前言
之前学了Scrapy框架,费了好大的劲安装完毕之后,又看了
https://blog.csdn.net/c406495762/article/details/72858983这位大佬用Scrapy爬取火影忍者,然而我并没有完全弄懂其中的逻辑。为了更好地熟悉这个框架,我自己使用其进行了爬虫。
其中,自己在开始前,看了
https://blog.csdn.net/zjiang1994/article/details/52779537
并且成功爬取慕课网的栏目信息
现在我要自己熟悉Scrapy,我的目的:
爬取在http://ss.zhizhen.com中搜索名为李的作者所发表的文献的各种信息。
开始
首先
1.
scrapy startproject bishe创建一个名为bishe的Scrapy项目,然后我们用Pycharm打开他。因为这个练习和我的毕业设计有点关联,所以我随便起了个bishe这个名字。
2.
然后我们要进入网站看一下,用Chrome打开http://ss.zhizhen.com搜索李,点击只检索作者,进入到如下界面
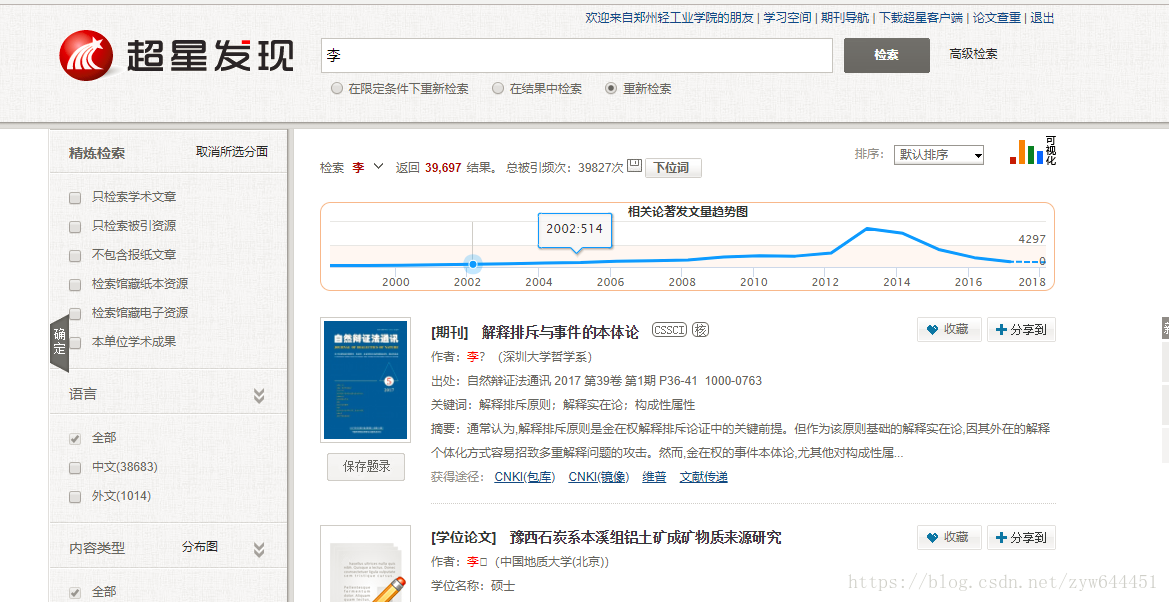
其中折线图下面的词条就是我要爬取的内容,我们使用网页审查,可以看到我们要找的内容存放在下图的div中
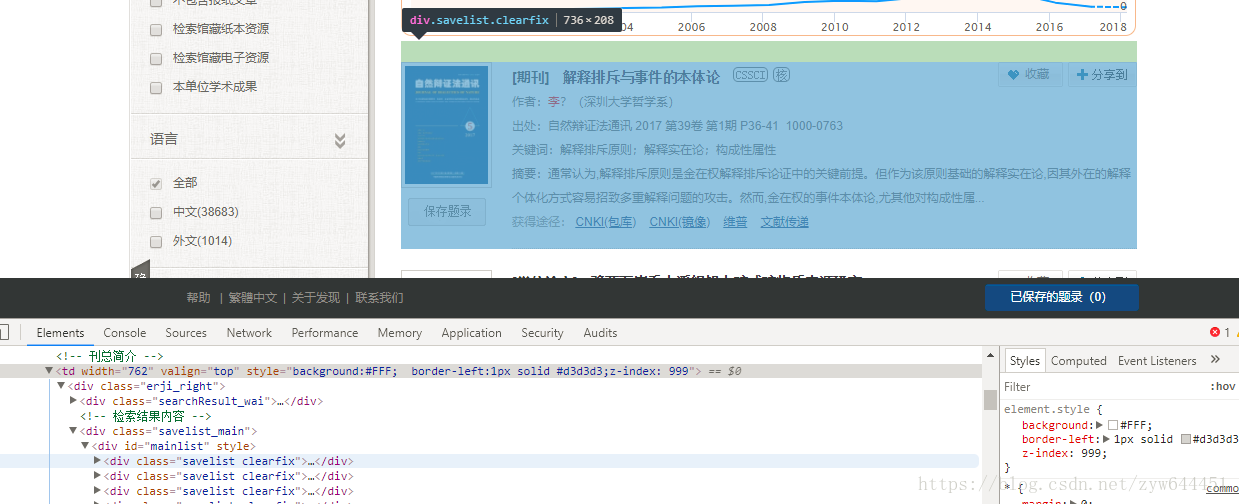
随后我们用同样的方法可以找到文献各个信息的标签,我们可以开始编写代码了。
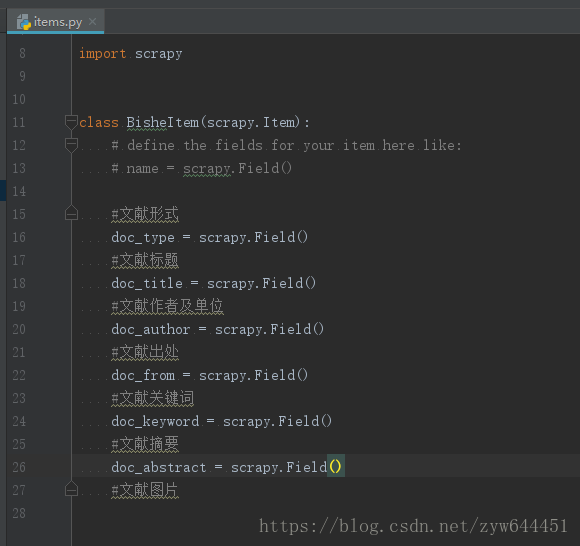
3.找到我们项目中的Item文件,打开后,可以定义我们所需要的item
4.接下来我们在spiders文件下建立一个spider.py文件,这是我们自己的爬虫文件
首先我们在类(class)里面的开头加上
name = "WayneChou"WayneChou是我自己设定的名字
其次我们在def parse(self, response):方法中先实例化一个容器来存放爬取的信息
item = BisheItem()接下来我们便使用xpath来获取需要的信息
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个文献的div
for box in response.xpath('//div[@class="savelist clearfix"]'):
# 获取每个div中的文献形式
item['doc_type'] = box.xpath('.//li[1]/a[1]/text()').extract()[0].strip()
# 获取div中的文献标题
item['doc_title'] = box.xpath('.//li[1]/a[2]/text()').extract()[0].strip()
# 获取div中的作者
item['doc_author'] = box.xpath('.//li[2]/font/text()').extract()[0].strip()
# 获取div中的文献出处
item['doc_from'] = box.xpath('.//li[3]/text()').extract()[0].strip()
# 获取div中的文献关键词
item['doc_keyword'] = box.xpath('.//li[4]/text()').extract()[0].strip()
# 获取div中的文献摘要
item['doc_abstract'] = box.xpath('.//li[5]/text()').extract()
# 获取div中的文献图片
# item['introduction'] = box.xpath('.//p/text()').extract()[0].strip()
# 返回信息
yield item这个方法的内容就是这些,方法前面应设定爬取的地址
start_urls = []这里我们设定为空,本来里面是我传入的url,但是后面出了点问题,改为了空的
这样spider文件就写好了
5.接下来便是pipelines文件,内容很简单
class BishePipeline(object):
def process_item(self, item, spider):
#获取当前工作目录
now_address = os.getcwd()
#文件存储位置
filename = now_address + '/bishe.txt'
#以内存追加的方式打开文件并写入对应数据
with open(filename, 'a',encoding='utf-8') as f:
f.write('\n'+'\n' + item['doc_type'] + '\n')
f.write(item['doc_title'] + '\n')
f.write('作者:' + item['doc_author'] + '\n')
f.write(item['doc_from'] + '\n')
f.write(item['doc_keyword'] + '\n')
f.write(item['doc_abstract'] + '\n')
#下载图片
return item
下载图片的部分我还没写到
6.最后我们在setting中设置一下pipelines
ITEM_PIPELINES = {
'bishe.pipelines.BishePipeline': 1,
}
就OK了~~
7.
