一、安装docker并生成相关的镜像
(1)安装docker
安装docker教程
https://www.runoob.com/docker/centos-docker-install.html
只要在终端输入:
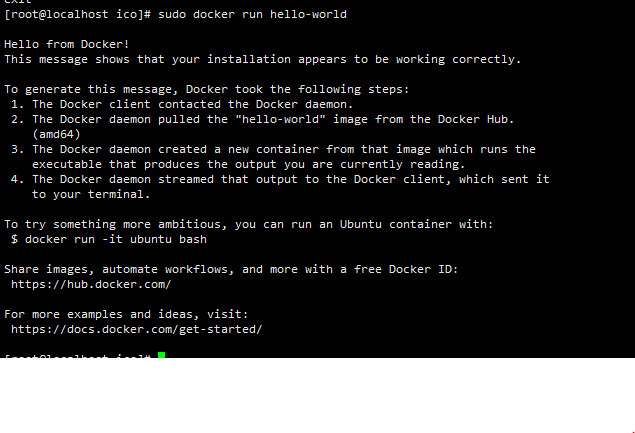
sudo docker run hello-world后出现如下图的内容就证明安装docker成功了
(2)拉取CentOS镜像(Ubuntu镜像也行)
在终端输入:
sudo docker pull centos在终端输入:sudo docker images,可以看到刚刚拉取的两个镜像

每次执行docker语句都要在前面加sudo,比较麻烦,直接将hadoop用户加入docker用户组,就不用再输入sudo了。
sudo gpasswd -a $USER docker #将当前用户加入到docker用户组中
newgrp docker #重新加载docker用户组一般安装时会自动创建docker用户组,如果docker用户组不存在的话,在终端输入:
sudo groupadd docker #创建docker用户组注意,此时只有执行上述两条命令行的终端可以不用输入sudo,其他终端仍要输入,得重启虚拟机后所有终端才不用输入sudo。
(3)通过build Dockfile生成带ssh功能的centos镜像
先创建Dockfile文件,在终端输入:
vi Dockerfile在Dockfile文件中添加以下内容:
FROM centos
MAINTAINER hadoop
RUN cd /etc/yum.repos.d/
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
RUN yum makecache
RUN yum update -y
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
RUN echo "root:a123456" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]Dockfile文件的内容解释:基于centos镜像,生成带有spenssh-server、openssh-clients的镜像,用户为root,密码为a123456,镜像维护者(作者)为hadoop。为了防止出现Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
错误,我更改了yum下载依赖的镜像baseurl。注意:如果拉取的镜像是Ubuntu的话,得修改下载spenssh-server、openssh-clients的命令行。
你可能需要修改的地方:
1、MAINTAINER hadoop
MAINTAINER+空格+作者的信息,用于指定镜像作者的信息,我的用户名是hadoop,改成你自己的
2、root:a123456
设置镜像的密码,改成你自己的
建好Dockerfile文件后,生成镜像,在终端输入:
docker build -t="centos7-ssh" .查看生成的centos7-ssh镜像,在终端输入:
docker images
(4)将下载的文件上传虚拟机
没有Xftp和Xshell的同学可以用VMwareTools替代,只要把压缩包添加到虚拟机主机上即可。安装VMwareTools后,复制本地主机的文件粘贴到虚拟机主机指定目录下。
1、用Xshell和Xftp连接虚拟机主机
Xshell(测试是否能正常连接,其实只需要用Xftp传输文件):
用户名填hadoop(换成你自己的),root可能会登不上,如果ssh运行状态没问题,还连接不上的话,可能是防火墙没关。
Xftp:
将压缩包上传到/home/hadoop(有Dockerfile的目录),如果上传失败,可能是目录没有传输文件的权限,在终端输入:
chmod 777 /home/hadoop/2、解压文件(把目录和文件名改成你自己的)
在终端输入:
tar -zxvf /home/hadoop/hadoop-3.1.3.tar.gz -C /home/hadoop/ico
tar -zxvf /home/hadoop/jdk-8u212-linux-x64.tar.gz -C /home/hadoop/ico(5)生成带有ssh、hadoop和jdk环境的CentOS镜像
移除原有的Dockerfile文件,在终端输入:
mv Dockerfile Dockerfile.bak再重新创建一个Dockerfile文件,在终端输入:
vi Dockerfile或者直接在Xftp上用记事本编辑原来的Dockerfile文件,更加方便(推荐)
将下面内容填入Dockerfile文件(记得保存)
FROM centos7-ssh
COPY jdk1.8.0_212 /usr/local/jdk
ENV JAVA_HOME /usr/local/jdk
ENV PATH $JAVA_HOME/bin:$PATH
COPY hadoop-3.1.3 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH构建Dockerfile,在终端输入:
docker build -t="hadoop" .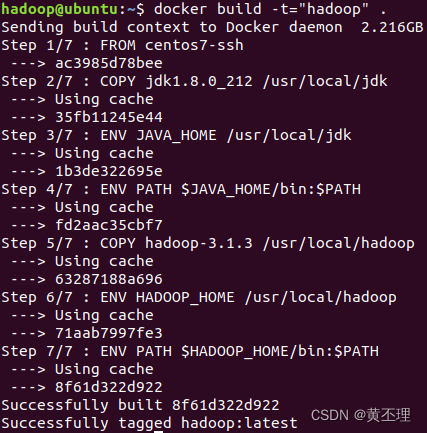
