框架升级 – 分布式爬虫设计原理及其实现
学习内容:
了解分布式的实现原理
了解在redis实现的队列中,put和put_nowait以及get和get_nowait的区别
完成代码的重构,实现分布式
1 分布式爬虫原理
多台服务器同时抓取数据,请求和指纹存储在同一个redis中
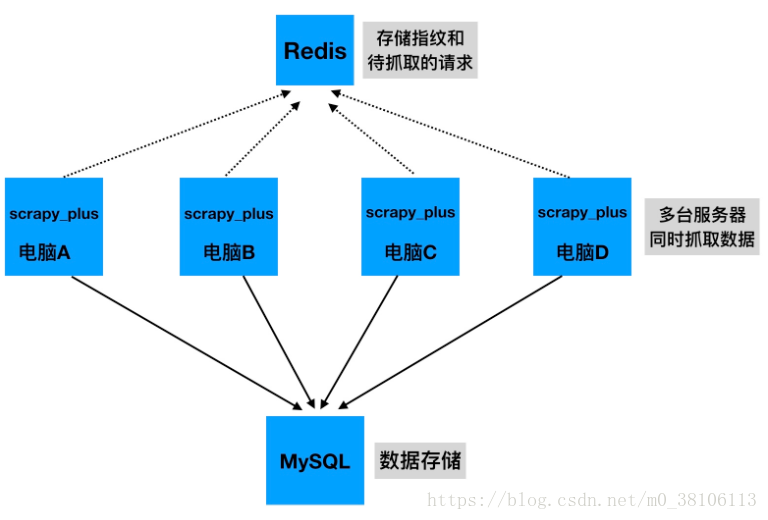
2 实现方案——利用redis实现队列
注意pickle模块的使用:如果将对象存入redis中,需要先将其序列化为二进制数据,取出后反序列化就可以再得到原始对象
接口定义一致性:使用一个Queue利用redis,使其接口同python的内置队列接口一致,可以实现无缝转换
在scrapy_plus包下的utils中添加queue.py文件
import time
import pickle
import redis # 修改requirements.txt
from six.moves import queue as BaseQueue
# 导入redis配置
from ..conf.settings import REDIS_QUEUE_NAME, REDIS_HOST, REDIS_PORT, REDIS_DB
# 利用redis实现一个Queue,使其接口同python的内置队列接口一致,可以实现无缝转换
class Queue(object):
"""基于redis实现的queue队列"""
Empty = BaseQueue.Empty
Full = BaseQueue.Full
max_timeout = 0.3
def __init__(self, maxsize=0, name=REDIS_QUEUE_NAME, host=REDIS_HOST,
port=REDIS_PORT, db=REDIS_DB, lazy_limit=True, password=None):
"""
RedisQueue的构造函数
maxsize:一个整数,用于设置可以放入队列的项目的数量的上限.。
lazy_limit:redis队列通过实例共享,为了更好的表现使用一个惰性的大小限制。
"""
self.name = name
self.redis = redis.StrictRedis(host=host, port=port, db=db, password=password)
self.maxsize = maxsize
self.lazy_limit = lazy_limit
self.last_qsize = 0
def qsize(self):
# 获取redis中name的列表长度,如果没找到就返回-1
self.last_qsize = self.redis.llen(self.name)
return self.last_qsize
def empty(self):
"""通过列表现在长度来判断是否为空"""
if self.qsize() == 0:
return True
else:
return False
def full(self):
"""如果存在最大长度且列表长度大于最大长度就返回True(已经满了),否则为False"""
if self.maxsize and self.qsize() >= self.maxsize:
return True
else:
return False
def put_nowait(self, obj):
if self.lazy_limit and self.last_qsize < self.maxsize:
pass
elif self.full():
raise self.Full
# 往队列中加入一个对象,需要先转化为二进制。rpush加入成功会返回现在的长度
self.last_qsize = self.redis.rpush(self.name, pickle.dumps(obj)) # pickle.dumps(obj)把对象转换为二进制
return True
def put(self, obj, block=True, timeout=None):
"""
等待式的向队列中放入对象
:param obj: 放入队列的对象
:param block: 用于判断是否列表是否为空
:param timeout: 用于设置等待的时间
"""
if not block:
return self.put_nowait(obj)
start_time = time.time()
while True:
try:
return self.put_nowait(obj)
except self.Full:
if timeout:
lasted = time.time() - start_time
if timeout > lasted:
time.sleep(min(self.max_timeout, timeout - lasted))
else:
raise
else:
time.sleep(self.max_timeout)
def get_nowait(self):
"""不等待对象存在,直接取出,取不到就抛出Empty错误"""
ret = self.redis.lpop(self.name) # 从队列左边取一个值
if ret is None: # 如果没有取到
