原文作者:过一点画一条直线(知乎ID)
知乎专栏:数据化风控
原文链接:https://zhuanlan.zhihu.com/p/94619990
业务背景
评分卡模型监控主要可以分为前端分析(Front-End)和后端分析(Back-End),其中前端分析主要关注人群的稳定性,后端分析主要关注模型的影响和表现。本文主要介绍前端分析中的 Population Stability Index (PSI)和 Characteristic Stability Index (CSI),它们是监控模型稳定性的重要指标。
前端分析 —— 监控评分卡开发样本和现有样本分数分布的差异程度,关注样本人群的稳定性。本文主要介绍以下评估指标:
1. Population Stability Index (PSI):群体稳定性指标,用来衡量分数分布的变化
2. Characteristic Stability Index (CSI):特征稳定性指标,用来衡量特征层面的变化
目录
Part 1. Population Stability Index
Part 2. Characteristic Stability Index
Part 3. 总结
版权声明
参考资料
前端分析
前端分析主要关注的是评分卡模型的稳定性,这其中包含了模型分数的稳定性和入模特征的稳定性。模型分数的稳定性是至关重要的,因为对于评分卡而言每档的分数对应于一定的坏账率,策略根据训练样本分数和坏账率的关系确定cutoff,并进行线上决策。如果模型分数在当前样本上发生严重偏移,则直接影响线上决策的结果,例如:通过率的提升(坏人被通过),通过率的降低(好人被拒绝),出额定价的不准确等。特征的稳定性和模型分数的稳定性息息相关,特别是那些重要性强的特征,它们分布的微小变动都会造成模型分数的偏移。
对于风控模型来说,稳定性是非常重要的指标,对于那些需要在线上作用半年及以上的模型来说,保证模型的稳定性是及其关键的。
Part 1. Population Stability Index
PSI 用来衡量分数在开发样本和近期样本上的分布变化,反映了分数分布的稳定性。例如对于信用评分卡,如果模型在近期样本上分数分布偏高或者偏低,都会导致近期样本上的PSI变高。在计算PSI的时候,常常以开发样本上的分数分布作为基准(benchmark)。
PSI的计算公式可以写成:
结合图1示例,下面介绍PSI的计算步骤:
1. 选定基准样本(Beachmark)作为预期分布(Excepted),一般以训练样本作为Beachmark。
2. 对预期分布进行分箱,得到每箱样本占比(该箱样本数/总样本数)。一般按照等频方法(每箱的样本数相等)进行分箱,箱数一般设为10。
3. 按预期分布分箱阈值对实际分布(Actual)进行分箱,计算每箱样本占比。
4. 按公式 (实际占比-预期占比)/LN(实际占比/预期占比) 计算每箱的Index。
5. 累加每箱的Index得到最后的PSI。
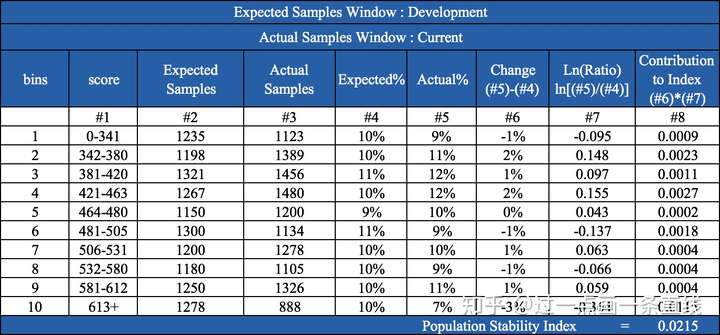
根据上面步骤的计算,我们可以得到一个变量的PSI值,PSI值越小,最稳定性越强。通过下面的“经验阈值”可以判断变量分布的稳定性情况:
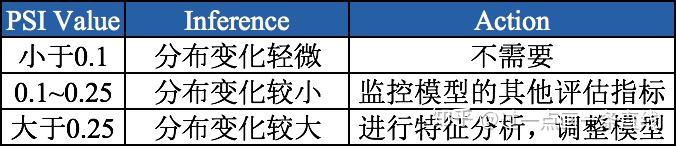
虽然 PSI可以用来衡量分数分布的变化,但是不能反映分数分布变化的走向(整体往高分段偏移还是往低分段偏移)
