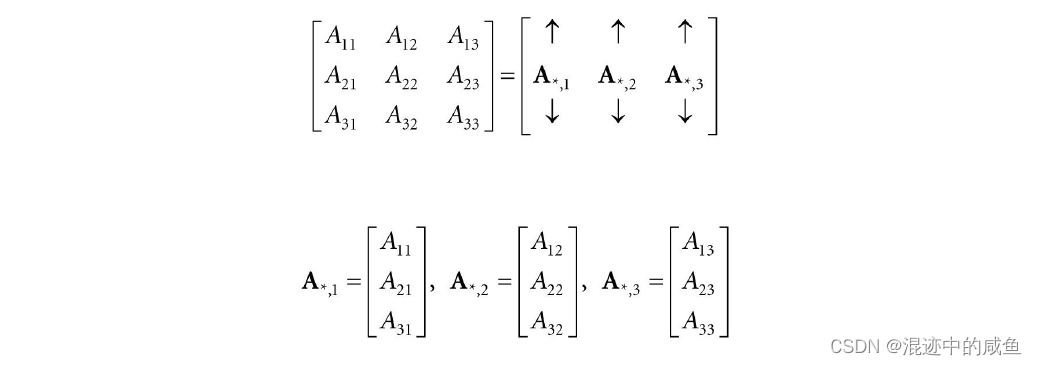
其中 A 1 , ∗ = [ A 11 , A 12 , A 13 ] A_{1,*}=[A_{11},A_{12},A_{13}] A1,∗=[A11,A12,A13], A 2 , ∗ = [ A 21 , A 22 , A 23 ] A_{2,*}=[A_{21},A_{22},A_{23}] A2,∗=[A21,A22,A23], A 3 , ∗ = [ A 31 , A 32 , A 33 ] A_{3,*}=[A_{31},A_{32},A_{33}] A3,∗=[A31,A32,A33],在这种表达式中,第一个所以表示特定的行,,第二个索引 " ∗ " "*" "∗"表示该行的整个行向量。而且对于矩阵的列也有类似的定义:
矩阵运算
简单代数运算
1.两个矩阵相等,当且仅当俩个矩阵对应的元素相等。为了加以比较,两者必有相同的行数和列数。
2.两个矩阵的加法运算,即将两者对应的元素相加。同理,当行数和列数分别相同时,两个矩阵的加法才有意义。
3.矩阵的标量乘法,就是将一个标量一次与矩阵内的每个元素相乘
4.利用矩阵加法和标量乘法可以定义出矩阵减法,即: A − B = A + ( − 1 ⋅ B ) = A + ( − B ) . A − B = A + (−1· B) = A + (−B). A−B=A+(−1⋅B)=A+(−B).
例如:
设
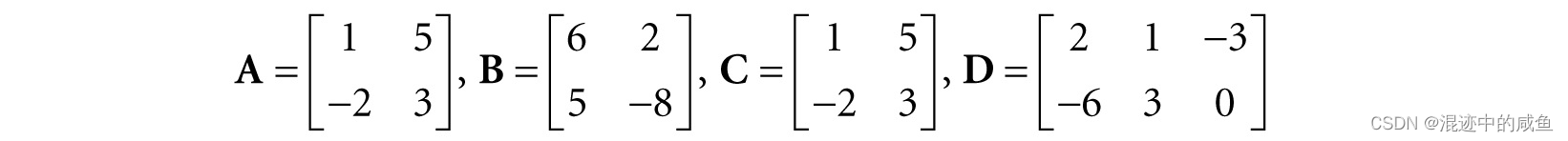
那么
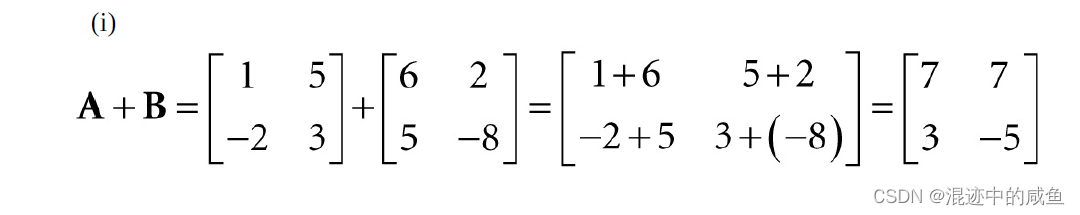
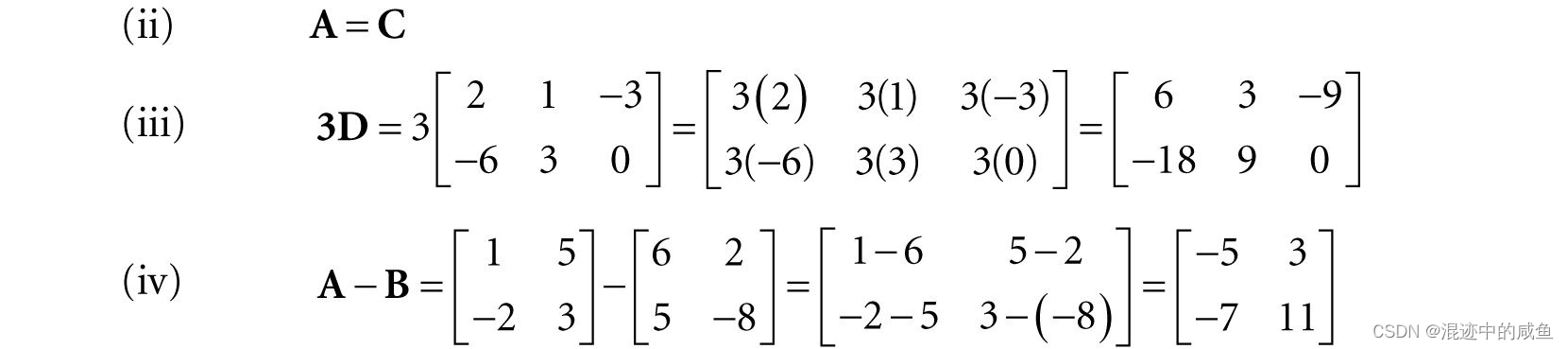
由于矩阵的加法运算和标量乘法过程中,是以元素为单位展开计算的,所以,它们也实际上也分别从实数运算中继承了下列性质:
1. A + B = B + A 加法交换律 1.A + B = B + A \qquad \qquad \qquad \qquad \qquad \quad \; \; \; 加法交换律 1.A+B=B+A加法交换律
2. ( A + B ) + C = A + ( B + C ) 加法结合律 2.(A + B) + C = A + (B + C)\qquad \qquad \qquad \, \, 加法结合律 2.(A+B)+C=A+(B+C)加法结合律
3. r ( A + B ) = r A + r B 标量乘法对矩阵加法的分配律 3.r(A + B) = rA + rB\qquad \qquad \qquad \qquad \quad \; \; \,标量乘法对矩阵加法的分配律 3.r(A+B)=rA+rB标量乘法对矩阵加法的分配律
4. ( r + s ) A = r A + s A 矩阵乘法对标量加法的分配律 4.(r + s)A = rA + sA\qquad \qquad \qquad \qquad \quad \; \; \; \; 矩阵乘法对标量加法的分配律 4.(r+s)A=rA+sA矩阵乘法对标量加法的分配律
矩阵乘法
定义
如果 A \;A\; A是一个 m × n \;m×n\; m×n矩阵, B B\; B是一个 n × p \;n×p\; n×p矩阵,那么两者的乘积 A B \;AB\; AB的结果是一个规模为 m × p \;m×p\; m×p的矩阵。矩阵 C \;C\; C中的第 i \;i\; i行、第 j \;j\; j列的元素,由矩阵 A \;A\; A的第 i \;i\; i个行向量与矩阵 B \;B\; B的第 j \;j\; j个列向量的点积切得,即:
要注意的是,为了使矩阵乘积 A B \;AB\; AB有意义,矩阵 A \;A\; A中的列数与矩阵 B \;B\; B中的行数必须相等。
例如:
因为 A \;A\; A的行数为2, B \;B\; B的列数为 3 \;3\; 3,所以俩种乘积 A B \;AB\; AB无定义。就如 2 D \;2D\; 2D向量与 3 D \;3D\; 3D向量无法做点积运算一致。
例:
设
由于 A \;A\; A的行数与 B \;B\; B的列数相同,则 A B \;AB\; AB的乘积是有意义的(其结果为 2 × 3 \;2×3\; 2×3的矩阵),根据矩阵运算法则得:
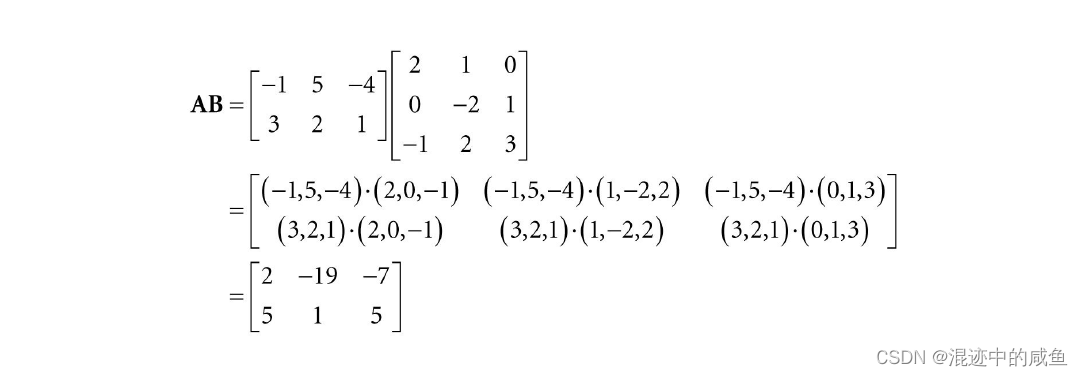
我们还可以发现矩阵乘积 B A \;BA\; BA没有意义,因为矩阵 B \;B\; B的列数不等于矩阵 A \;A\; A的行数。也就标明,矩阵的乘法一般不满足交换律,即 A B ≠ B A \;AB≠BA\; AB=BA。
向量与矩阵的乘法
考虑下列向量与矩阵的乘法运算:
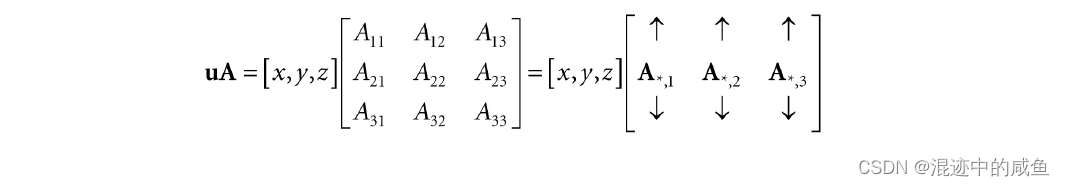
用矩阵直接的乘法公式可以得:
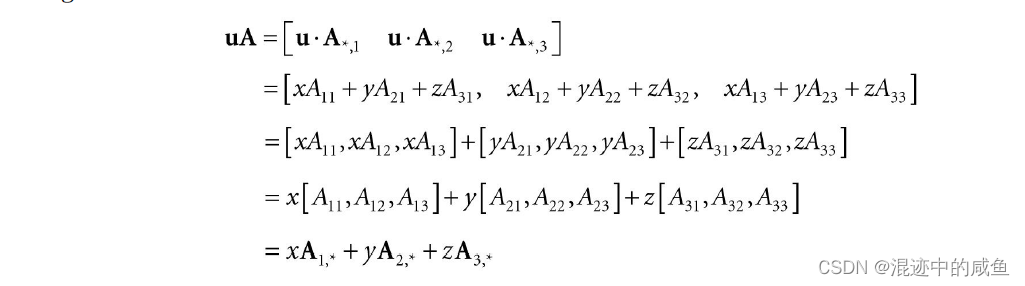
因此:
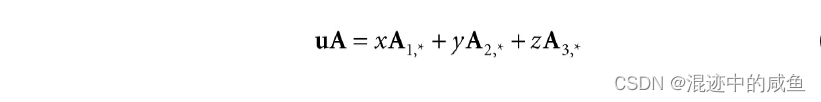
上式实为一种线性组合(linear combination),这意味着向量 u u u与矩阵 A A A的乘积相当于:向量 u u u给定标量 x x x、 y y y、 z z z矩阵的线性组合。结合上式可得:

结合律
矩阵的乘法具有一些很有用的代数性质。例如,矩阵乘法对矩阵加法的分配律 A ( B + C ) = A B + A C ) \;A(B + C) = AB + AC)\; A(B+C)=AB+AC)和 ( A + B ) C = A C + B C ) \;(A + B)C = AC + BC)\; (A+B)C=AC+BC)。除此之外,我们还可以利用到矩阵的乘法结合律:
( A B ) C = A ( B C ) (AB)C = A(BC) (AB)C=A(BC)
转置矩阵
转置矩阵指的是将原矩阵的行与列进行互换所得到的新矩阵。所以,根据一个 m × n \;m×n\; m×n矩阵可以得到一个规模为 n × m \;n×m\; n×m的转置矩阵。我们将矩阵 M \;M\; M的专职记作 M T M^T MT。
求出下列3个矩阵的转置矩阵:
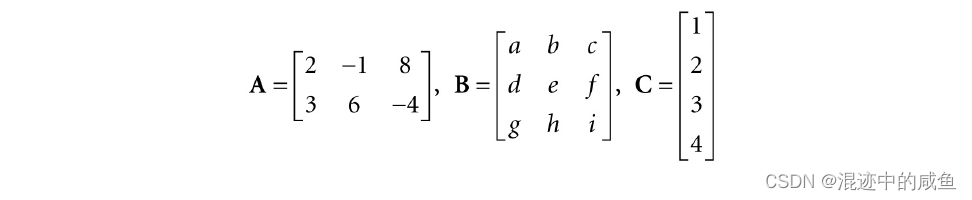
上面提到,通过互换矩阵的行和列来求出转置矩阵,于是有:
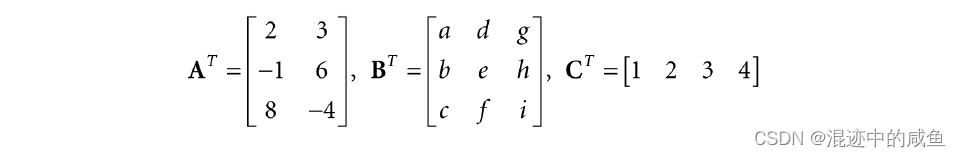
转置矩阵具有下列实质性质:
1. ( A + B ) T = A T + B T 1. (A + B)^T = AT + B^T 1.(A+B)T=AT+BT
2. ( c A ) T = c A T 2. (cA)^T = cA^T 2.(cA)T=cAT
3. ( A B ) T = B T A T 3. (AB)^T = B^TA^T 3.(AB)T=BTAT
4. ( A T ) T = A 4. (AT)^T = A 4.(AT)T=A
5. ( A − 1 ) T = ( A T ) − 1 5. (A−1)^T = (A^T)−1 5.(A−1)T=(AT)−1
单位矩阵
单位矩阵比较特殊,即其对角线元素均为 1 \;1\; 1,其余均为 0 \;0\; 0的方阵,列如:

单位矩阵是矩阵乘法的单位元,即:
如果 A \;A\; A为 m × n \;m×n\; m×n矩阵, B \;B\; B为 n × p \;n×p\; n×p矩阵,而I为 n × n \;n×n\; n×n矩阵,那么:
A I = A AI=A AI=A且 I B = B IB=B IB=B
换句话说,任何矩阵与单位矩阵相乘,得到的依然是原矩阵。如果 M \;M\; M是一个方阵,那么它与单位矩阵满足乘法交换律:
M I = I M = M MI=IM=M MI=IM=M
矩阵的行列式
行列式是一种特殊的函数,它以方阵作为输入,并输出一个实数。方阵 A \;A\; A的行列式记作 d e t A \;det \;A\; detA。
学习的用法与意义:
行列式反应了线性变化下,( n \;n\; n维多面体) 体积变化的相关信息(二维列外,它反应的是平行四边形面积的变化);
行列式也用于线性方程组的克莱姆法则( C r a m e r ’ s R u l e Cramer’s Rule Cramer’sRule,亦称克莱默法则);
我们在此学习是利用它推导逆矩阵公式;
此外行列式还可以用于证明:方阵是 A \;A\; A是可逆的,当且仅当 d e t A ≠ 0 \;det \;A≠0\; detA=0。
