CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.SpectFormer: Frequency and Attention is what you need in a Vision Transformer

标题:SpectFormer:频率和注意力是您在 Vision Transformer 中所需要的
作者:Badri N. Patro, Vinay P. Namboodiri, Vijay Srinivas Agneeswaran
文章链接:https://arxiv.org/abs/2304.06446
项目代码:https://badripatro.github.io/SpectFormers/





摘要:
视觉Transformer已成功应用于图像识别任务。已经有基于多头自注意力ViT、DeIT、类似于文本模型中的原始工作,或者最近基于光谱层Fnet, GFNet,AFNO。我们假设光谱注意力和多头注意力都起着重要作用。我们通过这项工作研究了这个假设,并观察到确实结合了光谱和多头注意层提供了更好的转换器架构。因此,我们为变压器提出了新颖的 Spectformer 架构,它结合了光谱和多头注意层。我们相信,由此产生的表示允许变换器适当地捕获特征表示,并且它比其他变换器表示产生更高的性能。例如,与 GFNet-H 和 LiT 相比,它在 ImageNet 上的 top-1 精度提高了 2%。SpectFormer-S 在 ImageNet-1K(小型版本的最新技术)上达到 84.25% top-1 准确率。此外,Spectformer-L 达到了 85.7%,这是同类变压器基础版本的最新技术水平。我们进一步确保我们在其他场景中获得合理的结果,例如在 CIFAR-10、CIFAR-100、Oxford-IIIT-flower 和 Standford Car 数据集等标准数据集上进行迁移学习。然后,我们研究了它在 MS-COCO 数据集上的目标检测和实例分割等下游任务中的用途,并观察到 Spectformer 表现出与最佳主干相媲美的一致性能,并且可以进一步优化和改进。因此,我们相信组合的光谱层和注意力层是视觉转换器所需要的。
2.Verbs in Action: Improving verb understanding in video-language models
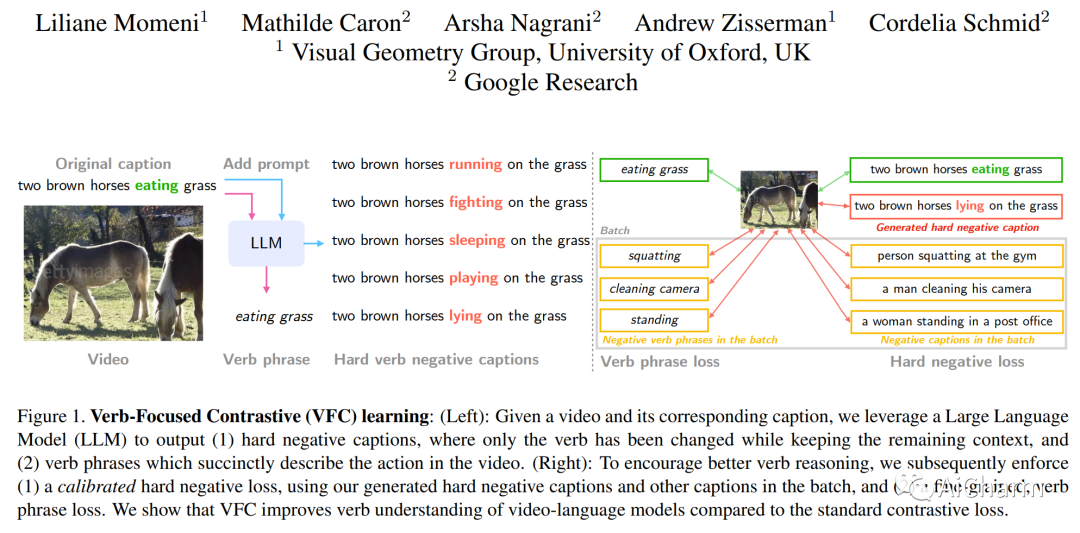
标题:行动中的动词:提高视频语言模型中的动词理解
作者:Liliane Momeni, Mathilde Caron, Arsha Nagrani, Andrew Zisserman, Cordelia Schmid
文章链接:https://arxiv.org/abs/2304.06708


摘要:
理解动词对于模拟人和物体如何通过空间和时间相互作用以及环境至关重要。最近,基于 CLIP 的最先进的视频语言模型已被证明对动词的理解有限,并且广泛依赖名词,这限制了它们在需要动作和时间理解的真实视频应用程序中的性能。在这项工作中,我们通过提出一个新的以动词为中心的对比 (VFC) 框架来提高对基于 CLIP 的视频语言模型的动词理解。这包括两个主要部分:(1)利用预训练的大型语言模型(LLM)为跨模态对比学习创建硬底片,以及平衡正面和负面对中概念出现的校准策略;(2) 执行细粒度的动词短语对齐损失。我们的方法在三个专注于动词理解的下游任务上实现了零样本性能的最先进结果:视频文本匹配、视频问答和视频分类。据我们所知,这是第一个提出减轻动词理解问题的方法的工作,并没有简单地强调它。
3.RECLIP: Resource-efficient CLIP by Training with Small Images

标题:RECLIP:通过小图像训练实现资源高效的 CLIP
作者:Runze Li, Dahun Kim, Bir Bhanu, Weicheng Kuo
文章链接:https://arxiv.org/abs/2304.06028



摘要:
我们提出了 RECLIP(资源高效 CLIP),这是一种最小化 CLIP(对比语言图像预训练)计算资源占用的简单方法。受计算机视觉中从粗到精概念的启发,我们利用小图像有效地从大规模语言监督中学习,并最终使用高分辨率数据微调模型。由于视觉转换器的复杂性在很大程度上取决于输入图像的大小,我们的方法在理论上和实践中都显着减少了训练资源需求。使用相同的批量大小和训练时期,RECLIP 实现了极具竞争力的零样本分类和图像文本检索精度,计算资源比基线少 6 到 8 × ,FLOPs 少 7 到 9 × .与最先进的对比学习方法相比,RECLIP 展示了 5 到 59 × 训练资源节省,同时保持了极具竞争力的零样本分类和检索性能。我们希望这项工作能为更广泛的研究社区铺平道路,在资源更友好的环境中探索语言监督预训练。
更多Ai资讯:公主号AiCharm