前言
6.7 。很长一段我没有更新学习笔记,因为在这段时间里,我真的没有认真学,所以没有力气去总结。忙什么不重要,重要的是我将面对什么。
我将面对一个麻烦,如何补上进度。
因此本轮,本周我将面对一个挑战如何用最短的时间,学完,写完,学会。希望我锻炼的方法,对更多的人也有用。现在我将开始计时,结束时我将统计总共花费的时间。
采用的方法:
- 首先2倍速快进全部视频,在用百度预习的前提下把基础部分过完,其中如果有听不懂的部分,记录时间书签,在这个过程中写下大纲
- 其次预习全部习题,如果所有题目都看一遍分为会和不会两部分,会部分,视频可以2倍速跳着看,不会的部分1.2倍速或者原速度看。
- 再三题解时,不会做的题目,有意思的题目写解题思路,并尽可能的提供代码,会做的题目,尽量概括。
- 最后回顾,补全大纲。
(试试这种方法吧,现在开始,本课视频长4h)
2-3 并查集(Union-find)及经典问题
并查集
概念
- 并查集是一种方法,通常以工具类的方式活跃于代码中。
- 并查集用于处理判断两个元素是否属于同一集合(find方法)
- 并查集用于两元素所在集合合并,使得这两个集合联通(merge方法)
基础算法Quick-find算法,染色法
在面对如何去区分不同集合的问题时,有一套基础的方法被提出,那就是给定一个额外维度,令这些集合在这个额外维度上的代号不同,而集合内部的元素则在额外维度上的代号相同,使得任意元素可以根据这个额外维度的值来判断是否是相同的元素。
这个额外的维度,被称为颜色。
而合并两个集合时,采用的方式是将其中一个集合的代表元素的颜色染成另一个集合的代表颜色(此处用染色方式的原因是,不清楚其他的颜色是否被使用,只能确定这两个颜色被使用,因此舍弃一个颜色,用一个颜色来统帅这个新的集合,所以称为染色)
示例代码:
class UnionSet{
private int [] color;
private int n;
public UnionSet(int n){
this.n = n;
color = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
color [i] = i; //对维度(颜色)进行初始化
}
}
public int find(int n){ //查找元素的颜色
return color [n];
}
public void merge (int a,int b){
int cb = color[b]; //获取用于被覆盖的颜色
if(color[a] == cb ) return; //相同颜色不需要合并
for(int i = 0;i<= n;i++){
if(color [i] == cb)
color [i] = color[a];//对维度(颜色)覆盖(低性能的原因)
}
}
}
后面会讲一个Quick-Union方法的扁平化优化,看起来跟这套染色法很像都是尽可能的让元素指向一个元素作为集合的区分概念,但是二者根本性的问题在于,染色法的颜色是一个不可继承的目标向量,因此染色时需要将一个集合内所有的元素全部改变为另一个。
而扁平化则是指向一个元素,合并集合时,只修改一个元素即可。具体的下面会描述。
树结构算法Quick-Union算法,树结构
上面说了简单易懂的染色法,但是缺点很明显,当集合合并时,需要对一个集合的所有元素进行处理。
那能否改为只为一个呢?
可以,这里需要借用树结构,树结构就是以一个根来定义一套集合的方式
(但是本次的树都是反向的树,因为正常的树都是根指向孩子节点,而此处的树则是期望孩子节点能找到父节点,因此实际上是一个无环路的图结构,但是为了方便描述还是称为树,但是节点的指向关系相反)
以树结构进行管理时,由于有根的存在,只需要判断元素的根是否相同就可以以此获取两组元素是否从属于于同一个集合。而当合并集合时,只需要将一个集合的父节点接在另一个集合的根节点下即可(或者直接接在另一颗树的当前节点下)
示例代码:
(下方代码为接在根节点下)
class UnionSet{
private int [] fa;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
return find (fa[x] );
}
public void merge (int a,int b){
int finda = find(a);
int findb = find(b);
if(finda == findb ) return; //相同根不需要合并
fa[finda] = findb; //有待优化
}
}
Weighted-Quick-Union算法,权重优化,安置优化
合并集合时虽然选择接在根节点下已经初步优化了一段性能,但是选择哪棵树的根作为最后的根也是有考量的,这份考量的因素就是最终树的平均节点查询时间。也就是最终合并的树查询一个节点的根节点的平均时间。
根据理论和实验(直接说结论)让节点数目更多的树的根作为最终的根能让生成的最终平均查询时间更短
这种优化方案表现在方法(merge方法)中:
class UnionSet{
private int [] fa;
private int [] size;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
size = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
size[i] = 1; //对当前树高进行记录
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
return find (fa[x] );
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
if(size[ra]<size[rb]){ //如果B树更大
fa[ra] = rb; //A接入B树下
size[rb] += size[ra];
}else{
fa[rb] = ra; //B接入A树下
size[ra] += size[rb];
}
}
}
PathCompression-Quick-Union算法路径压缩优化
树的合并是一种优化策略,但是树结构本身也是可以优化的,由于判断是否同一树的依据只看根,而影响性能(平均查找次数的)的主要是树高,因此如果能让树高降低,那么性能提高。
这种优化的方案表现在方法(find方法)中:
public int find(int x){ //查找根
if(fa[x] == x ) return x;
int root = find (fa[x] ); //将节点接到根上
fa[x] = root;
return root;
}
性能对比
这两种优化方案由于作用于不同的方法因此实际上是可以共存的,在课上的对比中,双重优化和采用任何一种单一优化的策略性能都是接近的,但是都优于染色法(Quick-find),染色法则优于没有优化的Quick-Union
但是在编程时,路径压缩算法的改进代码非常简单,因此很适合在快速开发(竞赛)中进行使用
(下方习题中也一并使用这个作为工具类)
示例:
class UnionSet{
private int [] fa;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
int root = find (fa[x] ); //将节点接到根上
fa[x] = root;
return root;
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
fa[ra] = rb; //A接入B树下
}
}
基础题目
LeetCode-547. 省份数量
链接:https://leetcode-cn.com/problems/number-of-provinces
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例1:
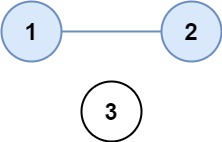
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]]
输出:2
解题思路
本题为简单题,从难度上是不值得描述的,但是可以用于演示PC-Quick-Union(路径压缩并查集算法)。
本题的解题思路为将相连通的城市定义为省份,不同省份间不连通,因此省份就是集合,本题就是求有几个联通集合。
示例代码
(演示UnionSet的简单使用)
class Solution {
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionSet US = new UnionSet(n);
for(int i = 0;i<n;i++){
for(int j= 0;j<n;j++){
if(isConnected [i][j] ==1){
US.merge(i,j);
}
}
}
int res = 0;
for(int i = 0;i<n;i++){
int root = US.find(i);
if(root == i){
res++;
}
}
return res;
}
class UnionSet{
private int [] fa;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
int root = find (fa[x] ); //将节点接到根上
fa[x] = root;
return root;
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
fa[ra] = rb; //A接入B树下
}
}
}
LeetCode-200. 岛屿数量
链接:https://leetcode-cn.com/problems/number-of-islands
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
解题思路
本题的难点在于记录联通关系,对此可以对于岛屿进行标号,然后循环查询岛屿和其他岛屿是否相连,由此生成1对1的联通关系,再根据这个关系使用merge方法进行并查集,最后统计有几个集合即可
(代码略)
LeetCode-990. 等式方程的可满足性(有趣)
链接:https://leetcode-cn.com/problems/satisfiability-of-equality-equations
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:“a==b” 或 “a!=b”。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
示例 1:
输入:["a==b","b!=a"]
输出:false
解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。
示例 2:
输入:["b==a","a==b"]
输出:true
解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。
示例 3:
输入:["a==b","b==c","a==c"]
输出:true
示例 4:
输入:["a==b","b!=c","c==a"]
输出:false
示例 5:
输入:["c==c","b==d","x!=z"]
输出:true
提示:
1. 1 <= equations.length <= 500
2. equations[i].length == 4
3. equations[i][0] 和 equations[i][3] 是小写字母
4. equations[i][1] 要么是 '=',要么是 '!'
5. equations[i][2] 是 '='
解题思路
本题的难点就在于找矛盾,因此首先根据相等关系,将相等的字母所在集合合并,然后再用不相等的语句去判断是否真的不相等(不属于同一个集合),如果发现等式明文被定义不相等,但是实际上相等则认为矛盾,返回false。其余情况返回true;
本地考察的是判断一组元素是否属于同一集合的方式;
(代码略)
总结
通过以上三题,初步了解了并查集在解决问题时的作用:
作为一种处理连通性关系的工具
并查集进阶
LeetCode-684. 冗余连接 (有趣)
链接:https://leetcode-cn.com/problems/redundant-connection
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例 1:
输入: [[1,2], [1,3], [2,3]]
输出: [2,3]
解释: 给定的无向图为:
1
/ \
2 - 3
示例 2:
输入: [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
解释: 给定的无向图为:
5 - 1 - 2
| |
4 - 3
解题思路
本题的切入点在于利用附加的边,在本题中,有边就表示这两个集合联通,当这两个集合已经联通时,那么此时试图添加的边就多余了。由于题意表示需要输出最后的一条边,因此只需要在试图建立新的联通关系时,判断当前是否已经从属同一集合即可,如果有就准备输出,并且覆盖上一次的试图输出值即可
示例代码
(依然很简单)
class Solution {
public int[] findRedundantConnection(int[][] edges) {
int size = edges.length;
UnionSet US = new UnionSet(size);
for(int i= 0;i<size;i++){
int a = edges[i] [0];
int b = edges[i] [1];
if( US.find(a)!= US.find(b)){
US.merge(a,b);
}else{
return new int [] {a,b};
}
}
return null;
}
class UnionSet{
private int [] fa;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
int root = find (fa[x] ); //将节点接到根上
fa[x] = root;
return root;
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
fa[ra] = rb; //A接入B树下
}
}
}
LeetCode-1319. 连通网络的操作次数 (有趣)
链接:https://leetcode-cn.com/problems/number-of-operations-to-make-network-connected
用以太网线缆将 n 台计算机连接成一个网络,计算机的编号从 0 到 n-1。线缆用 connections 表示,其中 connections[i] = [a, b] 连接了计算机 a 和 b。
网络中的任何一台计算机都可以通过网络直接或者间接访问同一个网络中其他任意一台计算机。
给你这个计算机网络的初始布线 connections,你可以拔开任意两台直连计算机之间的线缆,并用它连接一对未直连的计算机。请你计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 -1 。
示例 2:
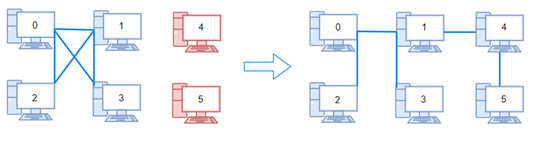
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]
输出:2
解题思路
本题很简单。
首先是统计有几个集合,就可以计算出构成当前集合最少线数目,应该为总台数a减去集合的数目b(a-b)。
然后再考虑当前有多少线,是否能提供多余的线用于联通集合,假设当前的线是C,则用于联通所有集合的线最少就是(a-1),如果c能不少于(a-1),那么所需总线减去当前最少所需总线就是变化所需线数目也就是((a-1)-(a-b)),由此只需计算出有几个集合就可以了。
(代码略)
LeetCode-128. 最长连续序列(有趣)
链接:https://leetcode-cn.com/problems/longest-consecutive-sequence
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
进阶:你可以设计并实现时间复杂度为 O(n) 的解决方案吗?
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
解题思路
本题最简单的方案就是直接排序然后遍历,但是这样就肯定不满足时间复杂度的进阶需求。
因此想要优化时间复杂度,只能用空间换时间,并且只能以固定次数遍历的方式来解题,对此要想到一个检索效率为1的存储策略,hashMap。
然后再是对题目进行概念转换,要求找出数字连续的序列,因此理解为数字连续是一种联通规则,因此可以生成某一个数去期望和其更小的数联通,去期望和其更大的数联通的两个查询条件,如果有联通,没有则等待联通。
综上,得出解题思路为,将数组以下标和值作为键值对关系存入Map,并且要求key为数组的值,以此获得反向的对应关系。然后先遍历一次,每次都期望能在Map中找到前一位和后一位进行集合合并,如果找不到就存入Map。
如此一轮之后,并查集中将包含若干个集合
然后查询并查集类中最大的集合长度即可,本题需要对于工具类做一个微调,使得可以计算最大集合长度。
示例代码
class Solution {
public int longestConsecutive(int[] nums) {
int len = nums.length;
UnionSet US = new UnionSet(len);
HashMap <Integer,Integer> map = new HashMap <Integer,Integer> ();
for(int i=0;i<len;i++){
if(map.get(nums[i])!=null)
continue;
map.put(nums[i],i); //存入
Integer wantLeft = map.get(nums[i]-1);
Integer wantRight = map.get(nums[i]+1);
if(wantLeft!=null){ //如果有则联通
US.merge(wantLeft,i);
}
if(wantRight!=null){ //如果有则联通
US.merge(wantRight,i);
}
}
int res = 0;
for(int i=0;i<len;i++){
if(US.find(i) == i){
res = res>US.getSize(i)?res:US.getSize(i);
}
}
return res;
}
class UnionSet{
private int [] fa;
private int [] size;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
size = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
size [i] = 1;
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
int root = find (fa[x] ); //将节点接到根上
fa[x] = root;
return root;
}
public int getSize(int x){ //查找大小
return size [x];
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
fa[ra] = rb; //A接入B树下
size [rb] += size [ra] ;
}
}
}
LeetCode-947. 移除最多的同行或同列石头 (有趣)(不会)
链接:https://leetcode-cn.com/problems/most-stones-removed-with-same-row-or-column
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。
示例 1:
输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
解释:一种移除 5 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,1] 同行。
2. 移除石头 [2,1] ,因为它和 [0,1] 同列。
3. 移除石头 [1,2] ,因为它和 [1,0] 同行。
4. 移除石头 [1,0] ,因为它和 [0,0] 同列。
5. 移除石头 [0,1] ,因为它和 [0,0] 同行。
石头 [0,0] 不能移除,因为它没有与另一块石头同行/列。
示例 2:
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
解释:一种移除 3 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,0] 同行。
2. 移除石头 [2,0] ,因为它和 [0,0] 同列。
3. 移除石头 [0,2] ,因为它和 [0,0] 同行。
石头 [0,0] 和 [1,1] 不能移除,因为它们没有与另一块石头同行/列。
解题思路
(不会是因为第一时间没想出来)
本题还是联通问题,联通规则为一对石头同行或者同列。
理解为联通问题后,本题首先应该做的就是根据石头排布的数组生成一组联通关系表,并且进行并查集获得若干个集合。
然后是关键的一个概念,一个联通的集合中,能拿走多少石头?
可以论证出一定能拿走总数减一个石头(size-1)
那么若干个集合能拿走多少个石头,则一定是总数减去集合数目的的石头(size-n)
(本题和前面一题计算机连线是相同的思维,代码略)
简述一下关键论证:一个集合一定能拿走总数减一个石头(size-1)
任何能加入集合的元素都是因为在同一横或者同一竖而进入集合的,因此可以反向的将其踢除,踢除的同时为了确保不再加入,从而取走任意一个位子的石子,因此能加入几个元素最终就能踢除几个元素,而总数则是1+a(a表示加入的次数)
LeetCode-1202. 交换字符串中的元素
链接:https://leetcode-cn.com/problems/smallest-string-with-swaps
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
示例 1:
输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]]
输出:"abcd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[0] 和 s[2], s = "acbd"
交换 s[1] 和 s[2], s = "abcd"
解题思路
本题依然是连通性问题,索引对就是联通条件,最终将一个集合内的元素进行排序,再将排序后的结果进行输出就可。
本题可以做一个进阶题,改一手,要求返回能生成字典序最小的字符串时的交换次数,
难度应该是不会有增长的。
但是也不利于更好的学习并查集,所以本题解题代码略写
(我认为重复的使用工具类,但需求上不需要变通,是没有进步的空间的)
LeetCode-721. 账户合并
链接:https://leetcode-cn.com/problems/accounts-merge
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是按字符 ASCII 顺序排列的邮箱地址。账户本身可以以任意顺序返回。
示例 1:
输入:
accounts = [["John", "[email protected]", "[email protected]"], ["John", "[email protected]"], ["John", "[email protected]", "[email protected]"], ["Mary", "[email protected]"]]
输出:
[["John", '[email protected]', '[email protected]', '[email protected]'], ["John", "[email protected]"], ["Mary", "[email protected]"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "[email protected]"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','[email protected]'],['John','[email protected]'],
['John','[email protected]','[email protected]','[email protected]']] 也是正确的。
解题思路
首先需要假定,相同账户的名字是相同的,这一点题干中没有讲,本题的并查集的概念依旧是同一套,需要进行合并的是数组的地址,也就是acoustic数组的下标,用于表示这组邮箱关系。然后再根据不同邮箱关系中是否持有相同的邮箱,来判断是否能合并集合。
合并之后,将相同集合内的所有邮箱按着名字输出即可。(此处就需要相同账户的名字是相同的定义,对此我题目中没看到就当是默认的)
(代码略,依旧是重复简单应用)
总结
这些解题过程中依然全部使用了并查集的功能,但是部分题目会微调这个工具类,这就是对工具的灵活使用。在实际使用中,会有很多的变化情况,需要灵活的使用这套方案。
在上方题目中应用最多的功能为:
- 合并成集合,最终判断各个集合的状态
- 判断两个元素是否能合并成集合,判断两个元素是否属于一个集合
另外课上,传授了编码能力。编码要有层次性,这部分只能跟着视频去看,语言描述就是层级的设计模块,并且进行编译,最好在任何一次开发中都保留阶段性调试的能力。
附加选做题
LeetCode-765. 情侣牵手 (有趣)
N 对情侣坐在连续排列的 2N 个座位上,想要牵到对方的手。 计算最少交换座位的次数,以便每对情侣可以并肩坐在一起。 一次交换可选择任意两人,让他们站起来交换座位。
人和座位用 0 到 2N-1 的整数表示,情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后一对是 (2N-2, 2N-1)。
这些情侣的初始座位 row[i] 是由最初始坐在第 i 个座位上的人决定的。
示例 1:
输入: row = [0, 2, 1, 3]
输出: 1
解释: 我们只需要交换row[1]和row[2]的位置即可。
示例 2:
输入: row = [3, 2, 0, 1]
输出: 0
解释: 无需交换座位,所有的情侣都已经可以手牵手了。
解题思路
本题就很有意思了,首先需要明确一个概念,一对情侣必然使用(2i-2, 2i-1)的位子作为牵手的位置,因此可以进行一轮遍历,先剔除已经牵手成功的情侣。
然后剩下的所有都没能配对,因此必须进行两两互换,此时会发生两种情况,一种是,交换后,双方都配配对成功,另一种则是只有一方配配对成功。
(此时猜想一个问题,有没有可能,我一次交换都不配对成功但是让下一次交换一下子成功2个的价值呢)
(显然是没有的,因为这样还是平均一次1个,所以只有这两种情况)
而配对成功则可以从需求池中踢除,因此竟可能的实现双配对就可以减少交换次数。
那么2对座位互换是有利的,是否会出现,只需要3对座位互换的情况呢,完全有可能例如a需求b,b需求c,c需求a,那么此外是否还会出现4只需要4对呢,也就是这一群组中找出这4个就能内部互换完毕呢,也完全可能。
由此我提出概念需求环,一个需求环的特征是,只需要环内进行座位调换就能完成配对需求,且调换的次数最小(如果不限制,那么两个需求环就可以套成一个大环,虽然实际上不会生成)
而双配对的关系则是一种最小环。(实际上最小的环是已经配对成功的,环大小为1,但为了简化判断,所以我定义最小环为2)
而一个环内的最调换次数为环元素-1
至此本题的解题思路就是求出有几个环,并且计算每个环的大小。而这种需求则应该使用并查集来解决。难点也只在于此处。
代码设计思路如下:
首先,遍历全部,遍历的同时座位的划分并且试图原地进行配对,如果不成功,则将对应关系存入map,此处准备2个map,分别表示左和右对应关系和右和左的对应关系,方便任何一个元素能找到当前所需元素的同组元素。
以排列0,2,1,3为例,0进行1的追寻,获得同组3,进行2的追寻获得同组0,成环环内元素为4,成2组最少调换为。此时剩下的元素(2,1,3)都不需要进行再搜寻了,因为在0的搜寻中这些已经成环。
因此本题的解题只需要判断一个元素是否进行过搜寻即可。
(至此我发现似乎不需要进行并查集,因为只需要统计追寻的路径和已经追寻过的元素即可)
(综上我认为和并查集无关)
解题代码
(这是我的解法,你有什么好办法吗?)
class Solution {
public int minSwapsCouples(int[] row) {
HashMap<Integer,Integer> LR = new HashMap<Integer,Integer> ();
HashMap<Integer,Integer> RL = new HashMap<Integer,Integer> ();
for(int i = 0;i<row.length;i+=2){ //第一轮关系存储
LR.put(row[i],row[i+1]);
RL.put(row[i+1],row[i]);
}
int res = 0;
boolean inLoop [] = new boolean [row.length];
for(int i = 0;i<row.length;i+=2){ //第二轮寻找成环
if(inLoop[row[i]] == false){
inLoop[row[i]] = true; //不重复
res += getLoopSize(LR,RL,row[i],row[i],inLoop); //从什么开始到什么结束,成环
}
}
return res;
}
public int getLoopSize (HashMap<Integer,Integer> LR,
HashMap<Integer,Integer> RL,int want,int end,
boolean inLoop []){
if(want %2==0) //期望寻找奇数
want = want +1;
else
want = want -1;
inLoop[want] = true;
Integer getR = LR.get(want);
Integer getL = RL.get(want);
//System.out.println(getR+""+getL+"end:"+end);
if(getR!=null){ //标识路劲
inLoop[getR] = true;
}else if(getL != null){
inLoop[getL] = true;
}
if((getR!=null&&end == getR)||
(getL != null&&end == getL)) //找到自己了停下,成环
return 0;
if(getR!=null){
return 1+getLoopSize(LR,RL,getR,end,inLoop);
}else if(getL != null){
return 1+getLoopSize(LR,RL,getL,end,inLoop);
}
return 0;
}
}
LeetCode-685. 冗余连接 II (有趣)(不会)
链接:https://leetcode-cn.com/problems/redundant-connection-ii
在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。
返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
示例 1:
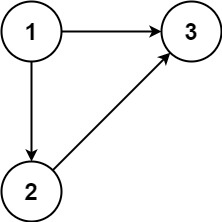
输入:edges = [[1,2],[1,3],[2,3]]
输出:[2,3]
示例 2:
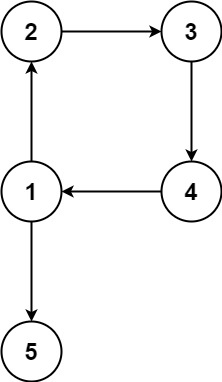
输入:edges = [[1,2],[2,3],[3,4],[4,1],[1,5]]
输出:[4,1]
解题思路
(不会是一眼看不会,这题用了我大概1H多时间,其他时间主要是码字)
本题和本题的变种题上方的冗余连接很像但是有一个关键节点,本题是有向图因此生成根节点会变得更为困难。
但是真的难吗?
首先修改工具类改为没有任何优化的算法,这样在进行合并时可以定义树结构的拼接关系,
如此我将获取一个同样能够判定是否相同集合集合的方案,而当我试图添加一个关系时,如果这个关系的两个节点已经存在于集合中,则不允许添加并且返回。
(但是题目描述有返回最后出现在给定二维数组的答案,因此需要遍历完毕,每一次有新的返回需求时,覆盖上一个准备返回的值,即可)
(至此我猜想本题没有任何难度,让我编程试试)
(失败了,关键在于本题对于树的定义是正常的树结构也就是根节点指向叶子节点的结构)
因此调转思维,由于题干描述为一个有若干子节点的树,因此制作度所在相同而方向相反的反树,由此来获取根节点。
首先在构成关系时,一个节点应该不能被多个节点节点指向,也就是先顺向构成并查集。判断二者不能再在同一集合中,如果出现了,就说明到目前的树结构有错误。但是这样的设计问题在于,如何知道一个叶子节点是否已经被指向了呢,对此可以对于每一个节点进行标记,当这个节点被指向时,那么这个节点的根节点一定不是自己。
因此需要构建一颗反树(定义指向关系符合数组对的树,为正树,否则为反树),这棵树由子节点指向根节点,当发现一个被指向的节点的根节点不是自身时,那么这个节点就必然经历了2个父节点的状态。因此此时的边就应该删除
但是怎么舍弃其中一个呢,对此一个方案是找到这对重指向的度(数组)然后假设执行其中一个观察状态是否可以正常运行,如果不行那就换一个。
(这个思路的漏洞在于,本题会出现多条重指向的不同边吗?如果会就不能用这个思路)
(我认为尝试时必须进行的因为冲突的边可能在前期才出现,而决定保留边的设定则是在后期才生成)
此时假设成功的树最终生成时,应该是反树中所有节点的根节点都最终指向一个目标节点。
由于题干描述:一条附加边,因此答案只在两种可能性中生成,因此只需要遇到冲突时,舍弃新的边然后试图进行构建即可,如果构建失败则应该舍弃另一条。
那么就相当于在判定时会有2个条件,不但要求不能成环,而且不能出现一个节点被多个节点指向的情况。
当出现一个节点被多个节点指向的情况时,答案在指向这个节点的2个边中寻找,当出现成环时,答案在环的构成中寻找。
因此首次故障时先区分出故障的来源,并且可以明确,其他跟故障无关的边都是正确的。
所以要利用这个规则,当是双指向错误时,跳过判定条件继续进行构建,如果构建成功就说明这个被跳过就是多余的,否则就是另一条,而面对成环错误时,应该跳过当前边先用后面的边进行构建如果还发生错误,就说明当前的边不应该跳过,需要被舍弃的是成环的其他因素,对此调整整体的结构改为将后面正确的部分优先执行的方式来重新判定,最终判定多余边就是期望的结果。
既然如此进一步讨论,假设第一个发生的故障是成环故障,那么第二个故障会是什么,第二个故障可能不发生或者为双指向,当不发生时,第一个故障的最后发起点就是可以舍弃的边。当发生时,为什么是双指向?
这是因为虽然有可能再发生成环,但是由于故障边只有一条,所以两次成环会需要有一条公共边,而双环有共边则一定会出现双指向。
至此可以发现问题,本题如果出现双故障就一定会出现双指向,而双指向可以将答案锁定在2个中。
- 当首次故障为双指向时,可以选择一条舍弃,继续构建来判断舍弃的是否正确
- 当首次故障为环时,环外必然没有错误的边,因此环内边和环外构成双指向时,舍弃环内边即可。
(到此我猜想完毕,但是还有一个漏洞,是否可能出现虽然继续构建是成功的,但是删除的边是错误的情况,我认为不会)
(成功了,舒服)
解题代码
class Solution {
public int[] findRedundantDirectedConnection(int[][] edges) {
int n = edges.length;
UnionSet US = new UnionSet (n);
return findRedundantDirectedConnection(edges,US);
}
public int[] findRedundantDirectedConnection(int[][] edges,UnionSet US) {
int n = edges.length;
int res [] = new int [2];
int anotherRes [] = new int [2];
boolean checkLine = false; //判定边是否需要被再允许添加
boolean loopFlag = false; //表示是否是成环故障
for(int i=0;i<n;i++){
int fa = US.find(edges[i][0]);
int fb = US.find(edges[i][1]);
if(fa!=fb&&fb == edges[i][1]){ //首先要求反树,被指向的目标只被指向一次
//并且还能符合联通集合的要求允许联通
US.merge(edges[i][1],edges[i][0]); //那么加入反树的枝干中,指向根节点
}else{
if(checkLine){ //再次失败
if(!loopFlag)
return anotherRes;
else{
//成环时二次错误,则舍弃环内的双指向
//意味着有一组已经进行了指向,两者必须舍弃一个
res [1] = edges[i][1];
System.out.println(res [0]+"+"+res [1]);
//找到前一个矛盾点
for(int j = 0;j<i;j++){
if(edges[i][1] == edges[j][1]){
anotherRes [0] = edges[j][0];
anotherRes [1] = edges[j][1];
return anotherRes;
}
}
}
}
if(fb != edges[i][1]){ //优先考虑双指向的情况
if(!checkLine){
checkLine = true;
//意味着有一组已经进行了指向,两者必须舍弃一个
res [0] = edges[i][0];
res [1] = edges[i][1];
System.out.println("line1:"+res [0]+"+"+res [1]);
//找到前一个矛盾点
for(int j = 0;j<i;j++){
if(edges[i][1] == edges[j][1]){
anotherRes [0] = edges[j][0];
anotherRes [1] = edges[j][1];
break;
}
}
}
}else{ //成环导致故障因此需要舍弃元素必然环的构成
if(!checkLine){
//成环故障的方案是
//优先执行执行其他正确的节点
res [0] = edges[i][0];
res [1] = edges[i][1];
loopFlag = true;
checkLine = true;
System.out.println("line1:"+res [0]+".."+res [1]);
}
}
}
}
return res;
}
class UnionSet{
private int [] fa;
private int n;
public UnionSet(int n){
this.n = n;
fa = new int [n+1];
//n+1的意义是n指代0~n个,如果n的意义是n个,可以不加1
for(int i = 0;i<= n;i++){
fa [i] = i; //对各自根(父节点)进行初始化
}
}
public int find(int x){ //查找根
if(fa[x] == x ) return x;
return find(fa[x]);
}
public void merge (int a,int b){
int ra = find(a);
int rb = find(b);
if(ra == rb ) return; //相同根不需要合并
fa[ra] = rb; //改为A的根接B树的根
}
}
}
彩蛋题目//oj.kaikeba.com,214 朋友圈题目
结语
概念部分40分钟左右学完
习题部分3H学完
笔记写完7H发布
总用时1课约11H,半天,完全掌握。
相比起之前的时间损耗应该是进步了,如果最后一题我没有僵住,应该可以做到近似2倍课时完成学习。
在本课中我充分的练习了并查集的功能,对此你有什么未能掌握的,亦或者是对我的解题有疑惑的,可以评论区留言,谢谢。
(1000篇博文计划,进度加1,(。_ 。) ✎_学习计划走起)