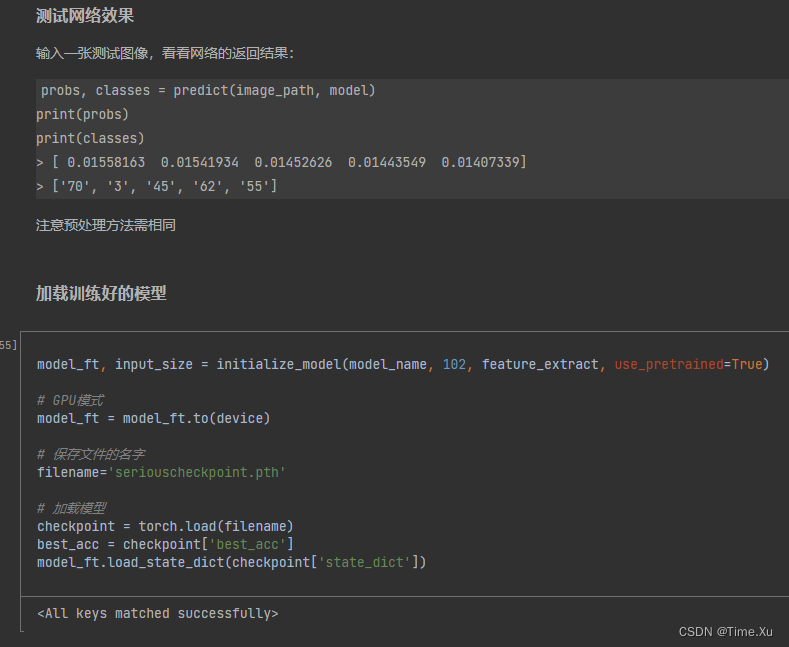
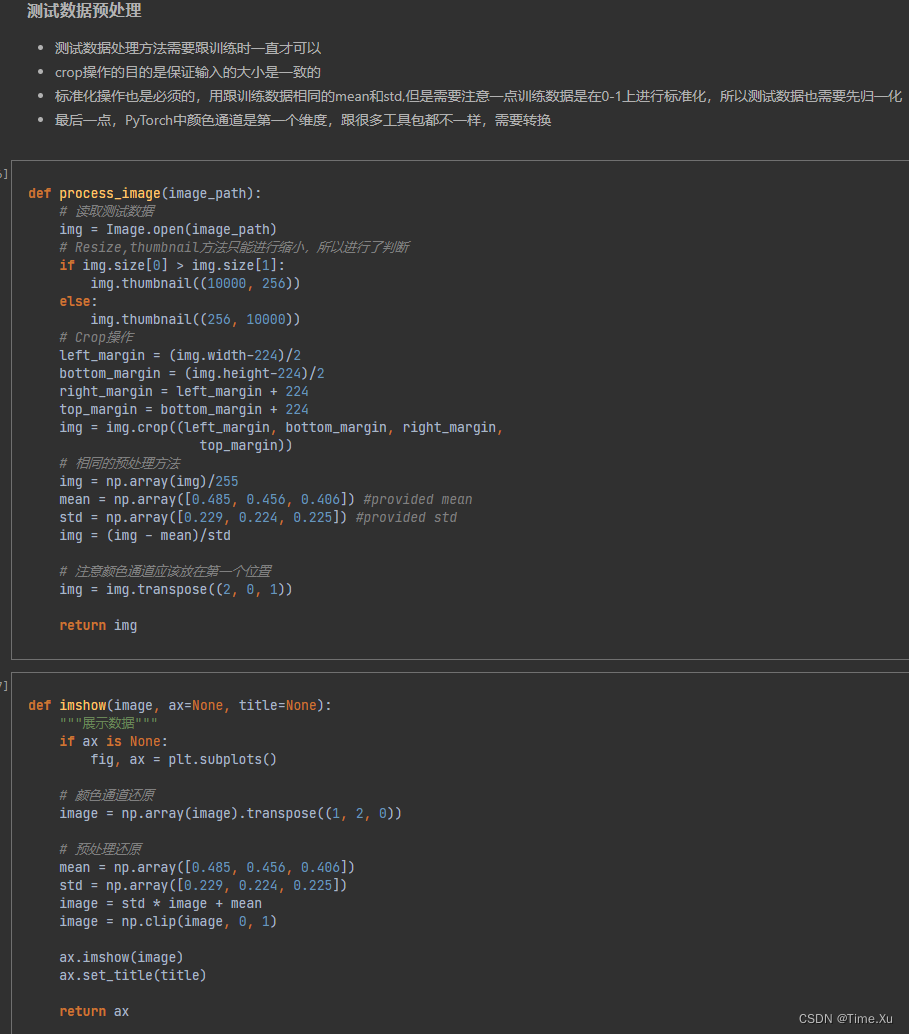
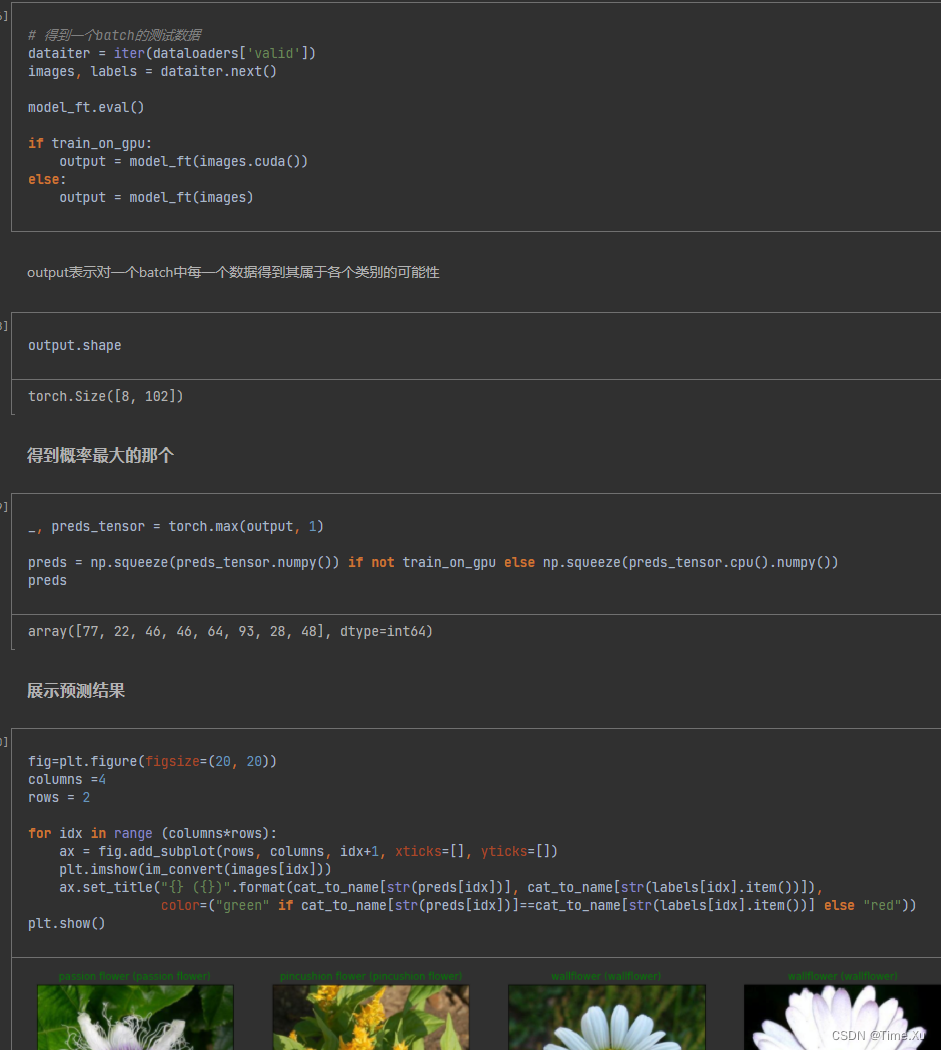
上一篇文章我们讲解了
1、数据的增强方法 和 导入方法(ToTensor、归一化)
2、使用torchvision模块中定义好的数据集格式来规范加载数据的方式
3、展示我们导入的数据
4、使用已有的模型以及权重 等等
这一节我们继续把整个网络训练做完
优化器设置

训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename):
since = time.time()
best_acc = 0