在此之前我们还需要先学习一下余子阵。
余子阵
指定一个 m × n \;m×n\; m×n的矩阵 A \;A\; A,余子阵 A ‾ i j \overline{A}_{ij} Aij即为 A \;A\; A中去除低 i \;i\; i行 j \;j\; j列的 ( n − 1 ) × ( n − 1 ) \;(n-1)×(n-1)\; (n−1)×(n−1)的矩阵
例:
求出下列矩阵的余子阵 A ‾ 11 \overline{A}_{11} A11、 A ‾ 22 \overline{A}_{22} A22和 A ‾ 13 \overline{A}_{13} A13

则分别有:
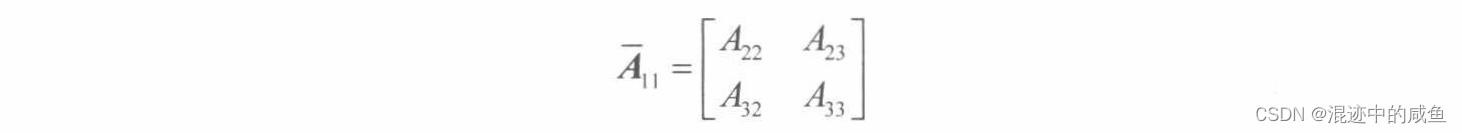
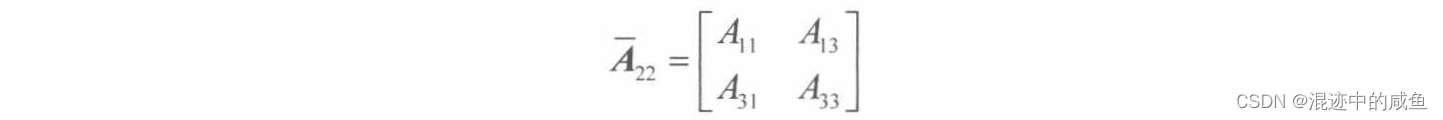
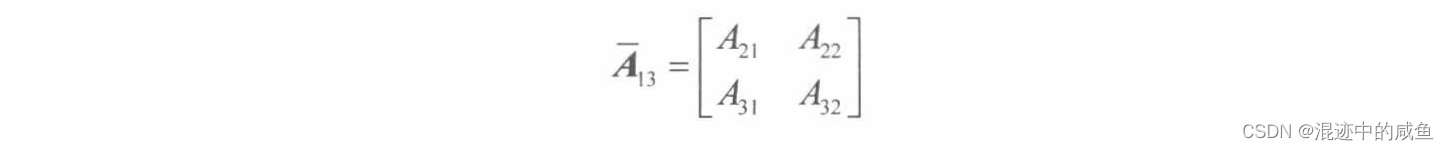
行列式的定义
矩阵的行列式有一种递归定义。例如, 4 × 4 \;4×4\; 4×4的矩阵要根据 3 × 3 \;3×3\; 3×3的矩阵, 3 × 3 \;3×3\; 3×3要 2 × 2 \;2×2\; 2×2, 2 × 2 \;2×2\; 2×2要 1 × 1 \;1×1\; 1×1的来定义。( 1 × 1 \;1×1\; 1×1矩阵 A = [ A 11 ] A=[A_{11}] A=[A11]的行列式被简单的定义为 d e t [ A 11 ] = A 11 det[A_{11}]=A_{11} det[A11]=A11)。
设 A \;A\; A为 m × n \;m×n\; m×n矩阵。那么,当 n > 1 \;n>1\; n>1时,我们定义:
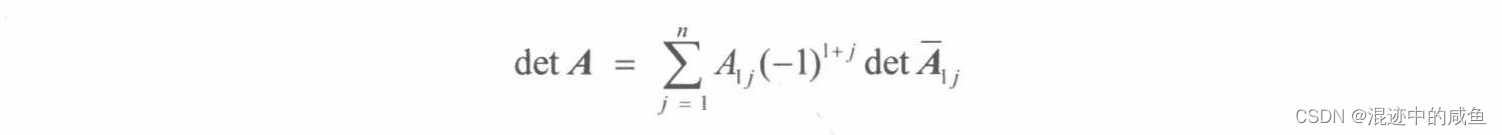
则对于 2 × 2 \;2×2\; 2×2矩阵来说,其相应的行列式公式为:

则对于 3 × 3 \;3×3\; 3×3矩阵来说,其相应的行列式公式为:

则对于 4 × 4 \;4×4\; 4×4矩阵来说,其相应的行列式公式为:
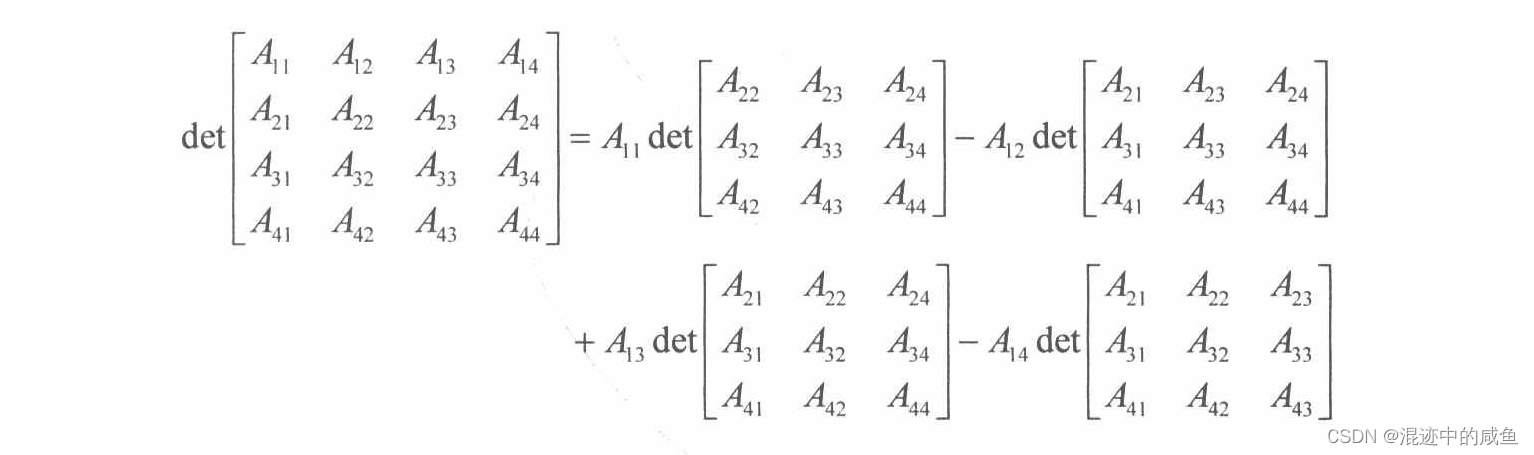
在 3 D 3D 3D图形学中主要使用 4 × 4 \;4×4\; 4×4矩阵,因此推导到此就足够了。
列:

伴随矩阵
设 A A A为一个 m × n \;m×n\; m×n矩阵。乘积 C i j = ( − 1 ) i + j d e t A ‾ i j C_{ij}=(-1)^{i+j}det\overline{A}_{ij} Cij=(−1)i+jdetAij称为元素 A ‾ i j \overline{A}_{ij} Aij的代数余子式如果矩阵 A A A中的每个元素分别计算出 C i j C_{ij} Cij,并将它置于矩阵 C A C_A CA中第 i i i行、第 j j j列的相应位置,那么将获得矩阵 A A A的代数余子式矩阵:
若取矩阵 C A C_A CA的转置矩阵,将会得到矩阵A的伴随矩阵,记作:
A ∗ = C A T A^*=C_A^T A∗=CAT
接下来我们用伴随矩阵计算逆矩阵
逆矩阵
矩阵代数不存在除法运算的概念,但是却另外定义了一种矩阵乘法的逆矩阵。下面总结了与矩阵逆运算有关信息:
1.只有方阵才具备逆矩阵。因此,当提到逆矩阵时,我们便假设要处理的是一个方阵;
2. n × n n×n n×n矩阵 M M M的逆矩阵也是一个 n × n n×n n×n的矩阵,并表示为 M − 1 M^{-1} M−1;
3.不是每个方阵都有逆矩阵。存在逆矩阵的方阵称为可逆矩阵,不存在逆矩阵的方阵叫奇异矩阵;
4.可逆矩阵的逆矩阵时唯一的;
5.矩阵与其逆矩阵相乘将得到单位方阵: M M − 1 = M − 1 M = I MM^−1 = M^{−1}M =I MM−1=M−1M=I,可以发现矩阵与其逆矩阵的乘法运算满足交换律;

下面就是逆矩阵的计算公式: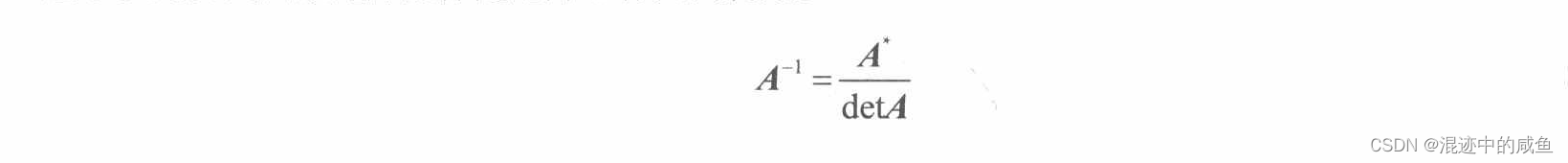
逆矩阵的乘积的逆:
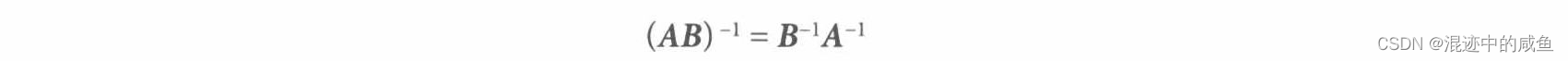
用DirectXMath库处理矩阵
为了对点与向量进行变换,就要借助 1 × 4 1×4 1×4行向量以及 4 × 4 4×4 4×4矩阵。
DirectXMath.h中的XMMATRIX表示 4 × 4 4×4 4×4矩阵
#if (defined(_M_IX86) || defined(_M_X64) ||
defined(_M_ARM)) && defined(_XM_NO_INTRINSICS_)
struct XMMATRIX
#else
__declspec(align(16)) struct XMMATRIX
#endif
{
// 用4个XMVECTOR来表示矩阵,借此使用SIMD技术
XMVECTOR r[4];
XMMATRIX() {
}
XMMATRIX(FXMVECTOR R0, FXMVECTOR R1, FXMVECTOR R2,
CXMVECTOR R3)
{
r[0] = R0; r[1] = R1; r[2] = R2; r[3] = R3; }
XMMATRIX(float m00, float m01, float m02, float m03,
float m10, float m11, float m12, float m13,
float m20, float m21, float m22, float m23,
float m30, float m31, float m32, float m33);
explicit XMMATRIX(_In_reads_(16) const float
*pArray);
XMMATRIX& operator= (const XMMATRIX& M)
{
r[0] = M.r[0]; r[1] = M.r[1]; r[2] = M.r[2];
r[3] = M.r[3]; return *this; }
XMMATRIX operator+ () const {
return *this; }
XMMATRIX operator- () const;
XMMATRIX& XM_CALLCONV operator+= (FXMMATRIX M);
XMMATRIX& XM_CALLCONV operator-= (FXMMATRIX M);
XMMATRIX& XM_CALLCONV operator*= (FXMMATRIX M);
XMMATRIX& operator*= (float S);
XMMATRIX& operator/= (float S);
XMMATRIX XM_CALLCONV operator+ (FXMMATRIX M)
const;
XMMATRIX XM_CALLCONV operator- (FXMMATRIX M)
const;
XMMATRIX XM_CALLCONV operator* (FXMMATRIX M)
const;
XMMATRIX operator* (float S) const;
XMMATRIX operator/ (float S) const;
friend XMMATRIX XM_CALLCONV operator* (float S,
FXMMATRIX M);
};
与向量类似,DX文档也建议我们用XMFLOAT4X4来存储类中矩阵类型成员
struct XMFLOAT4X4
{
union
{
struct
{
float _11, _12, _13, _14;
float _21, _22, _23, _24;
float _31, _32, _33, _34;
float _41, _42, _43, _44;
};
float m[4][4];
};
XMFLOAT4X4() {
}
XMFLOAT4X4(float m00, float m01, float m02, float
m03,
float m10, float m11, float m12, float m13,
float m20, float m21, float m22, float m23,
float m30, float m31, float m32, float m33);
explicit XMFLOAT4X4(_In_reads_(16) const float
*pArray);
float operator() (size_t Row, size_t Column)
const {
return m[Row][Column]; }
float& operator() (size_t Row, size_t Column) {
return m[Row][Column]; }
XMFLOAT4X4& operator= (const XMFLOAT4X4& Float4x4);
};
通过下列方法将数据从XMFLOAT4X4加载到XMMATRIX:
inline XMMATRIX XM_CALLCONV
XMLoadFloat4x4(const XMFLOAT4X4* pSource);
通过下列方法将数据从XMMATRIX存储到XMFLOAT4X4:
inline void XM_CALLCONV
XMStoreFloat4x4(XMFLOAT4X4* pDestination, FXMMATRIX
M);
矩阵函数
DX库包含了下列矩阵相关使用函数:
XMMATRIX XM_CALLCONV XMMatrixIdentity(); //返回单位矩阵 I
bool XM_CALLCONV XMMatrixIsIdentity(FXMMATRIX M);
XMMATRIX XM_CALLCONV XMMatrixMultiply(FXMMATRIX A,CXMMATRIX B);
XMMATRIX XM_CALLCONV XMMatrixTranspose( FXMMATRIX M); //返回逆矩阵
XMVECTOR XM_CALLCONV XMMatrixDeterminant( FXMMATRIX M); // 返回Det M Det M Det M Det M
XMMATRIX XM_CALLCONV XMMatrixInverse( XMVECTOR* pDeterminant,FXMMATRIX M);//返回逆矩阵 输入Det M Det M Det M Det M
在声明具有XMMATRIX 参数函数时,XMMATRIX 函数中传入的XMVECTOR 需按照上一章节对于向量传入规范使用,XMMATRIX 的使用规范也与XMVECTOR 一致,XMMATRIX第一个参数用FXMMATRIX(first XMMATRIX),其余参数均应为CXMMATRIX。下面的代码展示了再Win32环境,类型定义:
// win32, __fastcall调用约定通过寄存器传递3个XMVECTOR参数,其余的参数存在堆栈上
typedef const XMMATRIX& FXMMATRIX;
typedef const XMMATRIX& CXMMATRIX;
// win32, __vectorcall 调用约定通过寄存器传递6个XMVECTOR参数,其余的参数存在堆栈上.
