Oh,no 过拟合!

训练集错误率都到0.4了,验证集还是停留在3.7~2.7之间震荡,振幅还不小。
玩这个人工智能最怕的就是这三个字,损失函数一直震荡不肯往下走,虽然有很多办法来降低过拟合。
但其实最重要的办法还是增加数据质量,这个数据质量包含的东西非常多,最关键的就是包含你真正希望的数据。
常规操作如下
- 增加drop层,给网络增加随机性。(调整网络结构来规避过拟合问题我觉得用处不大)
- 增加数据质量
- 图片增广
1.数据质量增强
我决定研究一下图片结构,还真发现了一些有意思的地方。这个发现让我觉得有门。

是的你们笑的很灿烂,但是可惜对不起了。

我对他们下手了,中间这个小姑娘,你赢了,你做到了人狗一体。
因为有将近1万张图片,所以还是要借助工具。我拿出了MaskRCNN来做这个狗狗的聚焦。
MASKRCNN大法,我对MASKRCNN进行改装,让他可以刚我进行如下的切割:

能够把切割完成的狗单独搞出来,上图是最效果最好的一张。对狗进行分类,然后框图切割。每一个都切出来。
需要说明的是MASKRCNN能区分大约80中分类,狗是其中的一种,我用他来标出狗,并切出来,显然效果很好。
用了大约1小时,数据整理完毕。
下面我是做的处理前后的一些对比。