Part 2. Characteristic Stability Index
CSI 用来衡量样本在特征层面上的分布变化,反映了特征对评分卡分数变化的影响。当评分卡主模型分数发生变化时,对每个特征计算CSI,可以知道哪些特征分布发生变化从而导致的评分卡主模型分数偏移以及哪个特征对模型得分变化的影响最大。因此监控特征的CSI指标可以在评分卡主模型发生偏移时快速定位问题。一般来说,特征层面的监控既包含了PSI,也包含了CSI。

CSI的计算公式可以写成:
以图3为例,下面我们介绍CSI的计算步骤:
1. 以训练样本作为预期分布(Excepted),根据评分卡主模型训练过程中每个特征的分箱阈值,对预期样本进行分箱,得到每箱样本占比(该箱样本数/总样本数)。
2. 按预期分布分箱阈值对实际分布(Actual)进行分箱,计算每箱样本占比。
3. 按公式 (实际占比-预期占比)*每箱得分 计算每箱的分数偏差。
4. 累加每箱的分数偏差得到最后的CSI
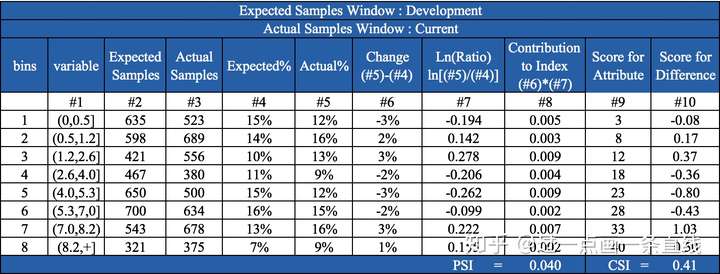
看到这里可能会有几个疑问:
Q1:从图3中我们知道该特征的CSI为0.41,那CSI是否和PSI一样,有一套对应的评估标准?
Q2:在图3中每个分箱内的得分都为正数,如果特征得分有正有负,会改变特征的CSI吗?
Q3:如图3中所示,每个分箱计算得到的分数偏差有实际含义吗?
对于Q1,从上面对PSI的介绍中我们可以知道,因为影响PSI计算结果的因素只有样本分布的变化,因此可以定义相应的“经验阈值”来作为分布变化大小的评估标准。而从CSI的计算公式可以知道,影响其计算结果的因素除了特征分布的变化外,还包括特征对主模型得分的“贡献”。例如,对于变量A和B,变量A对主模型的贡献远大于变量B,这会导致变量A分布的轻微变化时的CSI可能也远大于变量B分布发生巨大变化时的CSI。因此不同变量之间的CSI也是不可比的,这也造成了CSI不像PSI一样,有一套“经验阈值”来区分分数分布变化的大小。说到这,不得不提一下,因为CSI的计算涉及特征不同分箱的得分,因此该指标并不适用于一般的机器学习模型(树模型等)。
对于Q2,在评分卡的训练过程中,特征每个分箱的得分往往存在有正有负,这对CSI的计算没有影响。换句话说,只要保证每个分箱之间的相对差值相等,对所有分箱加上或者减去固定的分数,对CSI的计算没有任何影响。
例如,变量A的期望分布占比为 ( a 1 , a 2 , . . . , a i ) (a_1,a_2,...,a_i) (a1,a2,...,ai) ,实际分布占比为 ( b 1 , b 2 , . . . , b i ) (b_1,b_2,...,b_i) (b1,b2,...,bi) ,每箱得分为 ( n 1 , n 2 , . . . , n i ) (n_1,n_2,...,n_i) (n1,n2,...,ni)
其中 ,
,则变量A的CSI为:
对每箱得分加上固定分数 m,则改变后的CSI为:
对于Q3,每个分箱计算得到的分数偏差的绝对值,反映了该特征当前分箱分布的变化对模型整体分数的影响。当该特征的CSI为正时,则表明该特征分布变化使模型得分往高分偏移,当CSi为负时,则相反。
Part 3. 总结
可以说,PSI和CSI是对评分卡主模型分数以及入模变量进行监控的一大利器,它们不仅可以实时反映模型的稳定性,也可以快速发现问题,定位问题(客群变化引起、变量变化引起等),从而找到有效的解决方案。
注:文中数据均为虚构