typedef const XMMATRIX FXMMATRIX;
typedef const XMMATRIX& CXMMATRIX;
从中可以看出,在win32上,__fastcall调用约定中,XMMATRIX类型的参数是不能传至SSE/SSE2寄存器的,因为其默认只支持3个XMVECTOR参数,而它4个。所以矩阵类型数据只能通过堆栈加以引用。(DX官方建议用户总是在构造函数中采用CXMMATRIX类型来获取XMMATRIX参数,而且对于构造函数也不要使用XM_CALLONV注解)
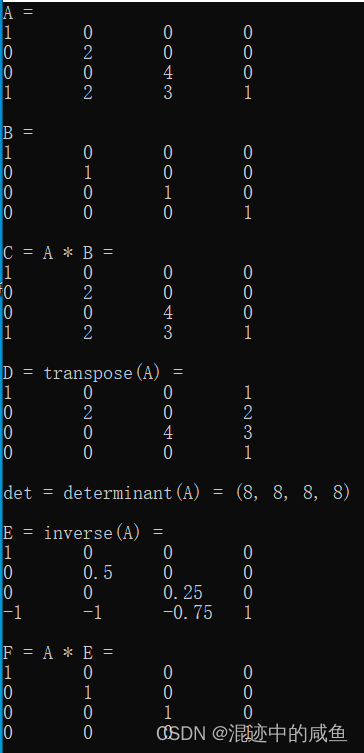
DX代码实例
#include <windows.h> // for XMVerifyCPUSupport
#include <DirectXMath.h>
#include <DirectXPackedVector.h>
#include <iostream>
using namespace std;
using namespace DirectX;
using namespace DirectX::PackedVector;
ostream& XM_CALLCONV operator << (ostream& os,
FXMVECTOR v)
{
XMFLOAT4 dest;
XMStoreFloat4(&dest, v);
os << "(" << dest.x << ", " << dest.y << ", " <<
dest.z << ", " << dest.w << ")";
return os;
}
ostream& XM_CALLCONV operator << (ostream& os,
FXMMATRIX m)
{
for (int i = 0; i < 4; ++i)
{
os << XMVectorGetX(m.r[i]) << "\t";
os << XMVectorGetY(m.r[i]) << "\t";
os << XMVectorGetZ(m.r[i]) << "\t";
os << XMVectorGetW(m.r[i]);
os << endl;
}
return os;
}
int main()
{
if (!XMVerifyCPUSupport())
{
cout << "directx math not supported" << endl;
return 0;
}
XMMATRIX A(1.0f, 0.0f, 0.0f, 0.0f,
0.0f, 2.0f, 0.0f, 0.0f,
0.0f, 0.0f, 4.0f, 0.0f,
1.0f, 2.0f, 3.0f, 1.0f);
XMMATRIX B = XMMatrixIdentity();
XMMATRIX C = A * B;
XMMATRIX D = XMMatrixTranspose(A);
XMVECTOR det = XMMatrixDeterminant(A);
XMMATRIX E = XMMatrixInverse(&det, A);
XMMATRIX F = A * E;
cout << "A = " << endl << A << endl;
cout << "B = " << endl << B << endl;
cout << "C = A * B = " << endl << C << endl;
cout << "D = transpose(A) = " << endl << D << endl;
cout << "det = determinant(A) = " << det << endl <<
endl;
cout << "E = inverse(A) = " << endl << E << endl;
cout << "F = A * E = " << endl << F << endl;
return 0;
}
运行结果: