目录
(1)从像素GAN到块级GAN到图像级GAN(From PixelGANs to PatchGANs to ImageGANs)
1.pix2pix研究背景
提示:pix2pix主页

- 数字图像任务
- 计算机视觉( Computer Vision)
- 模仿人眼和大脑对视觉信息的处理和理解
- 图像分类,目标检测,人脸识别
- 计算机图形学( Computer Graphics)
- 在数字空间中模拟物理世界的视觉感知
- 动画制作,3D建模,虚拟现实
- 数字图像处理( Digital Image Processing)
- 依据先验知识,对图像的展现形式进行转换
- 图像增强,图像修复,相机ISP
- 图像翻译(Image Translation)图像与图像之间以不同形式的转换。根据sorce domain 的图像生成target domain中对应图像,约束生成的图像和source 图像的分布在某个维度上尽量一致
- 图像修复
- 视频插帧
- 图像编辑
- 风格迁移
- 超分辨率
-
图像质量评价(Image Quality Assessment,IQA)
-
像素损失(MSE)
-
结构性损失(SSIM)
-
色彩损失
-
锐度损失(GMSD)
-
感知损失(用ImagNet预训练模型提取图像的feature,再比较feature之间的损失)
-
2.Pix2Pix基本原理
(1)原理图

提示:这是将图像边缘转手机拍照图的过程。
- 生成器模型
- 首先是生成模型对于输入的边缘图(区别于GAN输入的噪声)经过转换之后得到一张假的手机拍照图。
- 生成模型的目的就是使得生成的拍照图骗过判别器。
- 判别器模型
- 第一部分
- 将生成模型生成的拍照图和对应的真实边缘图一起输入到判别器进行判别。
- 输出判别器结果尽量判别为假。
- 第二部分
- 将真实的边缘图和对应的真实的拍照图输入到判别器进行判别。
- 输出判别结果尽量判别为真。
- 第一部分
(2)条件GAN(cGAN)
- 原始GAN
- 原始的GAN是在模型训练过程让生成模型(Generator Model)和判别模型(Discriminator Model)不断的进行对抗,互相的优化,最终让生成模型去逼近真实数据的概率分布,最后只要将噪声输入到生成模型当中,即可生成服从真实图片概率分布以假乱真的图像。
- 条件GAN(cGAN)
- 条件GAN(cGANs)限制在离散标签、文本以及图像上。图像条件模型已经处理了来自正常映射的图像预测、未来帧预测、照片生成来自稀疏注释的图像生成。
- y可以是任何形式的辅助信息,比如说类别标签或者其他模式的数据。可以通过增加额外的输入层来将y同时输入生成器和判别器,来实施条件模型。
- 在生成器模型中,将真实数据x作为输入,输出对应的数据y';
- 在判别器模型中,x和y被作为输入送入判别模型判别真假,同时将x和y'也作为输入,输入到判别模型当中,判别生成模型生成的数据真假。
- 总结
- 总的来说,条件GAN中生成模型的目的还是让生成的图像尽量骗过判别器;判别模型的目的还是尽量将生成模型生成的图像判别为假,真实的输入图像尽量判别为真。
(3)公式原理

提示:之所以会加上L1损失,也是从实验中发现加了L1损失之后效果是最好的,如下图:
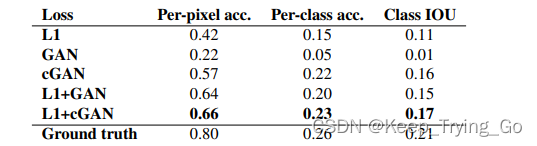
提示:通过学习相关的GAN知识点,可以发现GAN领域是将数学公式和代码之间结合最好的。
3.Pix2Pix网络模型
(1)从像素GAN到块级GAN到图像级GAN(From PixelGANs to PatchGANs to ImageGANs)


提示:论文中给出从像素级GAN到块级GAN,最后到图像级GAN。Patch大小为70 x 70的时候效果和大小为完整图像的Patch效果差不错,但是质量稍微较低。
从如下图可以看到,在街景图的标签(labels->photos)上,对于输入大小为256 x 256分辨率的图像(更大的图像使用0填充),通过FCN-scores评估对于不同判别器(Discriminator)感受野大小的结果,感受野为70 x 70的判别器效果最好。
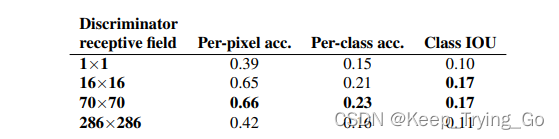
注:FCN是图像分割领域的开山之作,模型采用全卷积网络,对图像中的不同目标进行分割 。FCN——深度学习领域图像分割(Fully Convolutional Networks for Semantic Segmentation)
(2)判别模型
提示:原输入图像的大小为286 x 286,所以判别器最终输出的大小为[1,1,30,30];但是在本文中使用的输入图像大小为256 x 256,所以判别器输出的大小为[1,1,26,26].
四种不同感受野的判别器,并且所有的判别器都是使用的相同的基础结构,也就是下面的四种不同大小的感受野判别器前面所使用的结构都相同,随着深度的增加,感受野不断改变。
- 感受野大小为:70 x 70
- C64-C128-C256-C512
- 最后一层卷积的输出通道数为1,紧接着激活函数采用Sigmoid,表示输出最后的判别概率(real / fake)
- 如果在这里没有使用Sigmoid激活函数的话,那么在计算损失值的时候就要使用
BCEWithLogitsLoss(),因为BCEWithLogitsLoss()带了Sigmoid激活函数。- 第一参卷积没有使用Batch Normalization
- 整个过程所使用的激活函数均为LeakReLU
- 感受野大小为:1 x 1
- C64-C128
- 整个过程都使用1 x 1的卷积核,因为本身所进行的就是1 x 1大小的感受野。
- 感受野大小为:16 x 16
- C64-C128
- 感受野大小为:286 x 286(整幅图)
- C64-C128-C256-C512-C512-C512
(3)生成模型
提示:生成模型是通过FCN-scores在数据集街景图上选择出来的,对比得到以U-Net网络作为生成模型是效果最好的。
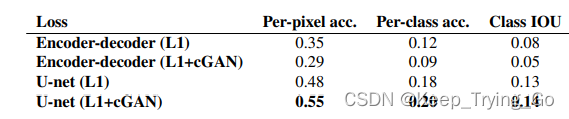
原文给出原始的解码器和编码器结构如下:
补充:
- 对于解码器
- 最后一层卷积之后,输出的通道数为3(RGB),当然colorization的输出通道数为2除外,最后使用的激活函数为Tanh()
- 卷积过程中使用的激活函数为ReLU
- 对于编码器
- 第一层卷积没有使用Batch Normalization
- 卷积过程中使用的激活函数为LeakReLU,并且其控制负激活值(negative_slope=0.2)的斜率为0.2
- 对于编码器和解码器
- 在整个过程中采用了跳跃连接(skip connections),并且编码器和解码器的拼接是对应的。比如整个过程有n个卷积层,编码器的第i层和解码器的第n - i层进行拼接。

U-Net网络的解码器如下:https://mydreamambitious.blog.csdn.net/article/details/126092060

4.数据集下载
5.pix2pix代码实现
提示:代码放在了Github上,本文的代码是参考下面这位博主写的,但是自己其中只是做了一下修改,并且其中加了一个mainWindows界面代码,方便后面训练的模型进行图像风格的转换。
参考博主的代码:https://b23.tv/QUc0CNb
本文的代码下载:GitHub - KeepTryingTo/Pytorch-GAN: 使用Pytorch实现GAN 的过程
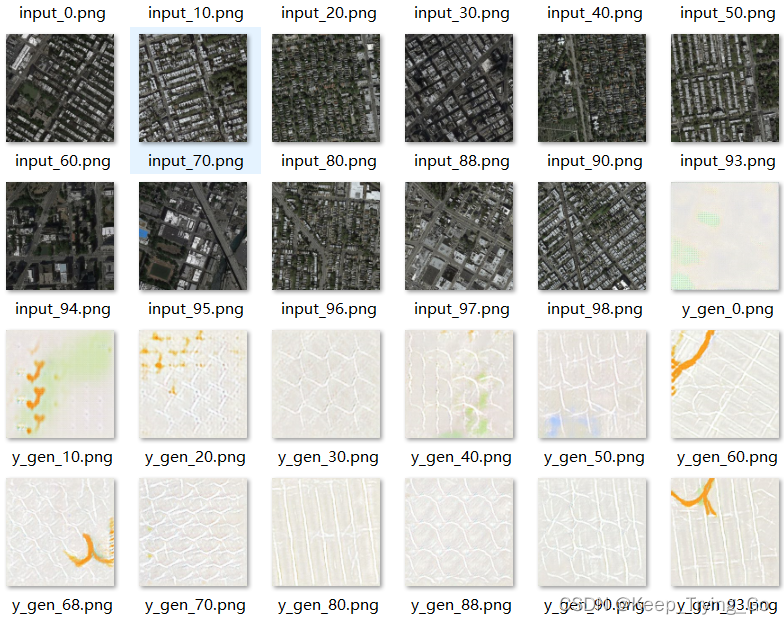
6.mainWindow窗口显示生成器生成的图片
提示:这里编写了一个显示生成器显示图片的程序(mainWindow.py),加载之前训练之后保存的生成器模型,之后可使用该模型进行随机生成图片,如下:
(1)运行mainWindow.py 初始界面如下

