信用评定等级划分之后需要对评级的划分做出评价,分析这样的评级划分结果是否具有实用价值,即分析样本分布的稳定程度。样本分布稳定,则信用评定等级划分结果的实用价值就高。采用样本稳定指数( PSI )检验样本分布的稳定程度,若训练样本和测试样本在分布上表现一致,样本稳定指数的取值就会接近于零,信用评级划分结果的可靠性就会很高;若训练样本和测试样本在分布上差异很大,样本稳定指数的取值就会变大,信用评级划分结果的可靠性就会很低。样本稳定指数大于 0.10 ,即认为训练样本和测试样本分布上发生了轻微的改变;样本稳定指数大于 0.25 ,认为训练样本和测试样本分布上发生了比较明显的改变,应该警惕。
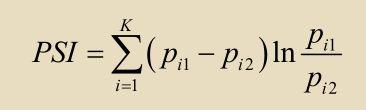
K 代表信用等级数,pi1 代表训练样本在第 i 个信用等级上的违约概率,pi2代表测试样本在第 i 个信用等级上的违约概率。
import numpy as np y1_train_prob = np.array([0.1,0.7,0.7,0.3,0.5,0.8]) y1_pred_prob = np.array([0.1,0.4,0.1]) def psi(y1_train_prob,y1_pred_prob,k=8,eps=1e-10): """ param y1_train_prob:训练数据预测1的概率 param y1_pred_prob: 预测数据预测1的概率 param k: 等级个数 param eps:数值稳定系数 return :psi """ y1_train_prob = np.sort(y1_train_prob) y1_pred_prob = np.sort(y1_pred_prob) len_train = len(y1_train_prob) len_pred = len(y1_pred_prob) num_K_train = [] #训练样本每个信用等级的计数占比 num_K_test = [] #预测样本每个信用等级的计数占比 i = 0 while i<=1: temp1 = len(y1_train_prob[y1_train_prob<(i+1/k)])-len(y1_train_prob[y1_train_prob<i]) num_K_train.append(temp1/len_train)
temp2 = len(y1_pred_prob[y1_pred_prob<(i+1/k)])-len(y1_pred_prob[y1_pred_prob<i]) num_K_test.append(temp2/len_pred) i= i+1/k Sum = 0.0 #存储psi值 for i in range(k): left = num_K_train[i]-num_K_test[i] right = (num_K_train[i]+eps)/(num_K_test[i]+eps) Sum = Sum + left*np.log(right) return round(Sum,3) psi(y1_train_prob,y1_pred_prob,k=10)