接着上一篇的文章如何自己实现一个scrapy框架
接着记录一下中间件、日志模块、配置文件的实现
一、中间件
1 为什么需要中间件
中间件相当于一个钩子,能够在其中对request对象和response响应根据特定的需求进行一些特定的处理 例如:对于所有的request对象,我们需要在其中对他添加代理或者是随机的User-Agent都可以在中间件中完成
2 中间件实现的逻辑
框架中的中间件逻辑关系如下图中红色和粉色方块的位置
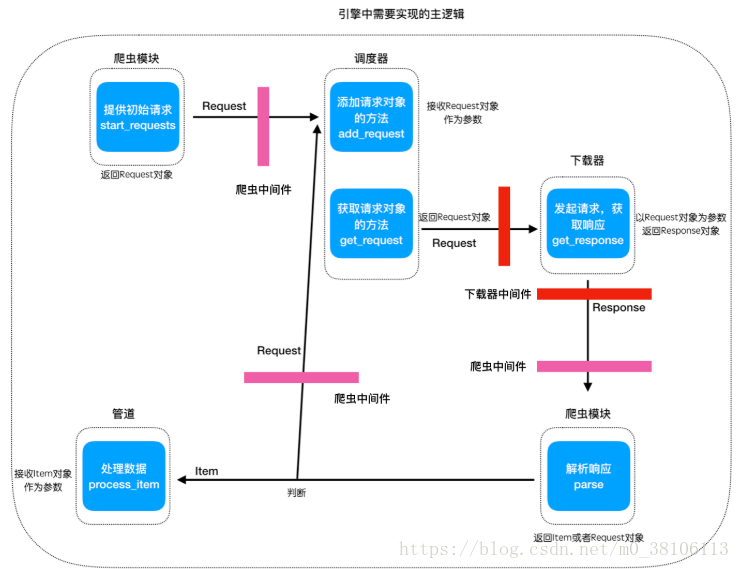
内置中间件的代码结构:
3 完成爬虫中间件spider_middlewares
# scrapy_plus/middlewares/spider_middlewares.py
class SpiderMiddleware(object):
'''爬虫中间件基类'''
def process_request(self, request):
'''预处理请求对象'''
print("这是爬虫中间件:process_request方法")
return request
def process_response(self, response):
'''预处理数据对象'''
print("这是爬虫中间件:process_response方法")
return response二、日志模式的使用
1 为什么要使用添加日志功能
能够方便的对程序进行调试
能够记录程序的运行状态,包括错误
2 日志模块简单使用
日志的等级
import logging
# 日志的五个等级,等级依次递增
# 默认是WARNING等级
logging.DEBUG
logging.INFO
logging.WARNING
logging.ERROR
logging.CRITICAL
# 设置日志等级
logging.basicConfig(level=logging.INFO)
# 使用
logging.debug('DEBUG')
logging.info('INFO')
logging.warning('WARNING')
logging.error('ERROR')
logging.critical('CRITICAL')捕获异常信息到日志
这里主要需要进行捕获异常才能记录下完整的异常信息
try:
raise Exception("异常")
except Exception as e:
logging.exception(e)**日志的输出格式**
对于日志的输出格式,我们能够进行自定义,包括输出的内容格式和时间格式
format格式说明:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息datefmt参数说明:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身3 利用logger封装日志模块
在scrapy_plus目录下建立utils包 (utility:工具),专门放置工具类型模块,如日志模块log.py 下面的代码内容是固定的,在任何地方都可以使用下面的代码实习日志内容的输出
# scrapy_plus/utils/log.py
import sys
import logging
# 默认的配置
DEFAULT_LOG_LEVEL = logging.INFO # 默认等级
DEFAULT_LOG_FMT = '%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s: %(message)s' # 默认日志格式
DEFUALT_LOG_DATEFMT = '%Y-%m-%d %H:%M:%S' # 默认时间格式
DEFAULT_LOG_FILENAME = 'log.log' # 默认日志文件名称
class Logger(object):
def __init__(self):
# 1. 获取一个logger对象
self._logger = logging.getLogger()
# 2. 设置format对象
self.formatter = logging.Formatter(fmt=DEFAULT_LOG_FMT,datefmt=DEFUALT_LOG_DATEFMT)
# 3. 设置日志输出
# 3.1 设置文件日志模式
self._logger.addHandler(self._get_file_handler(DEFAULT_LOG_FILENAME))
# 3.2 设置终端日志模式
self._logger.addHandler(self._get_console_handler())
# 4. 设置日志等级
self._logger.setLevel(DEFAULT_LOG_LEVEL)
def _get_file_handler(self, filename):
'''返回一个文件日志handler'''
# 1. 获取一个文件日志handler
filehandler = logging.FileHandler(filename=filename,encoding="utf-8")
# 2. 设置日志格式
filehandler.setFormatter(self.formatter)
# 3. 返回
return filehandler
def _get_console_handler(self):
'''返回一个输出到终端日志handler'''
# 1. 获取一个输出到终端日志handler
console_handler = logging.StreamHandler(sys.stdout)
# 2. 设置日志格式
console_handler.setFormatter(self.formatter)
# 3. 返回handler
return console_handler
@property
def logger(self):
return self._logger
# 初始化并配一个logger对象,达到单例的
# 使用时,直接导入logger就可以使用
logger = Logger().logger4 在框架中使用日志模块
# scrapy_plus/core/engine.py
from datetime import datetime
from scrapy_plus.utils.log import logger # 导入logger
......
class Engine(object):
......
def start(self):
'''启动整个引擎'''
start = datetime.now() # 起始时间
logger.info("开始运行时间:%s" % start) # 使用日志记录起始运行时间
self._start_engine()
stop = datetime.now() # 结束时间
logger.info("开始运行时间:%s" % stop) # 使用日志记录结束运行时间
logger.info("耗时:%.2f" % (stop - start).total_seconds()) # 使用日志记录运行耗时
......5 运行项目中的main.py
运行效果:
2018-07-03 11:29:20 engine.py [line:36] INFO: 开始运行时间:2018-07-03 11:29:20.445003
这是爬虫中间件:process_request方法
这是下载器中间件:process_request方法
这是下载器中间件:process_response方法
item: <scrapy_plus.item.Item object at 0x7f9ea5ae80f0>
2018-07-03 11:29:20 engine.py [line:39] INFO: 开始运行时间:2018-07-03 11:29:20.490725
2018-07-03 11:29:20 engine.py [line:40] INFO: 耗时:0.05三、配置文件的实现
1 实现框架的默认配置文件
在scrapy_plus下建立conf包文件夹,在它下面建立default_settings.py:设置默认配置的配置
import logging
# 默认的日志配置
DEFAULT_LOG_LEVEL = logging.INFO # 默认等级
DEFAULT_LOG_FMT = '%(asctime)s %(filename)s[line:%(lineno)d] \
%(levelname)s: %(message)s' # 默认日志格式
DEFUALT_LOG_DATEFMT = '%Y-%m-%d %H:%M:%S' # 默认时间格式
DEFAULT_LOG_FILENAME = 'log.log' # 默认日志文件名称再在conf下创建settings.py文件
# scrapy_plus/conf/settings
from .default_settings import * # 全部导入默认配置文件的属性2 在框架中使用
利用框架配置文件改写log.py
# scrapy_plus/utils/log.py
import sys
import logging
from scrapy_plus.conf import settings # 导入框架的settings文件
class Logger(object):
def __init__(self):
# 1. 获取一个logger对象
self._logger = logging.getLogger()
# 2. 设置format对象
self.formatter = logging.Formatter(fmt=settings.DEFAULT_LOG_FMT,datefmt=settings.DEFUALT_LOG_DATEFMT)
# 3. 设置日志输出
# 3.1 设置文件日志模式
self._logger.addHandler(self._get_file_handler(settings.DEFAULT_LOG_FILENAME))
# 3.2 设置终端日志模式
self._logger.addHandler(self._get_console_handler())
# 4. 设置日志等级
self._logger.setLevel(settings.DEFAULT_LOG_LEVEL)
......3 创建项目配置文件,并实现修改框架默认配置文件属性
项目文件夹下创建项目配置文件settings.py:
# project_dir/settings.py
# 修改默认日志文件名称
DEFAULT_LOG_FILENAME = '日志.log' # 默认日志文件名称修改框架的settings.py文件,实现修改默认配置文件属性的目的
# scrapy_plus/conf/settings
from .default_settings import * # 全部导入默认配置文件的属性
# 这里导入的settings,是项目文件夹的settings文件
from settings import *再次安装python setup.py install
注意:不重新安装的话不会显示log信息
然后运行main.py,结果如下:
2018-08-03 19:06:44 engine.py[line:31] INFO: 开始运行时间:2018-08-03 19:06:44.357631
这是爬虫中间件:process_request方法
这是下载器中间件:process_request方法
这是下载器中间件:process_response方法
itme: <scrapy_plus.item.Item object at 0x000001FEAC7C0A58>
2018-08-03 19:06:44 engine.py[line:34] INFO: 开始运行时间:2018-08-03 19:06:44.557097
2018-08-03 19:06:44 engine.py[line:35] INFO: 运行消耗时间:0.20