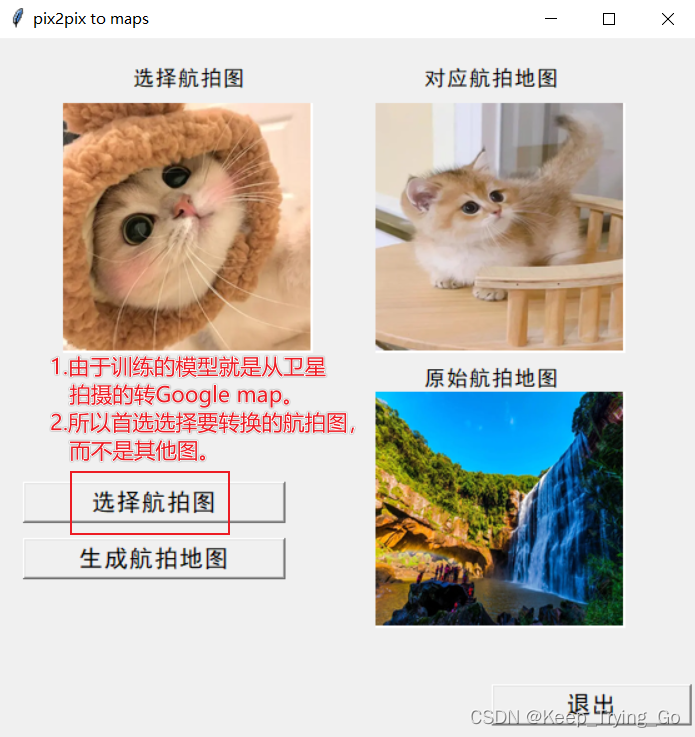
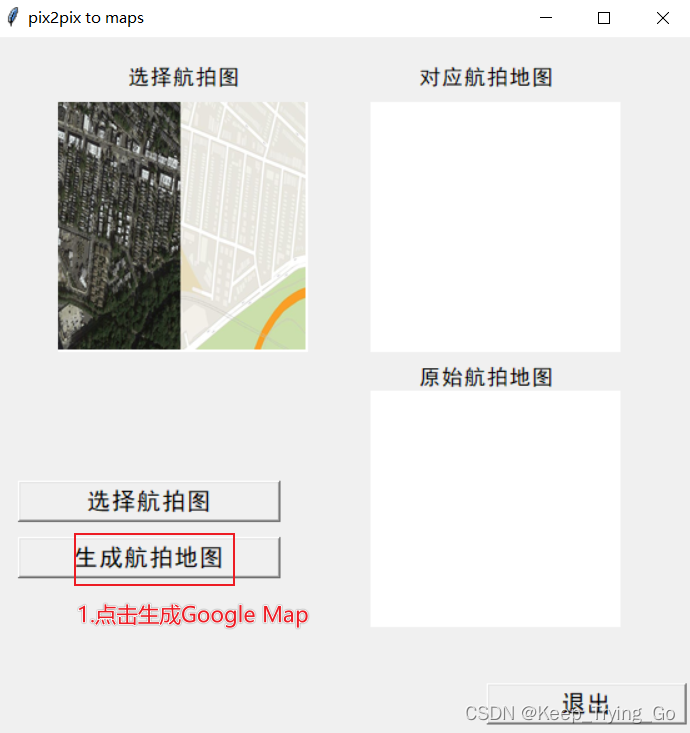
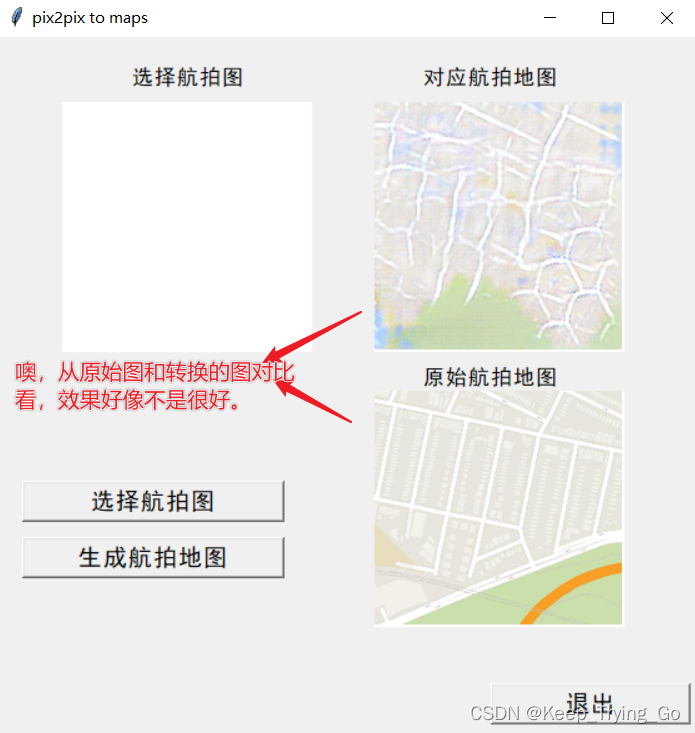
7.模型下载
链接:https://pan.baidu.com/s/1J2fT-jNpmDLcqwbAN6ip6w
提取码:tsx9
参考链接