可以发现,左边的照片中有了一个半老徐娘和一只狗,显然我只关心狗。所以我把人删了,对不起这不是人脸识别系统。而且这也不是我的品位,所以……有点扯远了。
做完图片质量提升,我迫不及待的做了一下训练。
316/316 [==============================] - 147s 467ms/step - loss: 0.04788 - val_loss: 1.7138
这是最后的结果,错误率在1.7左右震荡再也不肯下了。
总之提升了将近一倍,还是很有效的。我的数据集只有10,000张图片122个分类,每个分类还分不到10张。这是个极大地问题。
我要增加数据集。于是有了下面这篇文章。
2.找互联网要数据
麦克引擎:下载BD图片其实可以很直接,反思,有时候我们太依赖引擎了
从网上下载的数据良莠不齐,而且每一类的数据情况还都不太一样。下面这个是美国可卡犬,这已经是分类里效果最好的结果了。大部分图片还都是
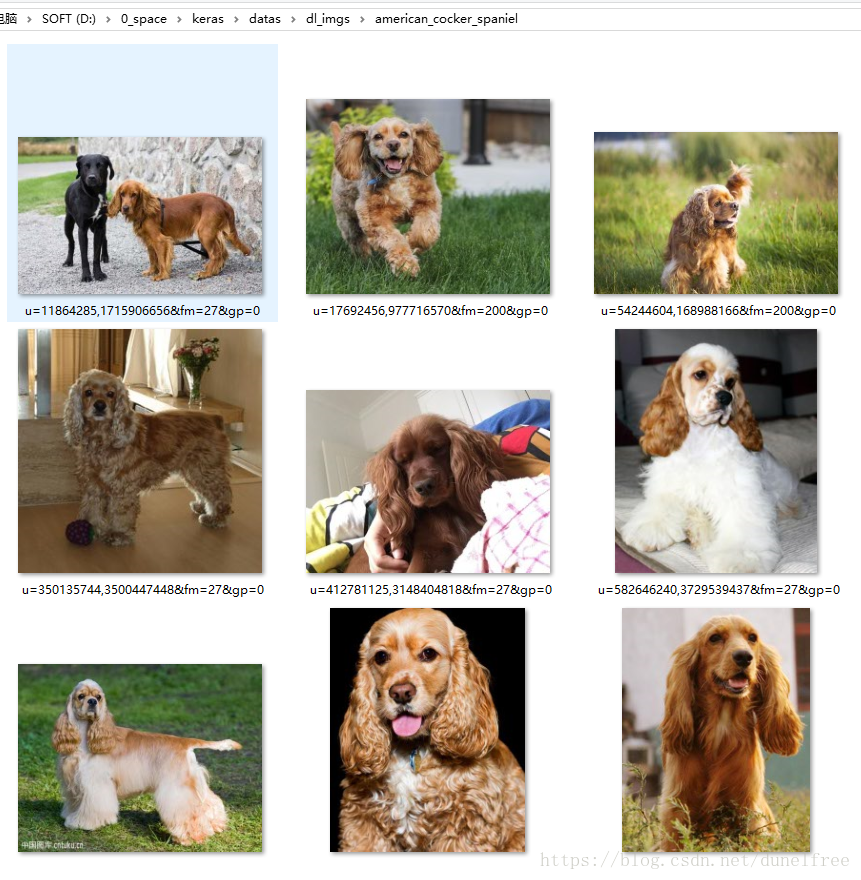
这个是美国可卡犬,这已经是分类里效果最好的结果了。大部分图片还都是对的。
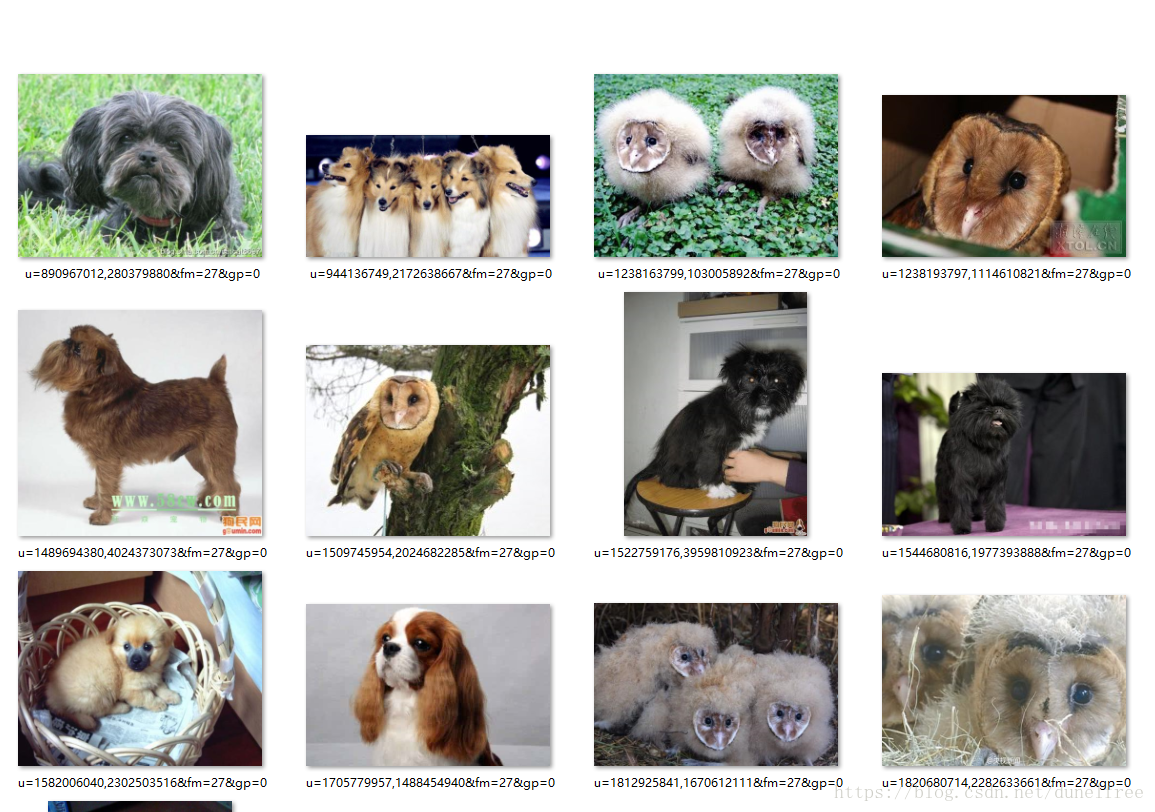
猴头梗目录进入了一些奇怪的物种。

我用MASKRCNN大法进行了过滤,结果有些顽强的猫头鹰留了下来。还有一些苏牧也待在那里,这是自然地,CNN没有对狗狗进行细分。手工删除?这个工作量有点大了。
切割完后,图片漂亮多了,可是还有有一些乱入。这个猫头认成狗了,这个苏牧不应该在这里,看来人肉整理在现阶段还是逃不开。我想做一个识别当前目录中最多分类的模型,后来想想还是我自己把这500个目录过一遍吧,可能更快,更快,更快…
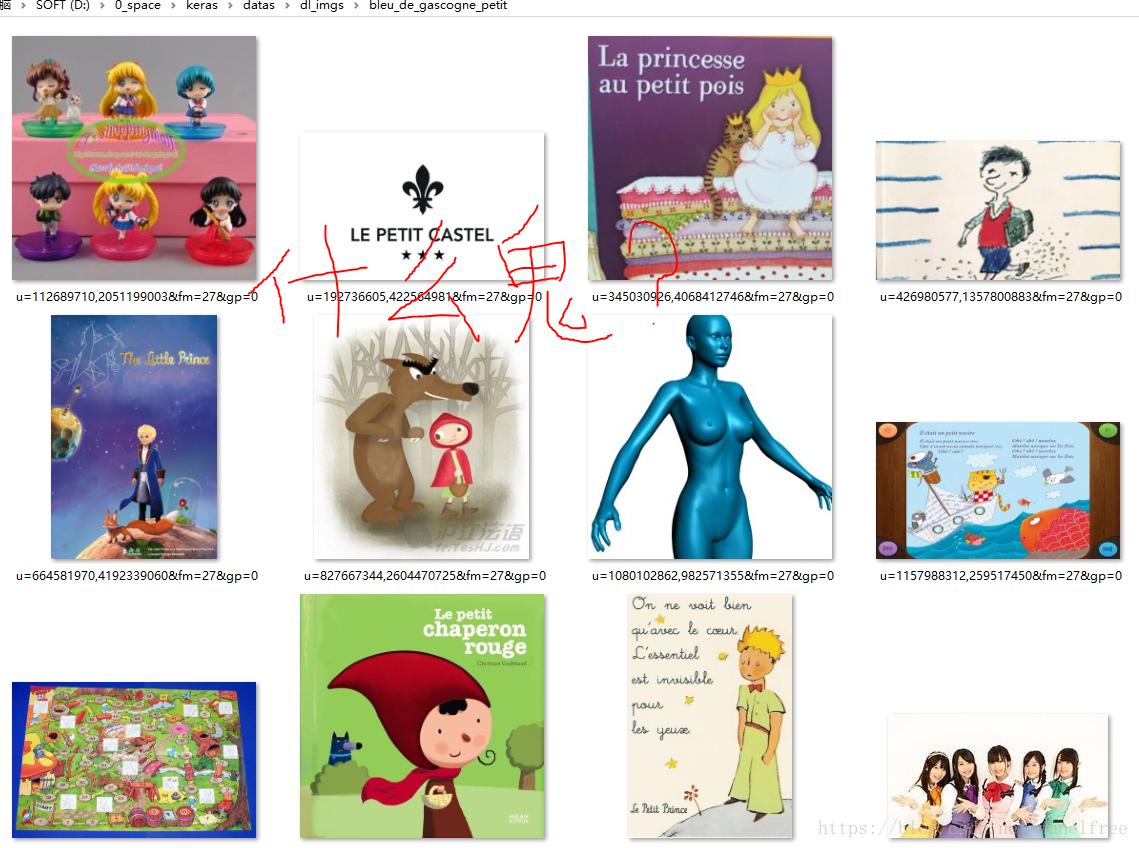
有些分类的图就非常魔幻了。这是蓝色加斯科涅短腿犬。

应该长这样,是不是不认识。对了,我也不认识。搜索引擎更不认识看来,给出了很魔幻的结果。图片搜索?我试过了,效果也挺魔幻,毕竟图像检索还真不是做这个的。
大批量的标签数据看来还是得想办法再多搞点啊。