接着上一节,我们已经了解了数据分割的具体方法和操作流程,当完成训练及测试数据的提取后,我们就可以针对特定模型进行性能度量。
(1)混淆矩阵
首先需要明确一个概念,对于完成训练的预测模型m,使用测试数据x_test输入该模型可以得到其基于训练数据的预测结果y_predict, 因此模型的性能度量可以通过y_predict(代表模型的预测特征值)和y_test(代表原数据集的特征值)两个变量来计算。我们从简单的二分类问题(下面解释中以1,0表示True,Flase方便理解)入手,通过对比y_predict和y_test可以产生TP,FP,TN,FN四个值。下面是具体解释:
TP(True Positive)真正例:预测结果y_predict[i]为1,对应测试结果y_test[i]为1,即模型对于该正例元素判断为真(正确)
FP(False Positive)假正例:预测结果y_predict[i]为1,对应测试结果y_test[i]为0,即模型对于该反例元素判断为真(错误)
TN(True Negative)真反例:预测结果y_predict[i]为0,对应测试结果y_test[i]为0,即模型对于该反例元素判断为假(正确)
FN(False Negative)假反例:预测结果y_predict[i]为0,对应测试结果y_test[i]为1,即模型对于该正例元素判断为假(错误)
这里引入两个重要的参数precision(准确率)和recall(查全率)
precision=TP/TP+FP
recall = TP/TP+FN
sensitivity = TP/TP+FN
specificity = TN/FP+TN
要是觉得还不好理解,我在维基百科上找到了这个图:
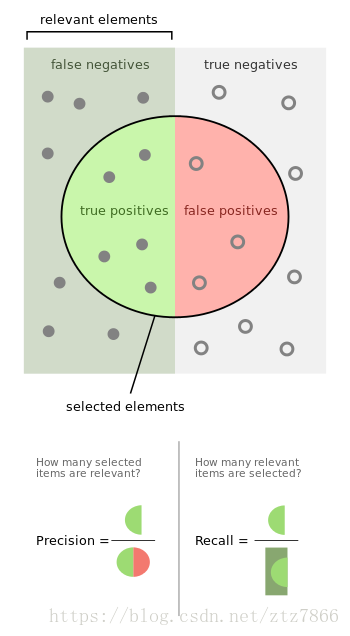
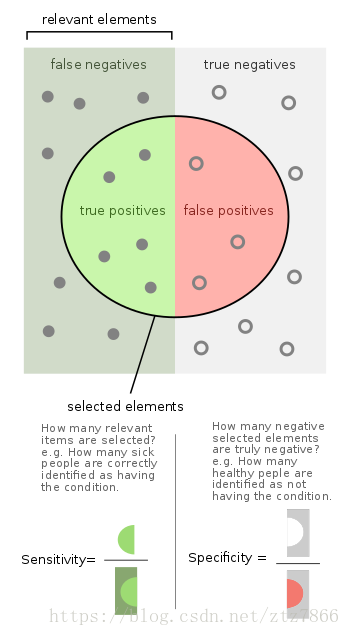
这个图咋理解呢,圆圈的边界代表训练模型的真假判断阈值,圈子里面代表模型判断是真的元素(y_predict=1),圈子外是模型认为是假的元素(y_predict=0);垂直的阴影分割线代表实际测试集的真实标签值边界,左侧矩形区域为真(y_test=1),右侧矩形区域为假(y_test=0)。从二者的交叉关系中我们可以很容易看出TP,FP,FN,TN以及precision,recall等代表的实际含义。可以发现sensitivity=recall,二者是一个意义。在之后我们会见到这样划分是因为precision和recall对应PR曲线,Sensitivity和Specificity对应ROC曲线。
TP,FP,TN,FN共同构成了一个(2,2)的矩阵,我们称之为混淆矩阵,这是用于评估模型性能的基本数据来源
(2)F1-score
一图胜千言
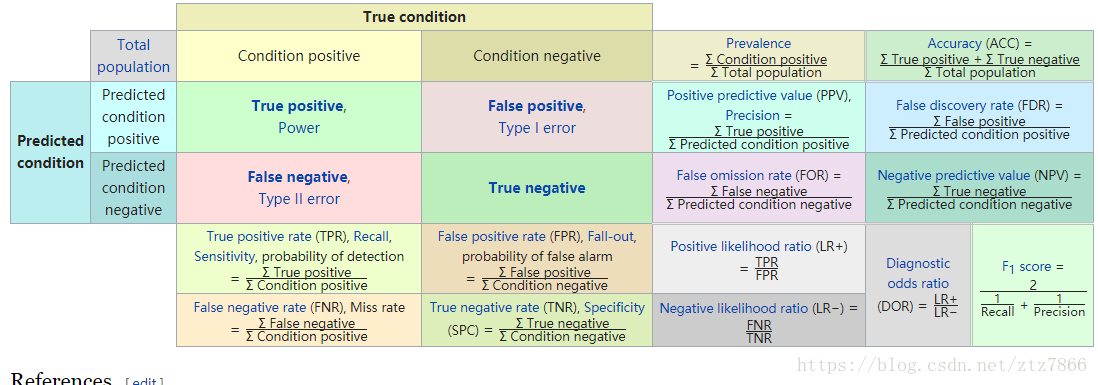
前文说过precision和recall为横纵坐标可以画一个”PR图“,这个图像可以直观评估模型的相关性能 ,对于连续变化的PR值,如何计算模型的性能成为了一个问题,这里给定F1-score作为评估模型性能的一个较好标准:
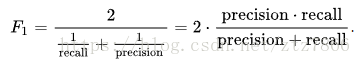
然而到目前为止我们讨论的还都是二分类问题,这时只有一个混淆矩阵,当时当面对多分类问题(如下图)时,我们会得到多个混淆矩阵.
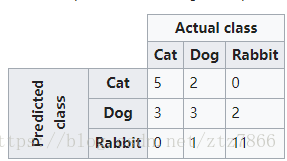
这时每种情况下的混淆矩阵元素的生成需要将已有多变量进行转化为二分类模式依次得出:

这里给出单看”是否是猫“的计算情景,其他矩阵元素按相同方法依次得出。
得出了这些矩阵值后我们也获得了相应每个矩阵的(P1,R1)(P2,R2)...(Pn,Rn)
在计算最后的平均F1-score时有两种方法,一种是将每组矩阵分别计算F1-score最后再将多个F1-score平均,这种方法称之为”宏F1“(macro-F1):
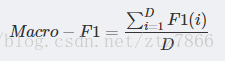
第二种方法是将所有矩阵对应元素进行平均,然后用新的平均后的P,R变量计算出F1,这称之为”微平均“(micro-F1)
下面给出代码:
import numpy as np from sklearn.metrics import precision_recall_fscore_support from sklearn.metrics import classification_report y_true = np.array(['cat', 'dog', 'pig', 'cat', 'dog', 'pig']) y_pred = np.array(['cat', 'pig', 'dog', 'cat', 'cat', 'dog']) print(precision_recall_fscore_support(y_true, y_pred, average='macro')) #Macro-P,Macro-R,Macro-F1 print(precision_recall_fscore_support(y_true, y_pred, average='micro')) #Micro-P,Micro-R,Micro-F1 print(classification_report(y_true, y_pred))
(0.22222222222222221, 0.33333333333333331, 0.26666666666666666, None)
(0.33333333333333331, 0.33333333333333331, 0.33333333333333331, None)
cat 0.67 1.00 0.80 2
dog 0.00 0.00 0.00 2
pig 0.00 0.00 0.00 2
avg / total 0.22 0.33 0.27 6
一般使用封装好的classification_report就可以,比较省事。
参考资料:
https://en.wikipedia.org/wiki/Sensitivity_and_specificity
https://en.wikipedia.org/wiki/Confusion_matrix
https://en.wikipedia.org/wiki/F1_score