CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion

标题:DreamPose:通过稳定扩散实现时尚图像到视频合成
作者:Johanna Karras, Aleksander Holynski, Ting-Chun Wang, Ira Kemelmacher-Shlizerman
文章链接:https://arxiv.org/abs/2304.06025
项目代码:https://grail.cs.washington.edu/projects/dreampose/
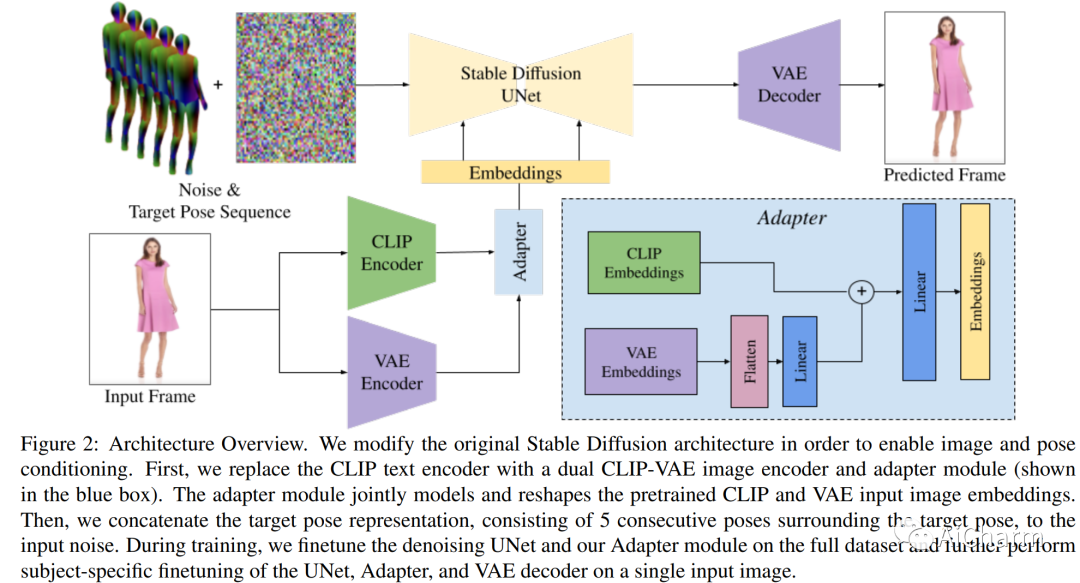
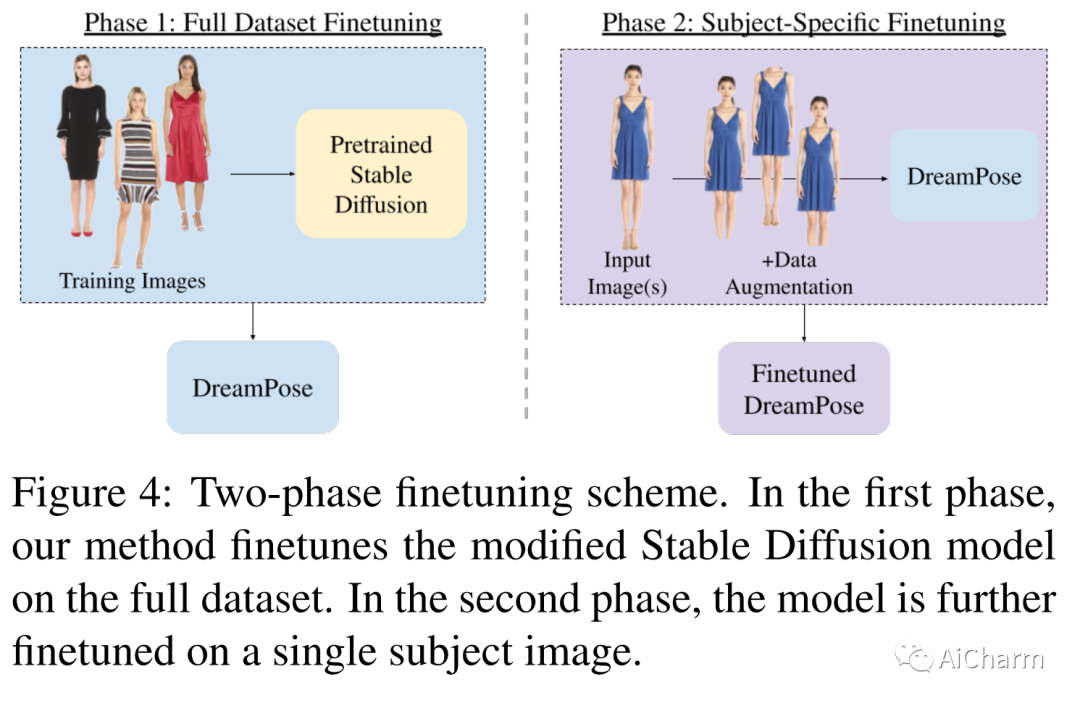


摘要:
我们介绍了 DreamPose,这是一种基于扩散的方法,用于从静止图像生成动画时尚视频。给定一张图像和一系列人体姿势,我们的方法合成了一个包含人体和织物运动的视频。为实现这一目标,我们将预训练的文本到图像模型(稳定扩散)转换为姿势和图像引导的视频合成模型,使用新颖的微调策略、一组架构更改以支持添加的调节信号和技术鼓励时间一致性。我们对来自 UBC 时尚数据集的时尚视频集进行了微调。我们在各种服装风格和姿势上评估了我们的方法,并证明我们的方法在时尚视频动画上产生了最先进的结果。我们的项目页面上提供了视频结果。
2.Diagnostic Benchmark and Iterative Inpainting for Layout-Guided Image Generation
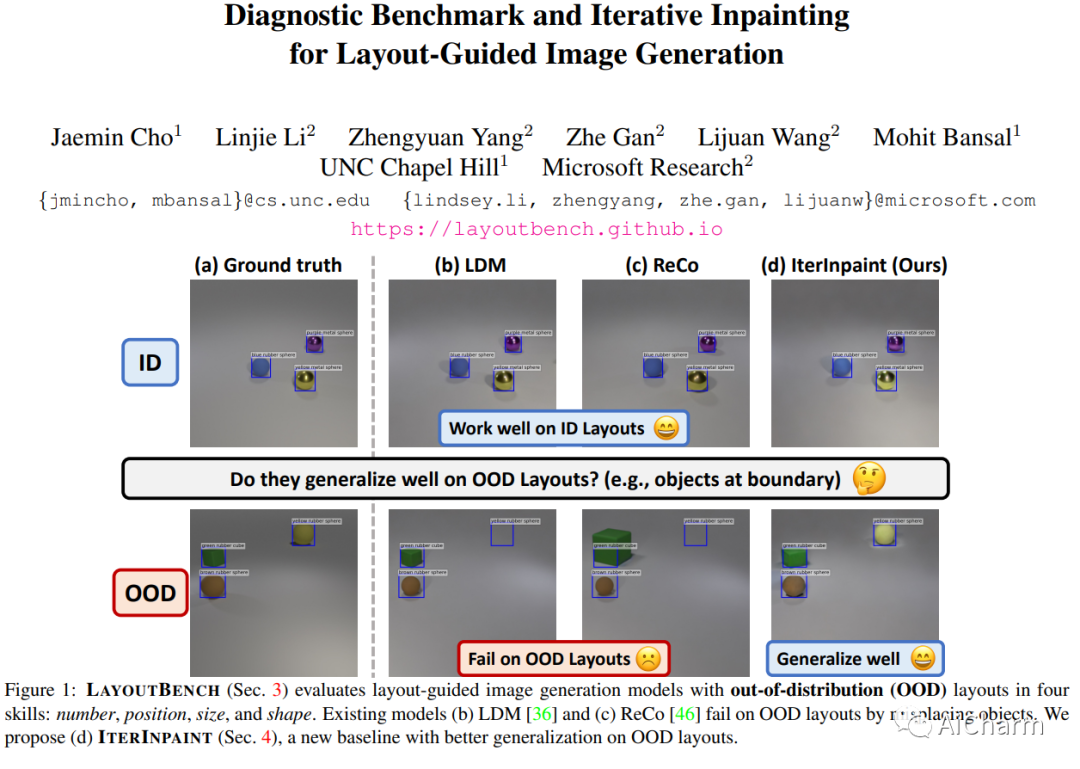
标题:用于布局引导图像生成的诊断基准和迭代修复
作者:Jaemin Cho, Linjie Li, Zhengyuan Yang, Zhe Gan, Lijuan Wang, Mohit Bansal
文章链接:https://arxiv.org/abs/2304.06671
项目代码:https://layoutbench.github.io/
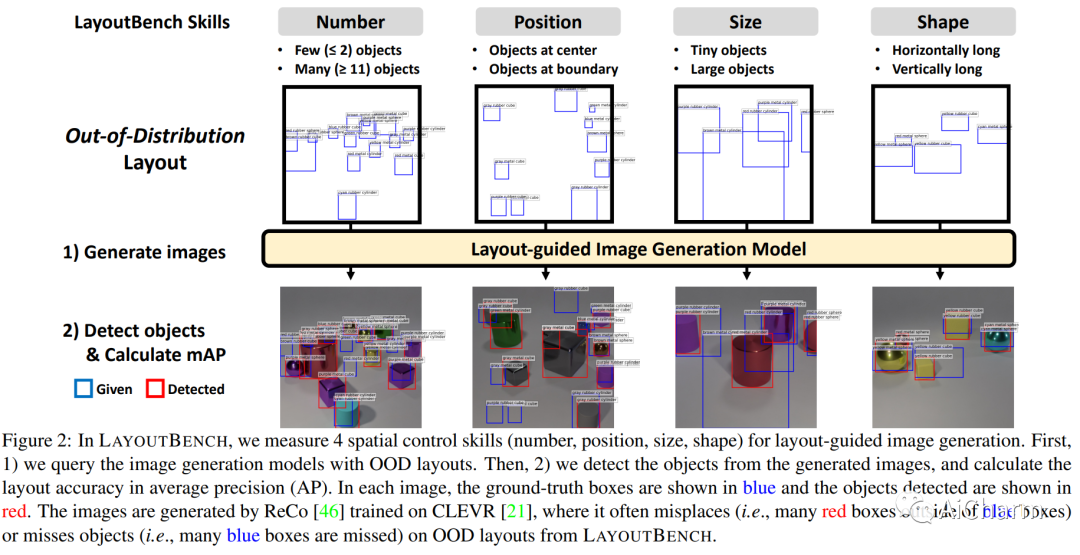

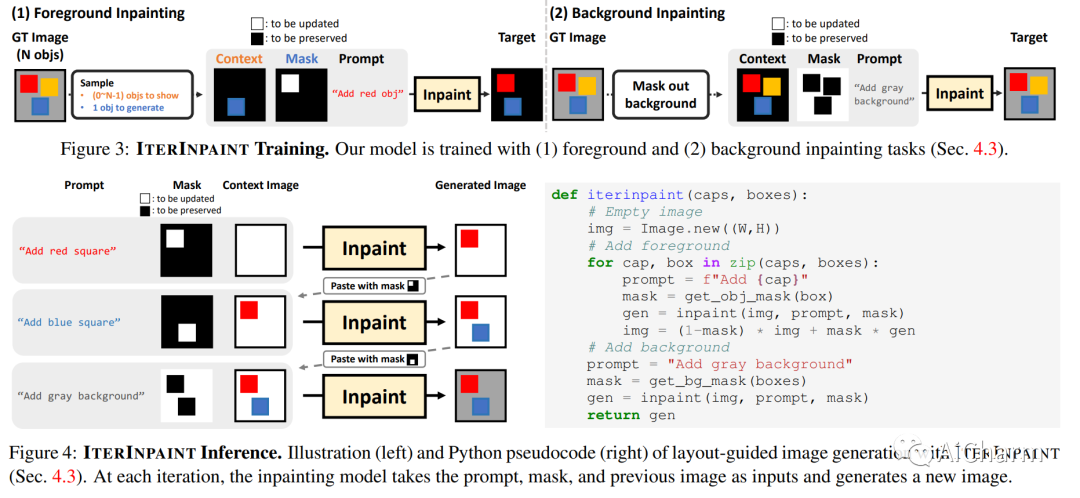
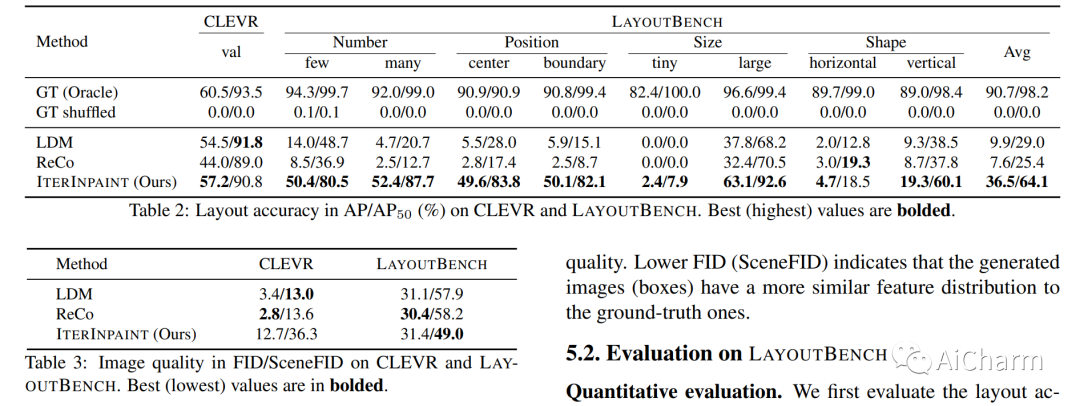
摘要:
空间控制是可控图像生成的核心能力。布局引导图像生成方面的进步已在具有相似空间配置的分布内 (ID) 数据集上显示出可喜的结果。然而,目前尚不清楚这些模型在面对具有任意、看不见的布局的分布外 (OOD) 样本时的表现。在本文中,我们提出了 LayoutBench,这是一种用于布局引导图像生成的诊断基准,它检查四类空间控制技能:数量、位置、大小和形状。我们对最近两种具有代表性的布局引导图像生成方法进行了基准测试,并观察到良好的 ID 布局控制可能无法很好地泛化到野外的任意布局(例如,边界处的对象)。接下来,我们提出了 IterInpaint,这是一种新的基线,它通过修复以逐步的方式生成前景和背景区域,在 LayoutBench 的 OOD 布局上展示了比现有模型更强的通用性。我们对 LayoutBench 的四种技能进行定量和定性评估以及细粒度分析,以找出现有模型的弱点。最后,我们展示了对 IterInpaint 的综合消融研究,包括训练任务比率、裁剪和粘贴与重绘以及生成顺序。项目网站:这个https URL
3.DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning

标题:DiffFit:通过简单的参数高效微调解锁大型扩散模型的可转移性
作者:Enze Xie, Lewei Yao, Han Shi, Zhili Liu, Daquan Zhou, Zhaoqiang Liu, Jiawei Li, Zhenguo Li
文章链接:https://arxiv.org/abs/2304.06648
项目代码:https://github.com/mkshing/DiffFit-pytorch


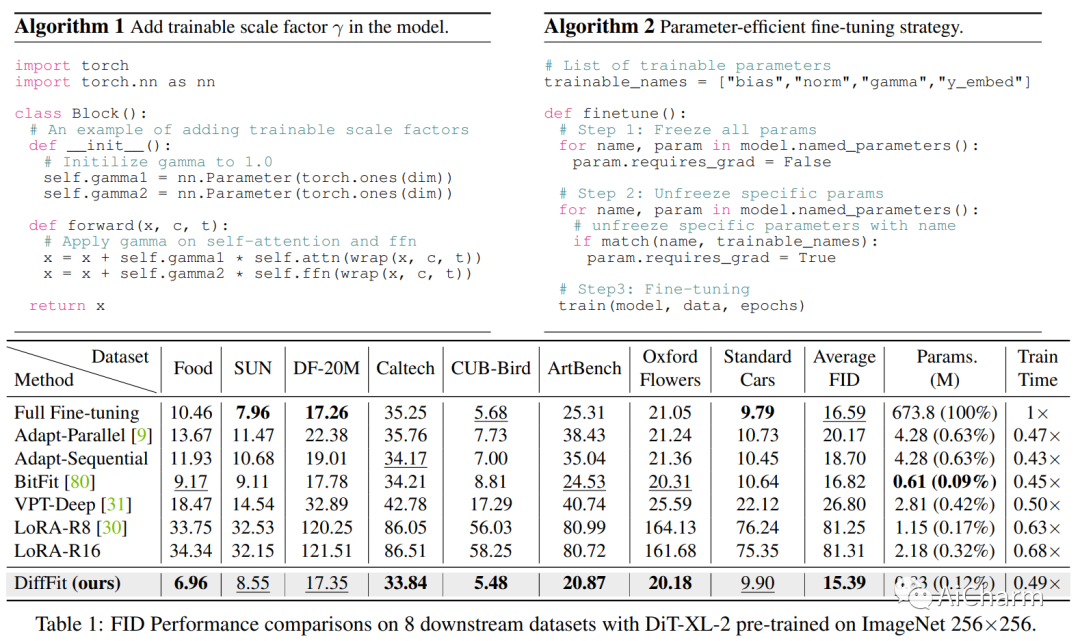
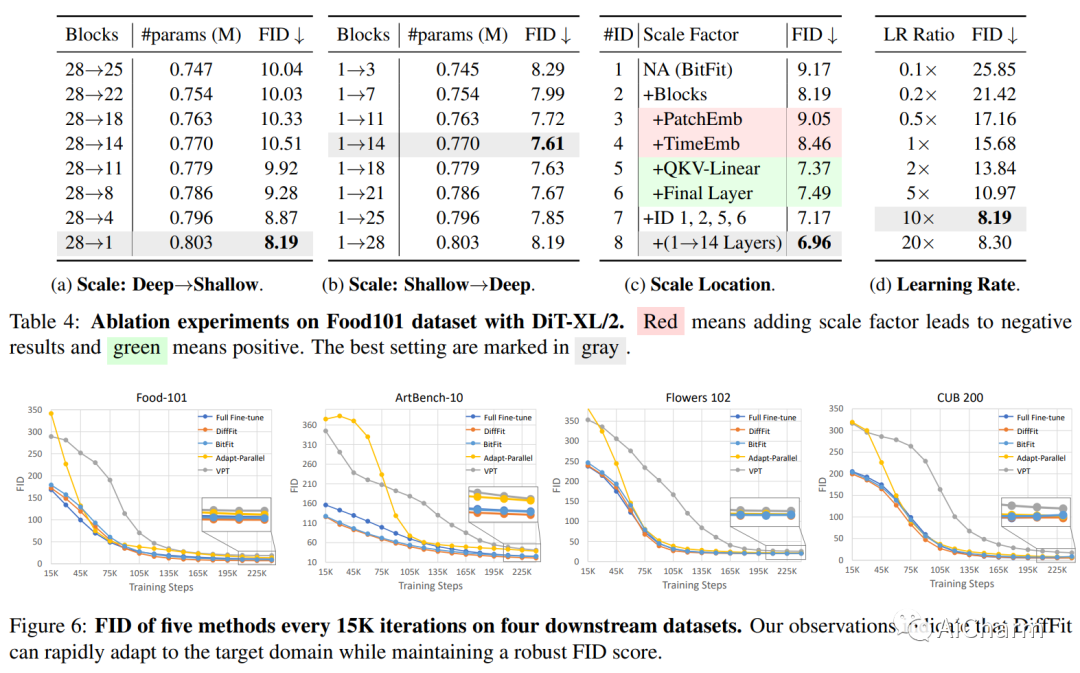
摘要:
扩散模型已被证明在生成高质量图像方面非常有效。然而,使大型预训练扩散模型适应新领域仍然是一个开放的挑战,这对于实际应用至关重要。本文提出了 DiffFit,这是一种参数高效策略,用于微调大型预训练扩散模型,从而能够快速适应新领域。DiffFit 非常简单,仅微调特定层中的偏差项和新添加的缩放因子,但会显着提高训练速度并降低模型存储成本。与完全微调相比,DiffFit 实现了 2 × 的训练速度提升,并且只需要存储大约 0.12\% 的模型总参数。已经提供了直观的理论分析来证明缩放因子对快速适应的有效性。在 8 个下游数据集上,与完全微调相比,DiffFit 取得了优越或有竞争力的性能,同时效率更高。值得注意的是,我们表明 DiffFit 可以通过增加最小成本将预训练的低分辨率生成模型调整为高分辨率生成模型。在基于扩散的方法中,DiffFit 在 ImageNet 512 × 512 基准上设置了一个新的最先进的 FID 3.02,方法是从公共预训练的 ImageNet 256 @ 中仅微调 25 个时期。5# 256 checkpoint while being 30 × 训练效率比最接近的竞争对手高。
更多Ai资讯:公主号AiCharm