raise self.Empty # 说明队列已经空了,抛出Empty错误
# 如果取到了,就转化为字符串返回
return pickle.loads(ret) # pickle.loads(ret)把二进制字符串转为对象 反序列化
def get(self, block=True, timeout=None):
"""
等待队列存在对象再取出
:param block: 用于判断是否列表是否为空
:param timeout: 用于设置等待的时间
"""
if not block:
return self.get_nowait()
start_time = time.time()
# 使用循环实现等待
while True:
try:
return self.get_nowait()
except self.Empty:
if timeout:
lasted = time.time() - start_time
if timeout > lasted:
# 等待的总时间是timeout,减去前面取对象所消耗的时间保证总时间不变
time.sleep(min(self.max_timeout, timeout - lasted))
else:
raise
# 如果没有设置等待时间,就按默认的最大等待时间来等待
else:
time.sleep(self.max_timeout)3、通过项目配置文件选择是否启用分布式
在scrapy_plus包的默认配置文件中添加
# scrapy_plus/conf/default_settings.py
......
# 设置调度器的内容是否要持久化
# 量个值:True和False
# 如果是True,那么就是使用分布式,同时也是基于请求的增量式爬虫
# 如果是False, 不使用redis队列,会使用python的set存储指纹和请求
SCHEDULER_PERSIST = False
# redis默认配置,默认为本机的redis
REDIS_SET_NAME = 'scrapy_plus_fp_set' # fp集合
REDIS_QUEUE_NAME = 'scrapy_plus_request_queue' # request队列
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
REDIS_DB = 04、利用Redis的集合类型实现去重
如果分布式中请求去重的去重容器各个服务器用的不是同一个,那么就无法达到去重的目的,因此这里同样的需要使用redis来实现去重容器,也就是把所有的去重指纹都存储在redis中
在scrapy_plus/utils/set.py中,实现一个自定义的set:
# scrapy_plus/utils/set.py
import redis
from scrapy_plus.conf import settings
class BaseFilterContainer(object):
def add_fp(self, fp):
'''往去重容器添加一个指纹'''
pass
def exists(self, fp):
'''判断指纹是否在去重容器中'''
pass
class NoramlFilterContainer(BaseFilterContainer):
'''利用python的集合类型'''
def __init__(self):
self._filter_container = set()
def add_fp(self, fp):
''''''
self._filter_container.add(fp)
def exists(self, fp):
'''判断指纹是否在去重容器中'''
if fp in self._filter_container:
return True
else:
return False
class RedisFilterContainer(BaseFilterContainer):
'''利用redis的指纹集合'''
REDIS_SET_NAME = settings.REDIS_SET_NAME
REDIS_SET_HOST = settings.REDIS_HOST
REDIS_SET_PORT = settings.REDIS_PORT
REDIS_SET_DB = settings.REDIS_DB
def __init__(self):
self._redis = redis.StrictRedis(host=self.REDIS_SET_HOST, port=self.REDIS_SET_PORT ,db=self.REDIS_SET_DB)
self._name = self.REDIS_SET_NAME
def add_fp(self, fp):
'''往去重容器添加一个指纹'''
self._redis.sadd(self._name, fp)
def exists(self, fp):
'''判断指纹是否在去重容器中'''
return self._redis.sismember(self._name, fp) # 存在返回1 不存在返回0修改scheduler.py,在调度器中使用这个set.py, 使得分布式模式下的去重功能正常运作
# scrapy_plus/core/scheduler.py
......
# 此处新增
from scrapy_plus.utils.queue import Queue as ReidsQueue
from scrapy_plus.conf.settings import SCHEDULER_PERSIST
from scrapy_plus.utils.set import NoramlFilterContainer, RedisFilterContainer
class Scheduler():
"""
缓存请求对象(Request),并为下载器提供请求对象,实现请求的调度:
对请求对象进行去重判断:实现去重方法_filter_request,该方法对内提供,因此设置为私有方法
"""
# 此处修改
def __init__(self, collector):
if SCHEDULER_PERSIST: #如果使用分布式或者是持久化,使用redis的队列
self.queue = ReidsQueue()
self._filter_container = RedisFilterContainer() # 使用redis作为python的去重的容器
else:
self.queue = Queue()
self._filter_container = NoramlFilterContainer() # 使用Python的set()集合
self.repeate_request_num = 0 # 统计重复的数量
# 在engine中阻塞的位置判断程序结束的条件:成功的响应数+重复的数量>=总的请求数量
# self._filter_container = set() # 去重容器,是一个集合,存储已经发过的请求的特征 url
......
def _filter_request(self, request):
"""去重方法"""
request.fp = self._gen_fp(request) # 给request对象增加一个fp指纹属性
# if request.fp not in self._filter_container:
# 此处修改
if not self._filter_container.exists(request.fp):
# 此处修改
self._filter_container.add_fp(request.fp) # 向指纹容器集合添加一个指纹
return True
else:
self.repeate_request_num += 1
logger.info("发现重复的请求:<{} {}>".format(request.method, request.url))
return False此时运行项目程序会出现异常:
TypeError: put() missing 1 required positional argument: 'item'解决:
(1)开启redis服务
(2)正确配置redis
(3)在项目的settings.py中设置SCHEDULER_PERSIST = True
5、程序结束的条件
在之前的单机版本的代码中,通过:总的响应+总的重复数>=总的请求来判断程序结束,但是在分布式的版本那种,每个服务器的请求数量和响应数量不在相同
因为每个服务器存入队列的请求,和成功发送的请求中间可能很多请求被其他的服务器发送了,导致数量不一致,所以可以把总的请求,总的响应,总的重复等信息记录在redis中,那么所有的服务端修改的数据的位置是同一个redis中的内容,所有的服务端判断退出的时候也是通过比较同一个redis中的这些数据来决定
此时,在utils中新建stats_collector.py文件,来实现对各种数量的统计,包括总的请求数量,总的响应数量,总的重复数量
为了保证在使用redis和未使用redis的情况下统计数量的方法相同,故封装了两个版本的StatsCollector对象,分别使用内存中的字典和redis来统计数量
# scrapy_plus/utils/stats_collector.py
import redis
from scrapy_plus.conf.settings import REDIS_HOST, REDIS_PORT, REDIS_DB, FP_PERSIST, REDIS_SET_NAME
class NormalStatsCollector(object):
def __init__(self, spider_names=[]):
#存储请求数量的键
self.request_nums_key = "_".join(spider_names) + "_request_nums"
#存储响应数量的键
self.response_nums_key = "_".join(spider_names) + "_response_nums"
#存储重复请求的键
self.repeat_request_nums_key = "_".join(spider_names) + "_repeat_request_nums"
#存储start_request数量的键
self.start_request_nums_key = "_".join(spider_names) + "_start_request_nums"
#初始化收集数据的字典
self.dict_collector = {
self.request_nums_key :0,
self.response_nums_key:0,
self.repeat_request_nums_key:0,
self.start_request_nums_key:0
}
def incr(self, key):
self.dict_collector[key] +=1
def get(self, key):
return self.dict_collector[key]
def clear(self):
del self.dict_collector
@property
def request_nums(self):
'''获取请求数量'''
return self.get(self.request_nums_key)
@property
def response_nums(self):
'''获取响应数量'''
return self.get(self.response_nums_key)
@property
def repeat_request_nums(self):
'''获取重复请求数量'''
return self.get(self.repeat_request_nums_key)
@property
def start_request_nums(self):
'''获取start_request数量'''
return self.get(self.start_request_nums_key)
class RedisStatsCollector(object):
def __init__(self, spider_names=[],
host=REDIS_HOST, port=REDIS_PORT,
db=REDIS_DB, password=None):
self.redis = redis.StrictRedis(host=host, port=port, db=db, password=password)
#存储请求数量的键
self.request_nums_key = "_".join(spider_names) + "_request_nums"
#存储响应数量的键
self.response_nums_key = "_".join(spider_names) + "_response_nums"
#存储重复请求的键
self.repeat_request_nums_key = "_".join(spider_names) + "_repeat_request_nums"
#存储start_request数量的键
self.start_request_nums_key = "_".join(spider_names) + "_start_request_nums"
def incr(self, key):
'''给键对应的值增加1,不存在会自动创建,并且值为1,'''
self.redis.incr(key)
def get(self, key):
'''获取键对应的值,不存在是为0,存在则获取并转化为int类型'''
ret = self.redis.get(key)
if not ret:
ret = 0
else:
ret = int(ret)
return ret
def clear(self):
'''程序结束后清空所有的值'''
self.redis.delete(self.request_nums_key, self.response_nums_key,
self.repeat_request_nums_key, self.start_request_nums_key)
# 判断是否清空指纹集合
if not FP_PERSIST: # not True 不持久化,就清空指纹集合
self.redis.delete(REDIS_SET_NAME)
@property
def request_nums(self):
'''获取请求数量'''
return self.get(self.request_nums_key)
@property
def response_nums(self):
'''获取响应数量'''
return self.get(self.response_nums_key)
@property
def repeat_request_nums(self):
'''获取重复请求数量'''
return self.get(self.repeat_request_nums_key)
@property
def start_request_nums(self):
'''获取start_request数量'''
return self.get(self.start_request_nums_key)修改scheduler.py调度器代码
# scrapy_plus/core/scheduler.py
......
class Scheduler():
"""
缓存请求对象(Request),并为下载器提供请求对象,实现请求的调度:
对请求对象进行去重判断:实现去重方法_filter_request,该方法对内提供,因此设置为私有方法
"""
def __init__(self, collector): # 此处修改
if SCHEDULER_PERSIST: #如果使用分布式或者是持久化,使用redis的队列
self.queue = ReidsQueue()
self._filter_container = RedisFilterContainer() # 使用redis作为python的去重的容器
else:
self.queue = Queue()
self._filter_container = NoramlFilterContainer()
# 此处修改
# self.repeate_request_num = 0 # 统计重复的数量
self.collector = collector
......
def _filter_request(self, request):
"""去重方法"""
request.fp = self._gen_fp(request) # 给request对象增加一个fp指纹属性
# if request.fp not in self._filter_container:
if not self._filter_container.exists(request.fp):
self._filter_container.add_fp(request.fp) # 向指纹容器集合添加一个指纹
return True
else:
# 此处修改
# self.repeate_request_num += 1
self.collector.incr(self.collector.repeat_request_nums_key)
logger.info("发现重复的请求:<{} {}>".format(request.method, request.url))
return False
......在框架的default_settings文件中设置持久化:
scrapy_plus/conf/default_settings.py
·····
# 指定redis中的数据是否持久化
FP_PERSIST = False修改engine.py
# coding=utf-8
......
from scrapy_plus.utils.stats_collector import RedisStatsCollector # 此处新增
from scrapy_plus.conf.settings import SCHEDULER_PERSIST
class Engine():
def __init__(self):
self.spiders = self._auto_import_instances(SPIDERS, isspider=True)
if SCHEDULER_PERSIST:
self.collector = RedisStatsCollector() #新增
else:
# self.total_request_nums = 0 # 修改
# self.total_response_nums = 0 # 修改
self.collector = NormalStatsCollector() #新增
self.scheduler = Scheduler(self.collector)
self.downloader = Downloader()
self.pipelines = self._auto_import_instances(PIPELINES)
self.spider_mids = self._auto_import_instances(SPIDER_MIDDLEWARES)
self.downloader_mids = self._auto_import_instances(DOWNLOADER_MIDDLEWARES)
self.pool = Pool()
self.is_running = False # 判断程序是否需要结束的标志
......
# 此处修改--增加了更为详细的日志记录
def start(self):
"""启动引擎"""
t_start = datetime.now()
logger.info("爬虫开始启动:{}".format(t_start))
logger.info("爬虫运行模式:{}".format(ASYNC_TYPE))
logger.info("最大并发数:{}".format(MAX_ASYNC_THREAD_NUMBER))
logger.info("启动的爬虫有:{}".format(list(self.spiders.keys())))
logger.info("启动的下载中间件有:\n{}".format(DOWNLOADER_MIDDLEWARES))
logger.info("启动的爬虫中间件有:\n{}".format(SPIDER_MIDDLEWARES))
logger.info("启动的管道有:\n{}".format(PIPELINES))
self._start_engine()
t_end = datetime.now()
logger.info("爬虫结束:{}".format(t_end))
logger.info("耗时:%s" % (t_end - t_start).total_seconds())
# logger.info("一共获取了请求:{}个".format(self.total_request_nums))
# logger.info("重复的请求:{}个".format(self.scheduler.repeate_request_num))
# logger.info("成功的请求:{}个".format(self.total_response_nums))
logger.info("一共获取了请求:{}个".format(self.collector.request_nums))
logger.info("重复的请求:{}个".format(self.collector.repeate_request_nums))
logger.info("成功的请求:{}个".format(self.collector.response_nums))
self.collector.clear() # 清除redis中所有的计数的值,但不清除指纹集合
def _start_request(self):
"""单独处理爬虫模块中start_requests()产生的request对象"""
......
# 改用collector进行数据的收集
# self.total_request_nums += 1
self.collector.incr(self.collector.request_nums_key)
def _execute_request_response_item(self):
"""处理解析过程中产生的request对象"""
......
# 请求数+1
# self.total_request_nums += 1
# 改用collector进行数据的收集
self.collector.incr(self.collector.request_nums_key)
# 如果不是,调用pipeline的process_item方法处理结果
else:
# 就通过process_item()传递数据给管道
for pipeline in self.pipelines:
pipeline.process_item(result, spider)
# 改用collector进行数据的收集
# self.total_response_nums += 1
self.collector.incr(self.collector.response_nums_key)
......
def _start_engine(self):
"""具体实现引擎的逻辑"""
self.is_running = True # 启动引擎,设置状态为True
# 处理strat_urls产生的request
# self._start_request()
self.pool.apply_async(self._start_request) # 使用异步线程池中的线程执行指定的函数
# 不断的处理解析过程中产生的request
for i in range(MAX_ASYNC_THREAD_NUMBER): # 控制最大并发数
self.pool.apply_async(self._execute_request_response_item, callback=self._call_back, error_callback=self._error_callback)
# 控制判断程序何时中止
while True:
time.sleep(0.001) # 避免cpu空转,避免性能消耗
# if self.total_response_nums != 0: # 因为异步,需要增加判断,响应数不能为0
# # 成功的响应数+重复的数量>=总的请求数量 程序结束
# if self.total_response_nums + self.scheduler.repeat_request_num >= self.total_request_nums:
# self.is_running = False
# break
# 此处修改
if self.collector.request_nums != 0: # 注意这个地方不能用response_nums作为判断标准了!
if self.collector.response_nums+self.collector.repeat_request_nums >= self.collector.request_nums:
self.is_running = False
break此时,我们的scrapy_plus已经不能没有redis了,脱离redis将无法正常统计各种数量,我们会在后边优化这一点!
s
六、修改项目中的settings文件
·····
# 使用redis调度器
SCHEDULER_PERSIST = True重装后运行,可以在redis客户端中显示
redis 127.0.0.1:6379> keys *
1) "scrapy_plus_fp_set"
2) "_response_nums"