因为课程学习需要,配置英伟达的cuda环境做高性能计算的测试。
1.cuda的安装
首先要去英伟达的官网下载安装cuda,安装路径可以自由选择,但是为了方便操作建议直接全部默认安装。
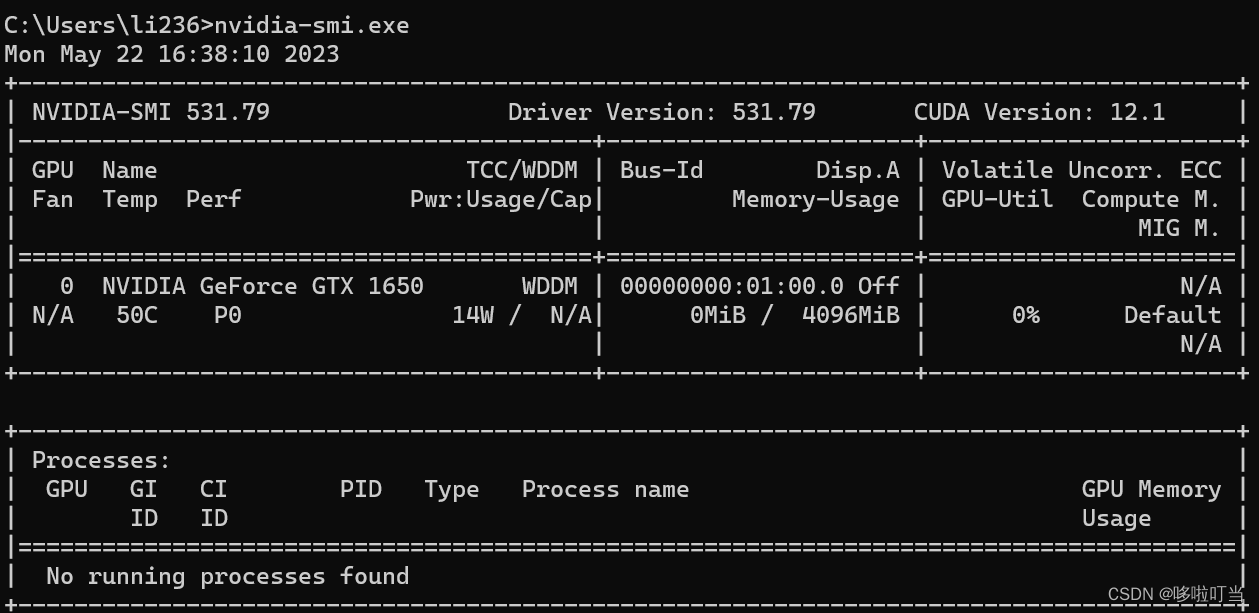
可以现在命令行执行nvidia-smi.exe查看目前显卡支持的最高cuda版本,右上角的cuda version就是我们要确认的版本,下载的cuda不应该比这个版本新。
cuda下载入口:CUDA Toolkit 12.1 Update 1 Downloads | NVIDIA Developer
进去后选择对应的平台和版本
2.检查环境配置
正常情况下安装完成后是会自动配置环境变量的,但是为了保险我们还是去命令行看一下

执行nvcc -V,若可以正常显示版本号等信息,说明正常安装。
3.配置vscode
cuda编程用的是.cu文件,我这里为了操作简单用了coderunner插件,配置.cu文件的编译
点击小齿轮选择扩展设置
我们直接在settings.json中编辑
在"code-runner.executorMap": {}中加入cu文件的编译语句
"cu": "cd $dir; nvcc $fileName -o $fileNameWithoutExt.exe -I'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.7\\include\\CL' && $dir$fileNameWithoutExt",
//请设置和你的安装路径一致的地址然后我们在.cu文件的右上角点击运行符号选择用coderunner运行
下面是一个测试小程序
#include <iostream>
#include <math.h>
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<25;
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
add<<<1, 1>>>(N, x, y);
cudaDeviceSynchronize();
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
cudaFree(x);
cudaFree(y);
return 0;
}正常运行结果如下

这里可能会返回一个错误,大意是在path找不到cl.exe
如果是这个情况我们可以添加一个path系统环境变量
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\bin\Hostx64\x64
//注意这里要找到你电脑上的visual studio安装路径,找到这个文件,bin目录下面可能有两个文件夹,但是cuda运行一定要选择x64然后重启你的vscode,再用coderunner就能正常运行啦