最后,在Pycharm中,我们要创建一个开始文件用于启动爬虫
在和bishe与scrapy.cfg文件的同文件层次中建立一个start.py文件
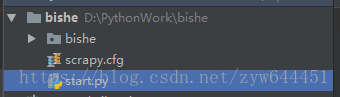
然后写入这两句话
from scrapy import cmdline
cmdline.execute("scrapy crawl WayneChou".split())其中WayneChou这个名字和我们在spider中name=的设置应相同,前面有写过这句。
当我们要运行项目时,就运行这个文件。
结果
结果如下图:

后面还有很多,没截
其实这个程序是有很多问题的,希望不要被大佬看到…..我会努力解决
后记
实际上,在编写代码过程中遇到不少问题,比如
ROBOTSTXT_OBEY = False这里应该改为Flase不然爬虫会失败,原因我不太懂,好像是一个什么协议。
https://blog.csdn.net/yimingsilence/article/details/52119720
这个链接解决了我的问题。
其次就是url跟进时,网页的形式不是下图

而是这种形式:

碰到这种情况,我只能采用笨办法解决诶问题:
#爬取的地址
start_urls = []
# url跟进开始
# 获取下一页的url信息
for i in range(1, 100 ):
start_urls.append('http://ss.zhizhen.com/s?sw=%E6%9D%8E&searchtype=2&size=15&isort=0&x=0_680&pages=' + str(i))将爬取的地址设为空,然后通过for循环解决问题….
完整代码
好了,现在放出完整代码
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BisheItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#文献形式
doc_type = scrapy.Field()
#文献标题
doc_title = scrapy.Field()
#文献作者及单位
doc_author = scrapy.Field()
#文献出处
doc_from = scrapy.Field()
#文献关键词
doc_keyword = scrapy.Field()
#文献摘要
doc_abstract = scrapy.Field()
#文献图片spider.py
# -*- coding: utf-8 -*-
import scrapy as scrapy
from bishe.items import BisheItem
class bishe(scrapy.Spider):
name = "WayneChou"
#允许访问的域
#爬取的地址
start_urls = []
# url跟进开始
# 获取下一页的url信息
for i in range(1, 100 ):
start_urls.append('http://ss.zhizhen.com/s?sw=%E6%9D%8E&searchtype=2&size=15&isort=0&x=0_680&pages=' + str(i))
#爬取的方法
def parse(self, response):
# 实例一个容器保存爬取的信息
item = BisheItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个文献的div
for box in response.xpath('//div[@class="savelist clearfix"]'):
# 获取每个div中的文献形式
item['doc_type'] = box.xpath('.//li[1]/a[1]/text()').extract()[0].strip()
# 获取div中的文献标题
item['doc_title'] = box.xpath('.//li[1]/a[2]/text()').extract()[0].strip()
# 获取div中的作者
item['doc_author'] = box.xpath('.//li[2]/font/text()').extract()[0].strip()
# 获取div中的文献出处
item['doc_from'] = box.xpath('.//li[3]/text()').extract()[0].strip()
# 获取div中的文献关键词
item['doc_keyword'] = box.xpath('.//li[4]/text()').extract()[0].strip()
# 获取div中的文献摘要
item['doc_abstract'] = box.xpath('.//li[5]/text()').extract()
# 获取div中的文献图片
# item['introduction'] = box.xpath('.//p/text()').extract()[0].strip()
# 返回信息
yield itempipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
from scrapy import item
class BishePipeline(object):
def process_item(self, item, spider):
#获取当前工作目录
now_address = os.getcwd()
#文件存储位置
filename = now_address + '/bishe.txt'
#以内存追加的方式打开文件并写入对应数据
with open(filename, 'a',encoding='utf-8') as f:
f.write('\n'+'\n' + item['doc_type'] + '\n')
f.write(item['doc_title'] + '\n')
f.write('作者:' + item['doc_author'] + '\n')
f.write(item['doc_from'] + '\n')
f.write(item['doc_keyword'] + '\n')
f.write(item['doc_abstract'] + '\n')
#下载图片
return itemsetting.py
# -*- coding: utf-8 -*-
# Scrapy settings for bishe project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'bishe'
SPIDER_MODULES = ['bishe.spiders']
NEWSPIDER_MODULE = 'bishe.spiders'
ITEM_PIPELINES = {
'bishe.pipelines.BishePipeline': 1,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'bishe (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = Falsestart.py
from scrapy import cmdline
cmdline.execute("scrapy crawl WayneChou".split())