成功生成名字为hadoop的镜像。
三、创建网桥,并启动docker容器
因为集群的服务器之间需要通信,而且每次虚拟机给集群分配的ip地址都不一样,所以需要创建网桥,给每台服务器分配固定的ip映射,这样就可以通过使用服务器名进行通信了,而且ip地址也不会变动。
(1)创建网桥
在终端输入:
docker network create hadoop(2)查看网桥
在终端输入:
docker network ls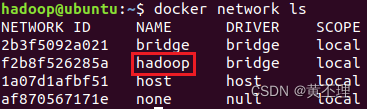
其他三个网桥是安装docker时自带的,hadoop是刚刚创建的。
(3)启动三个容器并指定网桥
依次在终端执行下面三条命令行:
docker run -itd --network hadoop --name hadoop1 -p 50070:50070 -p 8088:8088 hadoop
docker run -itd --network hadoop --name hadoop2 hadoop
docker run -itd --network hadoop --name hadoop3 hadoop参数解释:
-itd:在后台运行交互式容器
--network:指定网桥
--name:指定生成的容器名
-p:指定端口映射,主机端口号:容器端口号,第一个是hdfs服务,第二个是yarn 服务
末尾的hadoop是运行的镜像名
查看生成的容器,在终端输入:
docker ps -a
查看网桥使用情况,在终端输入:
docker network inspect hadoop
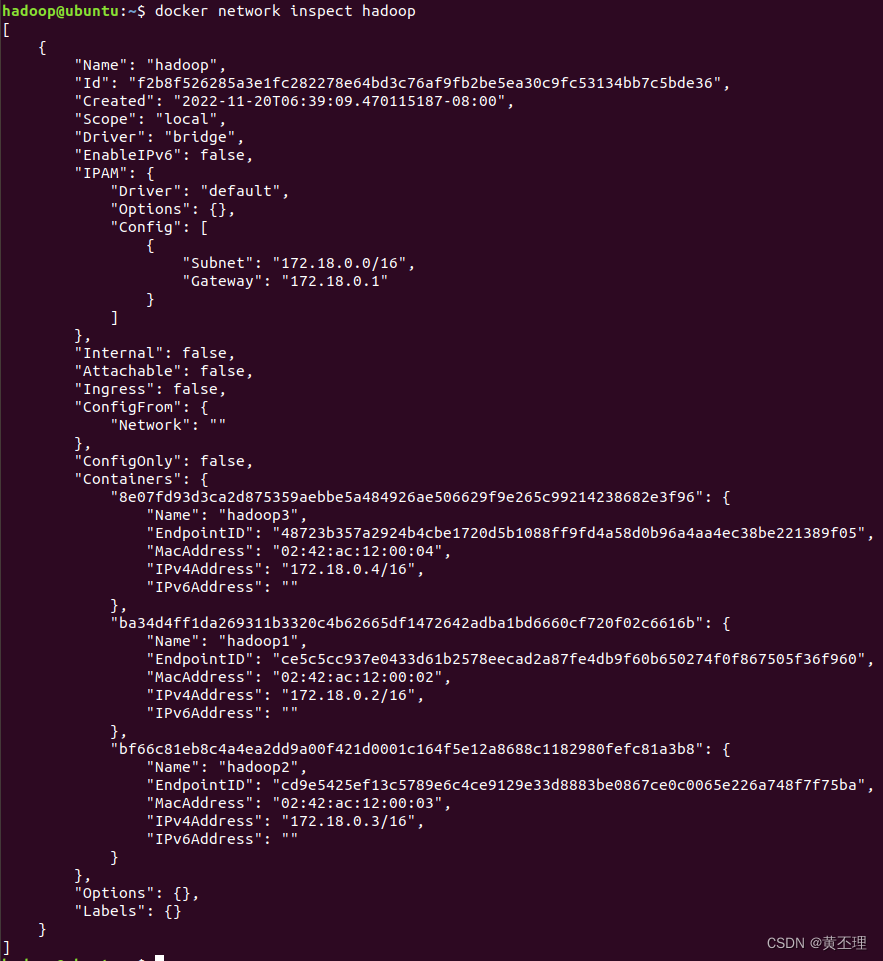
记录每台服务器的ip地址,后面要用,每个人的可能不一样,换成你自己的
172.18.0.2 hadoop1
172.18.0.3 hadoop2
172.18.0.4 hadoop3四、登录容器,配置ip地址映射和ssh免密登录
(1)登录容器(Hadoop服务器)
开启三个终端,在每个终端分别输入:
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash(2)在每个hadoop服务器中配置ip地址映射
在每台hadoop服务器的终端输入:
vi /etc/hosts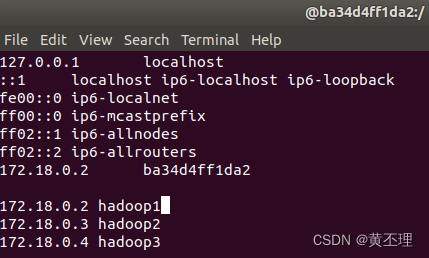
然后填入刚刚记录的ip地址
每台Hadoop服务器都配置好后,可以互相ping一下(ctrl + c停止ping),看看是否配置成功。hadoop1 ping hadoop2 如下图所示:
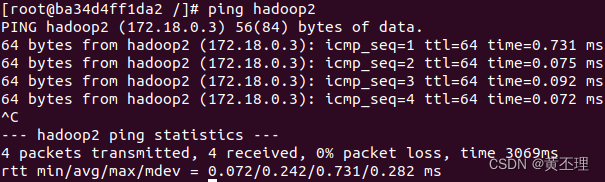
(3)在每台hadoop服务器中配置ssh免密登录
在每台hadoop服务器终端输入:
ssh-keygen然后一直回车即可,再在每台hadoop服务器终端中输入:
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2填yes后,输入第二(3)步时设置的密码,123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop3填yes后,输入第二(3)步时设置的密码,123456
(4)测试是否成功配置ssh免密登录
ssh + hadoop服务器名:
ssh hadoop1
ssh hadoop2
ssh hadoop3五、修改Hadoop配置文件
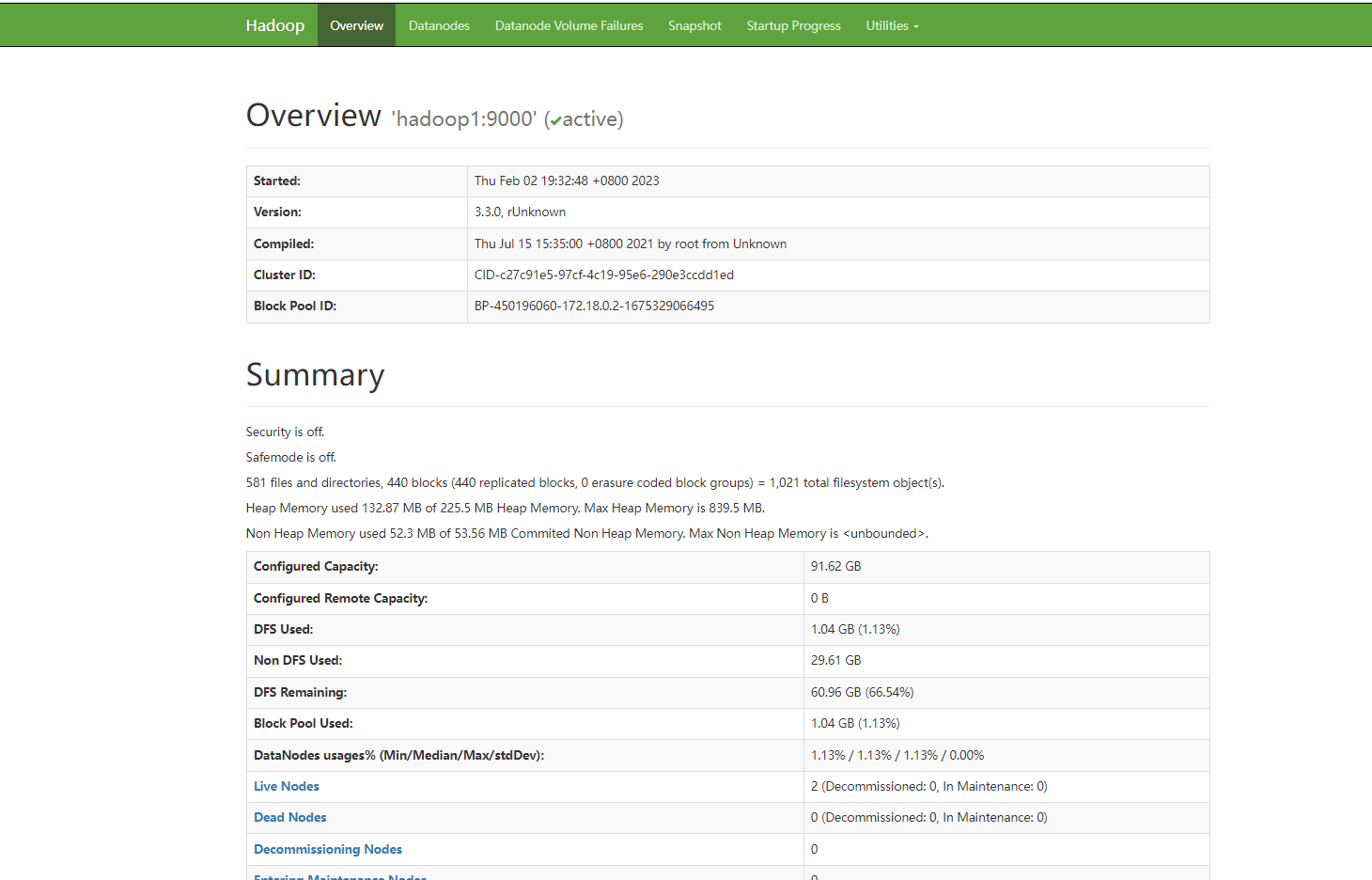
在hadoop1中,进入Hadoop配置目录,我的是:/usr/local/hadoop/etc/hadoop,查看目录下的文件,不同版本的Hadoop可能文件数量和名字会不同,在终端输入:
ls
(1)创建文件夹,配置时要用
mkdir /home/hadoop
mkdir /home/hadoop/tmp /home/hadoop/hdfs_name /home/hadoop/hdfs_data(2)编辑hadoop_env.sh
修改下面三个参数,按照你自己的改
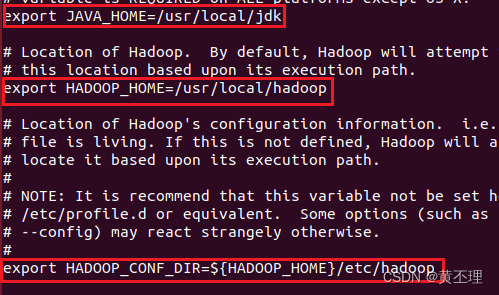
(3)编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>(4)编辑mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>(5)编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs_name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs_data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9002</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>Hadoop的Web UI界面访问地址:1、namenode:hadoop1:9001(会自动跳转到9000端口,如果直接访问9000端口号可能会访问异常)2、secondarynamenode:hadoop2:9002
(6)编辑yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>(7)编辑workers
把原先的默认值localhost删除
hadoop2
hadoop3(8)配置环境变量
在终端输入:
vi /etc/profile在文件尾部添加配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root保存退出后,再输入下面的命令行使配置生效:
source /etc/profile(9)把文件拷贝到hadoop2和hadoop3上
依次执行以下命令:
scp -r $HADOOP_HOME/ hadoop2:/usr/local/
scp -r $HADOOP_HOME/ hadoop3:/usr/local/
scp -r /home/hadoop hadoop2:/
scp -r /home/hadoop hadoop3:/
scp -r /etc/profile hadoop2:/
scp -r /etc/profile hadoop3:/(10)给文件赋权
在每台hadoop服务器的终端执行下面两条命令行:
chmod -R 777 /usr/local/hadoop
chmod -R 777 /usr/local/jdk六、启动Hadoop集
(1)在hadoop1上执行以下命令:
1、格式化hdfs
hdfs namenode -format2、一键启动Hadoop集群
start-all.sh(2)测试Hadoop集群
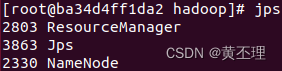
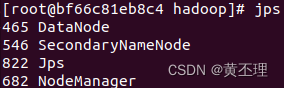
每台服务器都输入:
jpshadoop1:
hadoop2:
hadoop3:
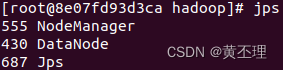
hadoop1是名称结点,hadoop2是第二名称节点和数据节点,hadoop3是数据节点。网上很多人把名称节点和第二名称节点配置在同一台服务器上,我觉得这样配置是错的,这样配置根本发挥不了第二名称节点的作用:作为名称节点的检查点,定期合并日志和镜像。
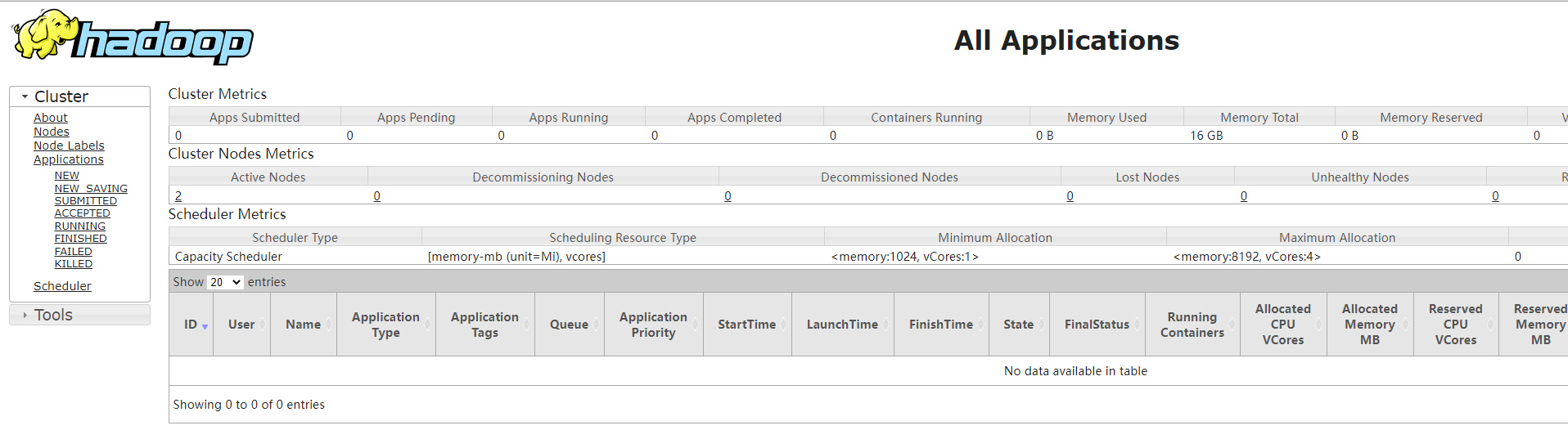
(3)访问hadoop集群
http://192.168.175.131:8088/cluster
七、安装Hive
拷贝下载的Hive到docker容器中:
# 拷贝Hive安装包进 h01容器
docker cp /Users/luochao7/Downloads/apache-hive-3.1.2-bin.tar.gz 5fa8d538d8ae:/usr/local
# 进入容器
docker exec -it 5fa8d538d8ae bash
cd /usr/local/
# 解压安装包
tar xvf apache-hive-3.1.2-bin.tar.gz
#文件夹更名
root@h01:/usr/local# mv apache-hive-3.1.2-bin hive
#拷贝Mysql jdbc驱动到hive安装包 lib目录下(我的Mysql是8.0.26的)
docker cp /Users/luochao7/.m2/repository/mysql/mysql-connector-java/8.0.26/mysql-connector-java-8.0.26.jar 5fa8d538d8ae:/usr/local/hive/lib八、配置Hive
1.修改Hadoop中的 core-site.xml,并且 Hadoop集群同步配置文件,重启生效
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>因为Hive需要把数据存储在 HDFS上,并且通过 MapReduce作为执行引擎处理数据
2.修改配置文件
#slf4j这个包hadoop及hive两边只能有一个,这里删掉hive这边
root@Master:/usr/local/hive/lib# rm log4j-slf4j-impl-2.10.0.jar
#guava这个包hadoop及hive两边只删掉版本低的那个,把版本高的复制过去,这里删掉hive,复制hadoop的过去(注意看路径)
root@h01:/usr/local/hadoop/share/hadoop/common/lib# cp guava-27.0-jre.jar /usr/local/hive/lib/
root@h01:/usr/local/hive/lib# rm -rf guava-19.0.jar
#修改hive环境变量文件 添加Hadoop_HOME
root@h01:/usr/local/hive/conf# mv hive-env.sh.template hive-env.sh
root@h01:/usr/local/hive/conf# vim hive-env.sh
#在最后一行添加
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
#新增hive-site.xml 配置mysql等相关信息
root@h01:/usr/local/hive/conf# vim hive-site.xml
#粘贴配置
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://172.17.0.2:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--mysql用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--mysql密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop1</value>
</property>
<!-- 远程模式部署metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>3. 初始化元数据(先启动 mysql)
root@h01:/usr/local/hive# bin/schematool -initSchema -dbType mysql -verbos
九、启动Hive
(1)第一代客户端(deprecated 不推荐使用)
前台启动Metastore服务(不推荐):
root@h01:/usr/local/hive# bin/hive --service metastore启动后,窗口一直处于等待的状态:

这个时候,这个窗口就不能干别的,使用 control + c 结束,所以,不推荐这种方式。
2.后台启动Metastore服务(推荐):
#输入命令回车执行 再次回车 进程将挂起后台
root@h01:/usr/local/hive# nohup bin/hive --service metastore &注意末尾有一个 &符号,启动后,这个进程在后台运行:

使用 jps 查看进程:
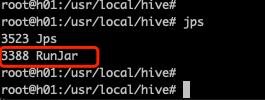
可见,有一个 RunJar 在后台运行。
3.启动 hive(先启动Hadoop集群)
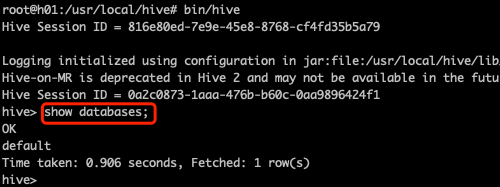
root@h01:/usr/local/hive# bin/hive启动成功后,如下图所示,输入 show databases 可以查看hive的数据库:
(2)第二代客户端(推荐使用)
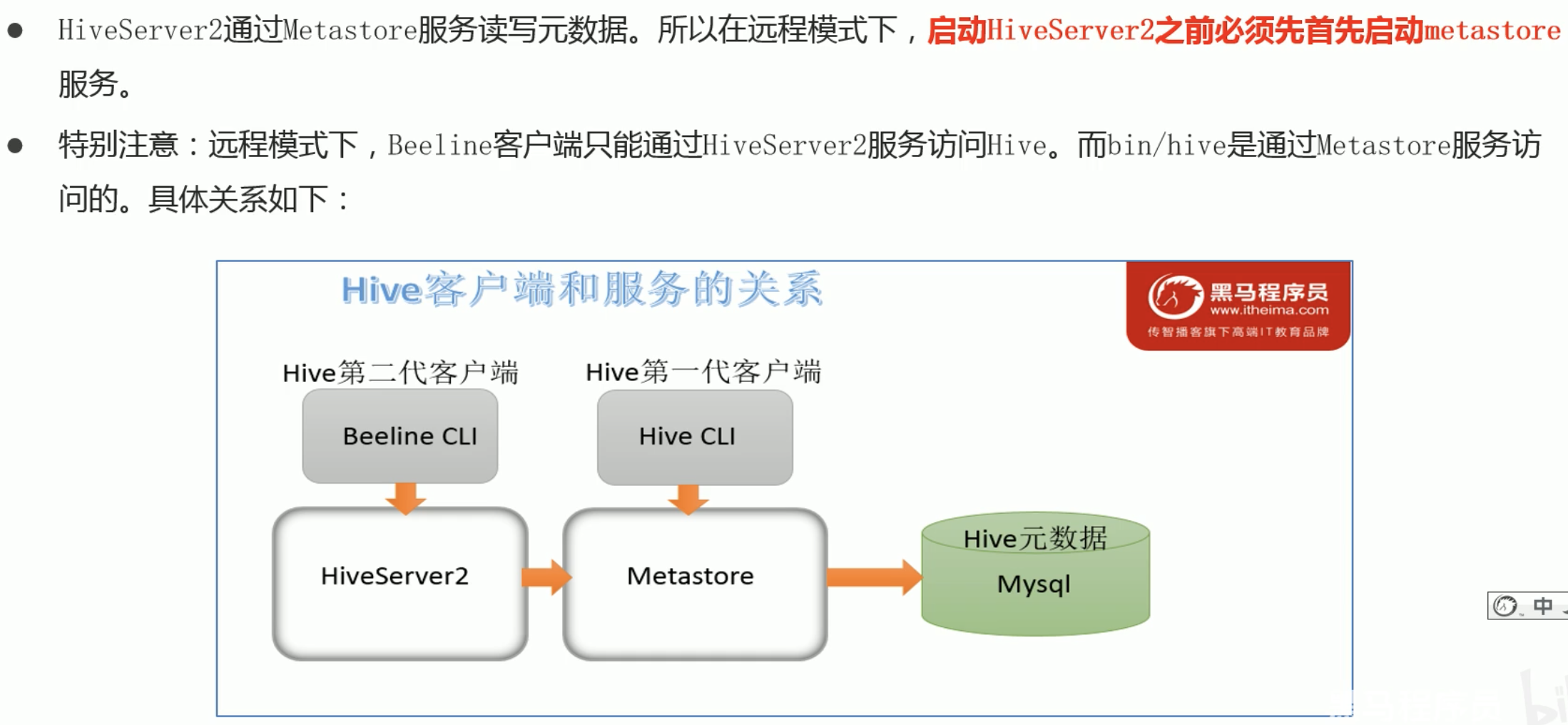
Hive经过发展,推出了第二代客户端 beeline,但是 beeline客户端不是直接访问 metastore服务的,而是需要单独启动 hiveserver2服务。在Hive安装的服务器上,首先启动metastore服务,然后启动 hiveserver2服务.
如下图所示:
1. 后台启动Metastore服务(先启动Hadoop ,如果电脑资源比较小,可以只启动Master):
#输入命令回车执行 再次回车 进程将挂起后台
root@h01:/usr/local/hive# nohup bin/hive --service metastore &2. 后台启动 hiverserver2 服务:
root@h01:/usr/local/hive# nohup bin/hive --service hiveserver2 &注意:启动 hiverserver2 服务之后,要等一会儿(等半分钟吧)再往下启动 beeline客户端,不然会报错:Could not open connection to the HS2 server
3. 启动 beeline客户端:
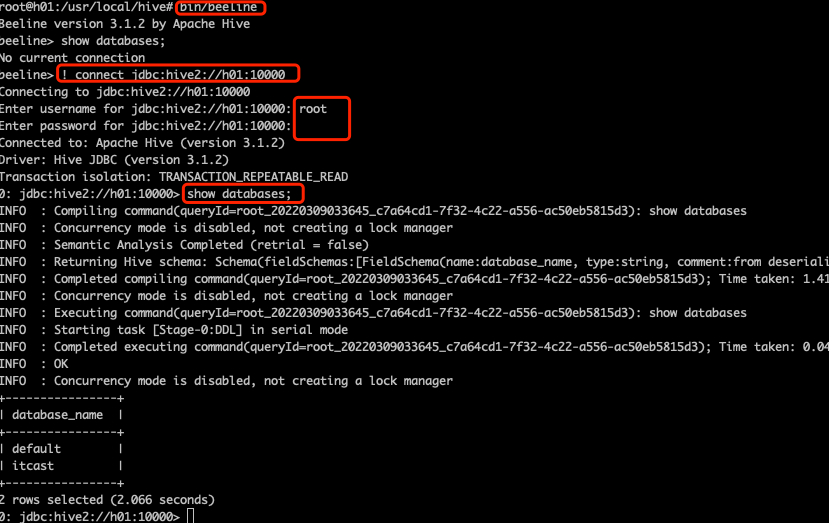
root@h01:/usr/local/hive# bin/beeline4. 连接 hiverserver2 服务
beeline> ! connect jdbc:hive2://hadoop1:10000#输入密码,一般都是root访问,直接输入 root,密码不用输,直接回车
Enter username for jdbc:hive2://hadoop1:10000: root
Enter password for jdbc:hive2://hadoop1:10000:
Connected to: Apache Hive (version 3.1.2)截图如下:
否则,不连接 hiveserver2 的话,直接 show databases 会显示:No current connection.
5.测试是否能和Hadoop相连:(如果之前没有创建 itcast 数据库)
INFO : Compiling command(queryId=root_20220324095900_739f115e-5f84-43f8-9eed-e07e95a84db4): createdatabase itcast
INFO : Compiling command(queryId=root_20220324095924_3e08b7ab-605f-4951-9c90-f002288f0b63): use itcast
INFO : Compiling command(queryId=root_20220324095930_85fb6058-0d15-4d99-8cc3-8d6ae761f0b0): show tables
0: jdbc:hive2://h01:10000>createtable t_user(id int, name varchar(255), age int);
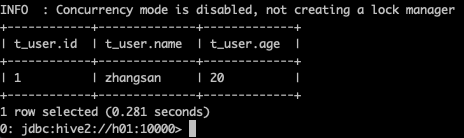
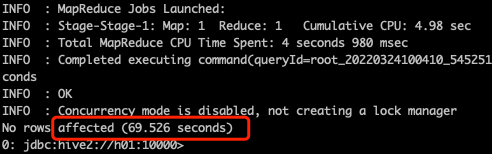
0: jdbc:hive2://h01:10000>insert into table t_user values(1,"zhangsan",20);如果能插入成功,就表示能正常连接到Hadoop,因为Hive的数据都是存在 HDFS上的,只是这个过程很慢,如下图:
执行这一条 insert 语句,竟然花了 69秒,插入成功的话,使用:select * from t_user,显示如下: