1 导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
from collections import Counter
from sklearn.datasets import make_blobs, make_circles, make_moons, make_classification
from sklearn.cluster import KMeans, MiniBatchKMeans, DBSCAN, AgglomerativeClustering, MeanShift
from sklearn.decomposition import PCA
from sklearn.metrics import adjusted_rand_score, silhouette_score
2 构建数据
step1:使用sklearn自带的函数make_blobs()、make_circlues()、make_moons()、make_classification()构建数据集
step2:绘制二维散点图
step3:定义绘图函数便于下面使用,为了避免估计的标签类别数少于实际类别数导致计算轮廓系数报错,故加上try-except语句
# 生成数据集
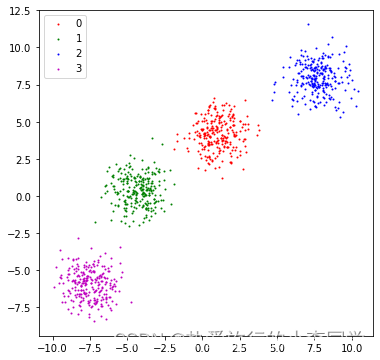
X1, y1 = make_blobs(n_samples=1000, n_features=2, centers=4, shuffle=True, random_state=3)
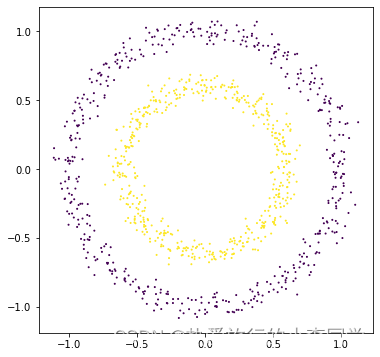
X2, y2 = make_circles(n_samples=1000, noise=0.05, factor=0.6, shuffle=True, random_state=0)
X3, y3 = make_moons(n_samples=1000, noise=0.05, shuffle=True, random_state=0)
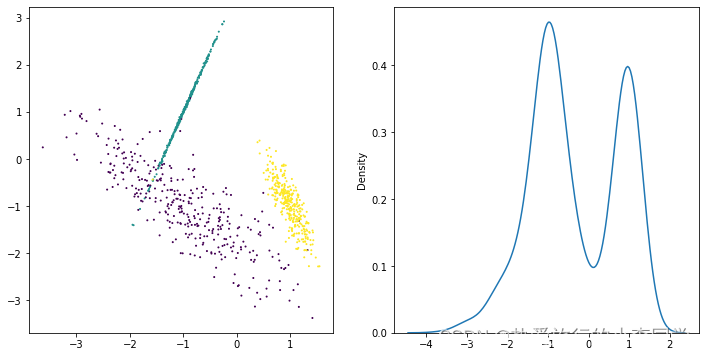
X4, y4 = make_classification(n_samples=1000, n_features=2, n_classes=3, n_redundant=0, n_repeated=0, n_clusters_per_class=1, shuffle=True, random_state=5)
# 绘制图
# 1
dataset1 = pd.DataFrame({
"x1": X1[:, 0], "x2": X1[:, 1], "label": y1})
plt.figure(figsize=(6, 6))
grouped = dataset1.groupby('label')
colors = ['r', 'g', 'b', 'm']
for label, df in grouped:
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=colors[label], s=1, label=label)
plt.legend()
plt.show()
# 2
plt.figure(figsize=(6, 6))
plt.scatter(X2[:, 0], X2[:, 1], c=y2, s=1)
plt.show()
# 3
plt.figure(figsize=(6, 6))
plt.scatter(X3[:, 0], X3[:, 1], c=y3, s=1)
plt.show()
# 4
plt.rcParams['figure.figsize'] = (12, 6)
plt.subplots(1, 2)
plt.subplot(1, 2, 1)
plt.scatter(X4[:, 0], X4[:, 1], c=y4, s=1)
plt.subplot(1, 2, 2)
sns.kdeplot(x=X4[:, 0])
plt.show()
# 打印预测的散点图
def plot_predict_scatters(datas):
plt.rcParams['figure.figsize'] = (16, 16)
plt.subplots(2, 2)
for i, data in enumerate(datas):
x, y, y_predict = data
plt.subplot(2, 2, i + 1)
plt.scatter(x[:, 0], x[:, 1], c=y_predict, s=1)
rand_score = adjusted_rand_score(y, y_predict)
try:
sil_score = silhouette_score(x, y_predict)
except Exception as e:
warnings.warn(message=str(e))
sil_score = None
plt.title('Figure %d: rand_score=%.2f' % (i + 1, rand_score))
if sil_score != None:
plt.title('Figure %d: rand_score=%.2f sil_score=%.2f' % (i + 1, rand_score, sil_score))
plt.show()
展示:
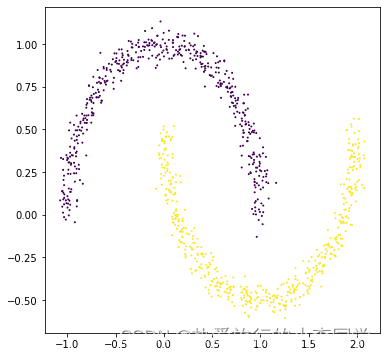
3 模型对比
Kmeans
# KMeans聚类
y_predict11 = KMeans(n_clusters=4).fit_predict(X1)
y_predict12 = KMeans(n_clusters=2).fit_predict(X2)
y_predict13 = KMeans(n_clusters=2).fit_predict(X3)
y_predict14 = KMeans(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict11),
(X2, y2, y_predict12),
(X3, y3, y_predict13),
(X4, y4, y_predict14)]
plot_predict_scatters(datas)
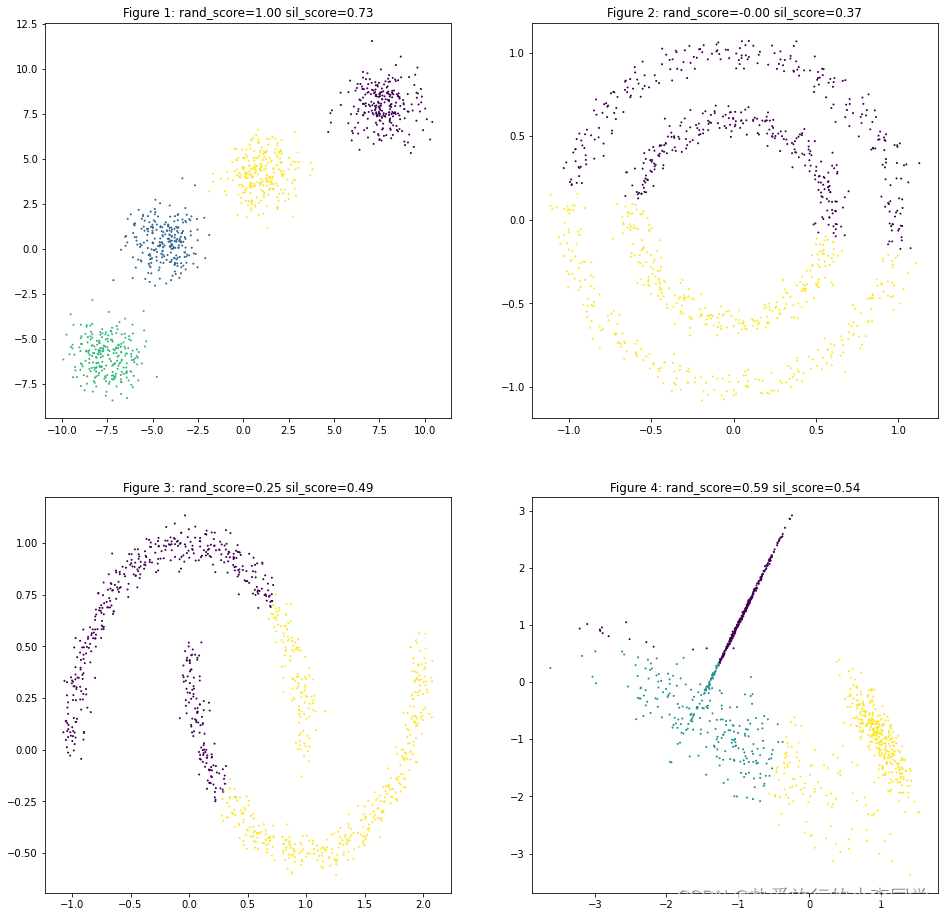
MiniBatchKmeans
# MnniBatch聚类
y_predict21 = MiniBatchKMeans(n_clusters=4).fit_predict(X1)
y_predict22 = MiniBatchKMeans(n_clusters=2).fit_predict(X2)
y_predict23 = MiniBatchKMeans(n_clusters=2).fit_predict(X3)
y_predict24 = MiniBatchKMeans(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict21),
(X2, y2, y_predict22),
(X3, y3, y_predict23),
(X4, y4, y_predict24)]
plot_predict_scatters(datas)
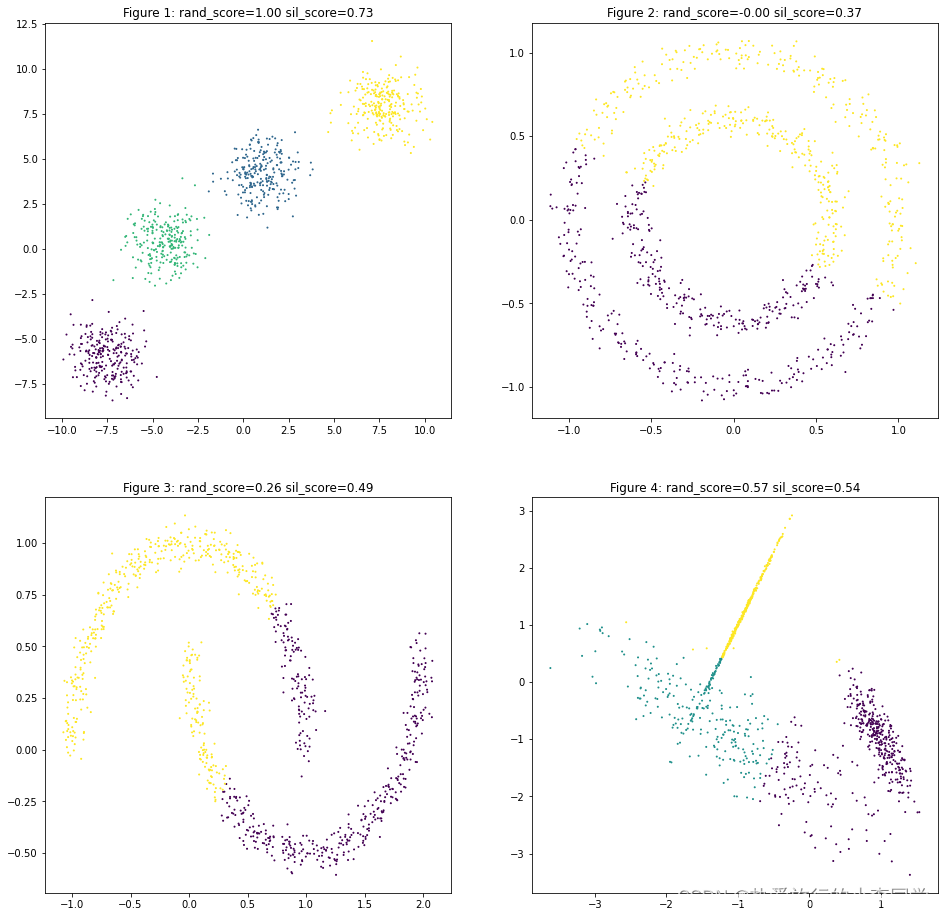
DBSCAN
# DBSCAN聚类
y_predict31 = DBSCAN(eps=1.0, min_samples=10).fit_predict(X1)
y_predict32 = DBSCAN(eps=0.2, min_samples=50).fit_predict(X2)
y_predict33 = DBSCAN(eps=0.2, min_samples=20).fit_predict(X3)
y_predict34 = DBSCAN(eps=0.1, min_samples=10).fit_predict(X4)
datas = [(X1, y1, y_predict31),
(X2, y2, y_predict32),
(X3, y3, y_predict33),
(X4, y4, y_predict34)]
plot_predict_scatters(datas)
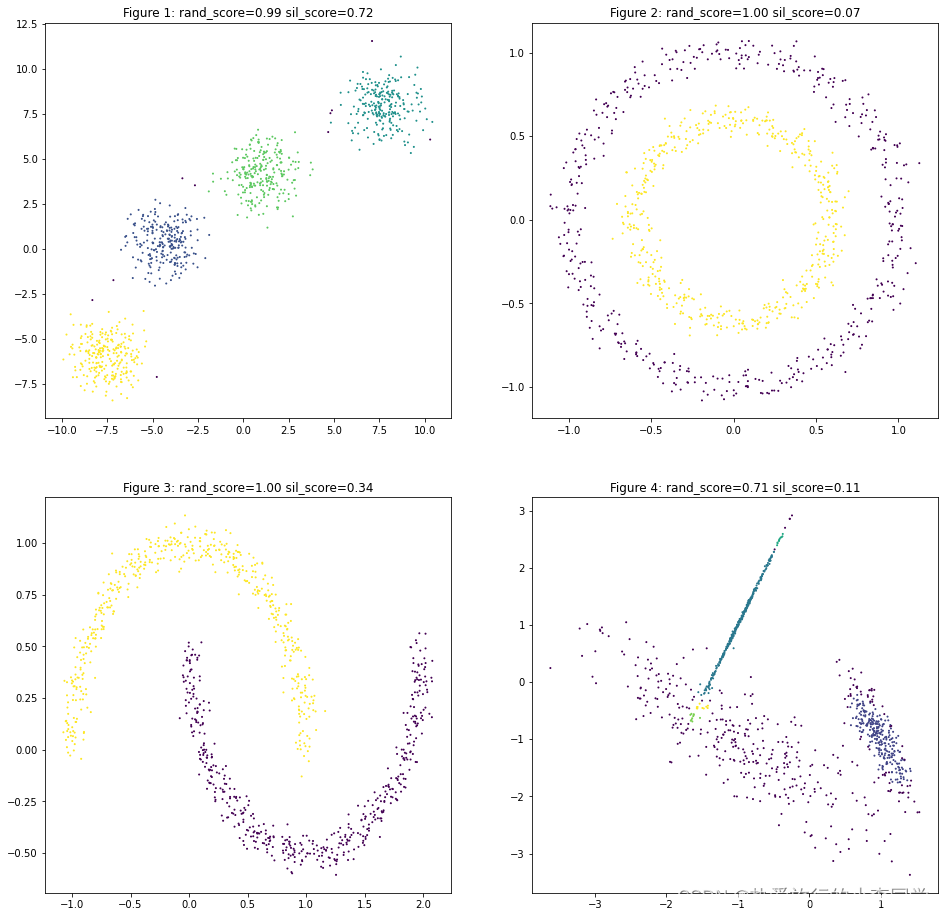
DBSCAN对第2类、第3类、第4类聚类效果均好于KMeans,不过需要适当的调参。
AgglomerativeClustering
# 层次聚类
y_predict41 = AgglomerativeClustering(n_clusters=4).fit_predict(X1)
y_predict42 = AgglomerativeClustering(n_clusters=2).fit_predict(X2)
y_predict43 = AgglomerativeClustering(n_clusters=2).fit_predict(X3)
y_predict44 = AgglomerativeClustering(n_clusters=3).fit_predict(X4)
datas = [(X1, y1, y_predict41),
(X2, y2, y_predict42),
(X3, y3, y_predict43),
(X4, y4, y_predict44)]
plot_predict_scatters(datas)
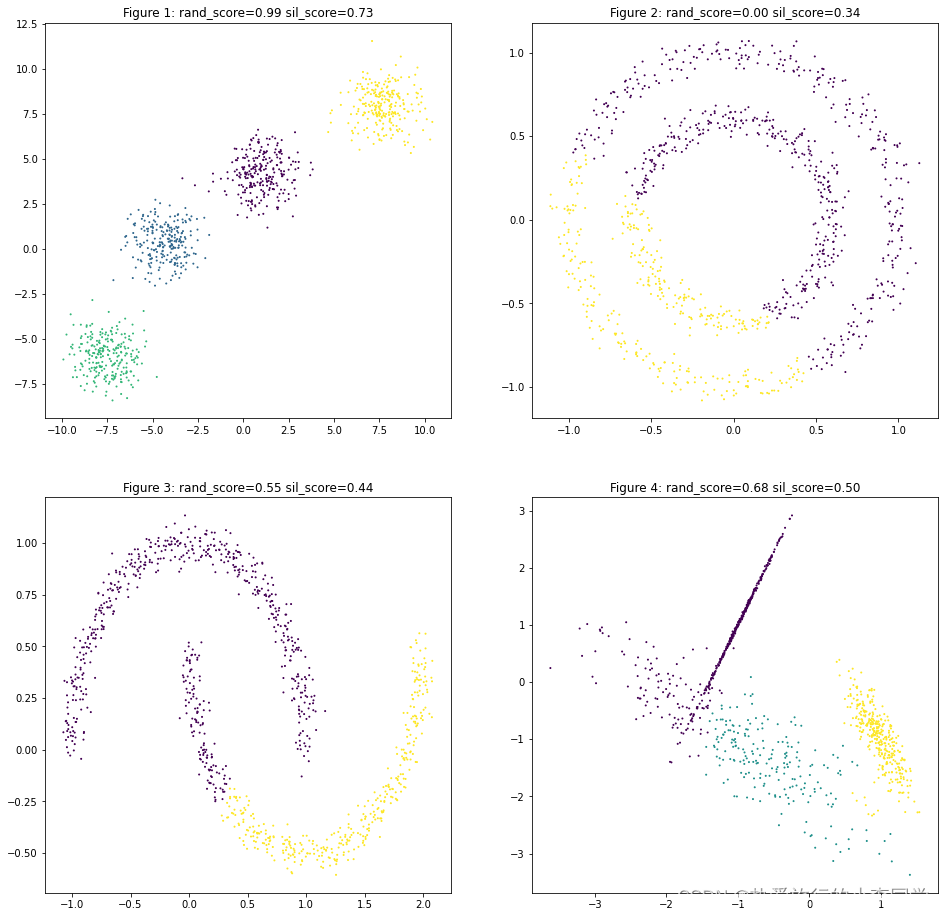
MeanShift
# MeanShift
y_predict51 = MeanShift(bandwidth=1).fit_predict(X1)
y_predict52 = MeanShift().fit_predict(X2)
y_predict53 = MeanShift().fit_predict(X3)
y_predict54 = MeanShift().fit_predict(X4)
datas = [(X1, y1, y_predict51),
(X2, y2, y_predict52),
(X3, y3, y_predict53),
(X4, y4, y_predict54)]
plot_predict_scatters(datas)
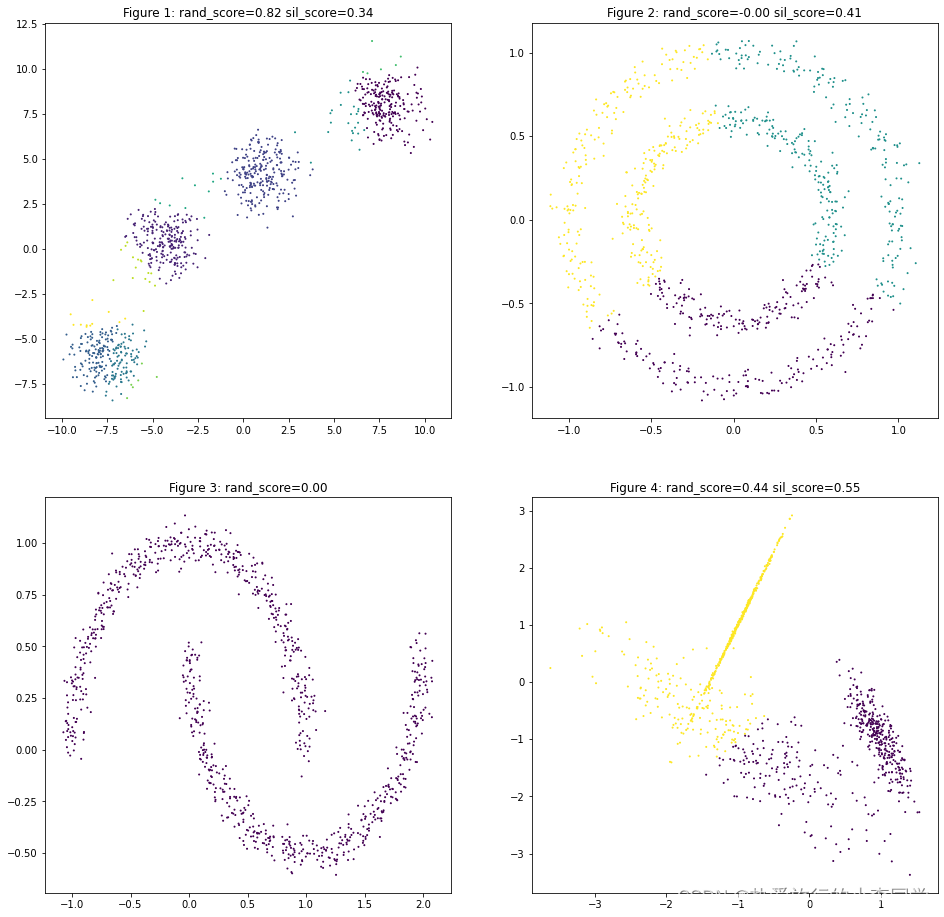
可以观察到MeanShift对第3类数据聚类结果只聚为了1类,因此兰德指数为0,轮廓系数无法计算。
4 总结
聚类的评价指标
兰德指数:计算真实标签与聚类标签两种分布相似性之间的相似性,取值范围为 [0,1]
轮廓系数:是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。 它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。取值范围:[-1,1],轮廓系数越大,聚类效果越好