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet执行的是这里
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
# 计算损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 得到最好那次的模型
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
#开始训练!、
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))
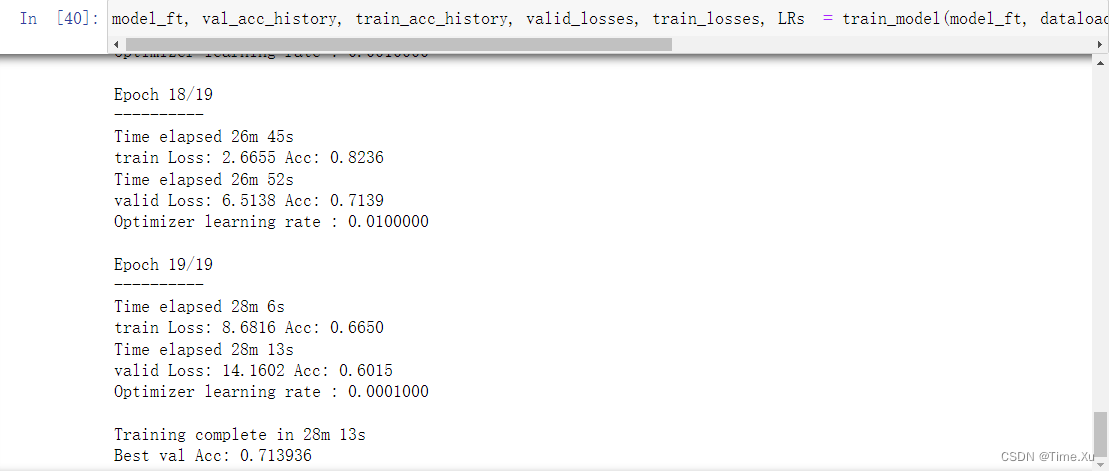
训练之后就可以测试查看了: