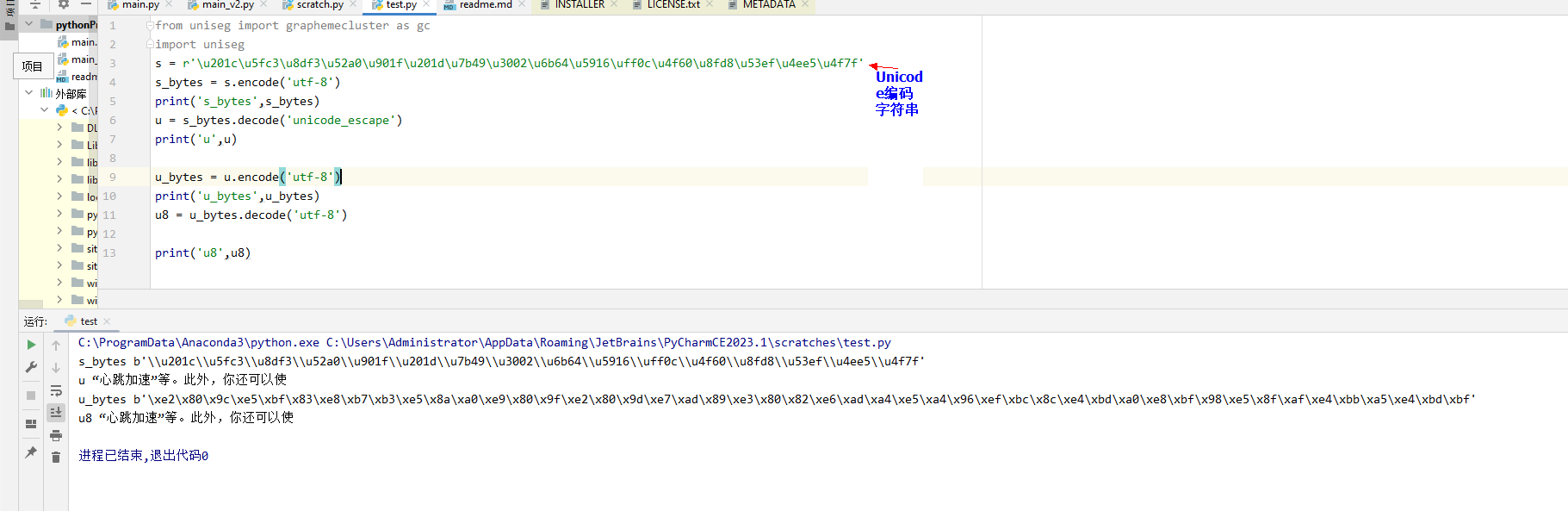
#content 是 Unicode编码字符串
content = r'\u201c\u5fc3\u8df3\u52a0\u901f\u201d\u7b49\u3002\u6b64\u5916\uff0c\u4f60\u8fd8\u53ef\u4ee5\u4f7f'
z1= content.encode('utf-8',errors='ignore').decode('unicode_escape',errors='ignore')
z2=content.encode('utf-8',errors='ignore').decode('unicode_escape',errors='ignore').encode('utf-8',errors='ignore').decode('utf-8',errors='ignore')
#z1 和z2 区别
z1 可能包含非utf-8字符,显示保存到文件时就需要用z2
print(z1,'\n',z2)