1·回归
在回归模型中,我们需要预测的变量叫做因变量,比如产品质量;选取用来解释因变量变化的变量叫做自变量,比如用户满意度。回归的目的就是建立一个回归方程来预测目标值,整个回归的求解过程就是求这个回归方程的回归系数。
给出一个点集,构造一个函数来拟合这个点集,并且尽可能的让该点集与拟合函数间的误差最小,如果这个函数曲线是一条直线,那就被称为线性回归,如果曲线是一条三次曲线,就被称为三次多项回归。
2·线性回归
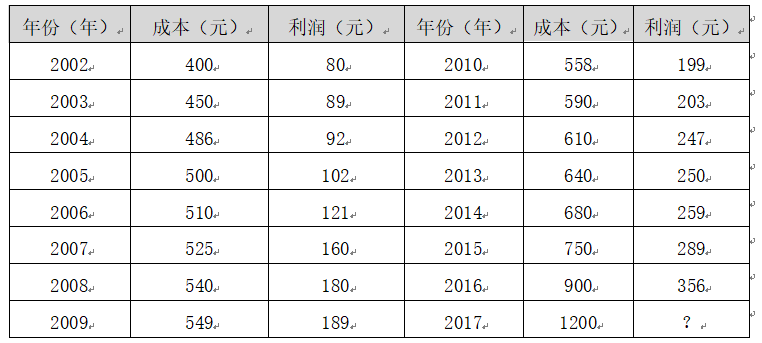
假设存在表中的数据集,它是某企业的成本和利润数据集。数据集中2002年到2016年的数据集称为训练集,整个训练集共15个样本数据。重点是成本和利润两个变量,成本是输入变量或一个特征,利润是输出变量或目标变量。

建立模型,x表示企业成本,y表示企业利润,h(Hypothesis)表示将输入变量映射到输出变量y的函数,对应一个因变量的线性回归(单变量线性回归)公式如下:
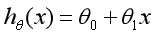
那么,现在要解决的问题是如何求解的两个参数和。我们的构想是选取的参数和使得函数尽可能接近y值,这里提出了求训练集(x,y)的平方误差函数(Squared Error Function)或最小二乘法。在回归方程里,最小化误差平方和方法是求特征对应回归系数的最佳方法。误差是指预测y值和真实y值之间的差值,使用误差的简单累加将使得正差值和负差值相互抵消,所采用的平方误差(最小二乘法)如下:
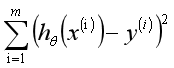
在数学上,求解过程就转化为求一组值使上式取到最小值,最常见的求解方法是梯度下降法。根据平方误差,定义该线性回归模型的损失函数为,公式如下:
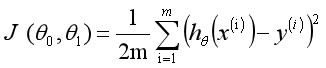
通过运用梯度下降方法得到适当的参数让其最小化min,即可实现拟合求解过程。通过上面的这个示例,我们就可以对线性回归模型进行如下定义:根据样本x和y的坐标,去预估函数h,寻求变量之间近似的函数关系。公式如下:
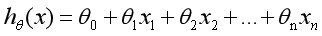
其中,n表示特征数目,表示每个训练样本的第i个特征值,当只有一个因变量x时,称为一元线性回归,类似于;而当多个因变量时,成为多元线性回归。我们的目的是使最小化,从而最好的将样本数据集进行拟合,更好地预测新的数据。
公式的有关补充:
- m是数据集中点的个数
- ½是一个常量,这样是为了在求梯度的时候,二次方乘下来就和这里的½抵消了,自然就没有多余的常数系数,方便后续的计算,同时对结果不会有影响
- y 是数据集中每个点的真实y坐标的值
h 是我们的预测函数,根据每一个输入x,根据Θ 计算得到预测的y值
代价函数中的变量有两个,所以是一个多变量的梯度下降问题,求解出代价函数的梯度,也就是分别对两个变量进行微分

未理解部分:
为了方便代码的编写,我们会将所有的公式都转换为矩阵的形式,我们有两个变量,为了对这个公式进行矩阵化,我们可以给每一个点x增加一维,这一维的值固定为1,这一维将会乘到Θ0上。这样就方便我们统一矩阵化的计算,
然后我们将代价函数和梯度转化为矩阵向量相乘的形式:
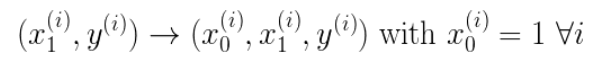
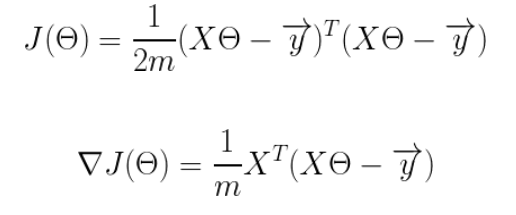
3·一元线性回归实列
from numpy import *
# 数据集大小 即20个数据点
m = 20
# x的坐标以及对应的矩阵
X0 = ones((m, 1)) # 生成一个m行1列的向量,也就是x0,全是1
X1 = arange(1, m+1).reshape(m, 1) # 生成一个m行1列的向量,也就是x1,从1到m
X = hstack((X0, X1)) # 按照列堆叠形成数组,其实就是样本数据
# 对应的y坐标
Y = array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# 学习率
alpha = 0.01
# 定义代价函数
def cost_function(theta, X, Y):
diff = dot(X, theta) - Y # dot() 数组需要像矩阵那样相乘,就需要用到dot()
return (1/(2*m)) * dot(diff.transpose(), diff)
# 定义代价函数对应的梯度函数
def gradient_function(theta, X, Y):
diff = dot(X, theta) - Y
return (1/m) * dot(X.transpose(), diff)
# 梯度下降迭代
def gradient_descent(X, Y, alpha):
theta = array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, Y)
while not all(abs(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, Y)
return theta
optimal = gradient_descent(X, Y, alpha)
print('optimal:', optimal)
print('cost function:', cost_function(optimal, X, Y)[0][0])
# 根据数据画出对应的图像
def plot(X, Y, theta):
import matplotlib.pyplot as plt
ax = plt.subplot(111) # 这是我改的
ax.scatter(X, Y, s=30, c="red", marker="s")
plt.xlabel("X")
plt.ylabel("Y")
x = arange(0, 21, 0.2) # x的范围
y = theta[0] + theta[1]*x
ax.plot(x, y)
plt.show()
plot(X1, Y, optimal)


所拟合出的直线:

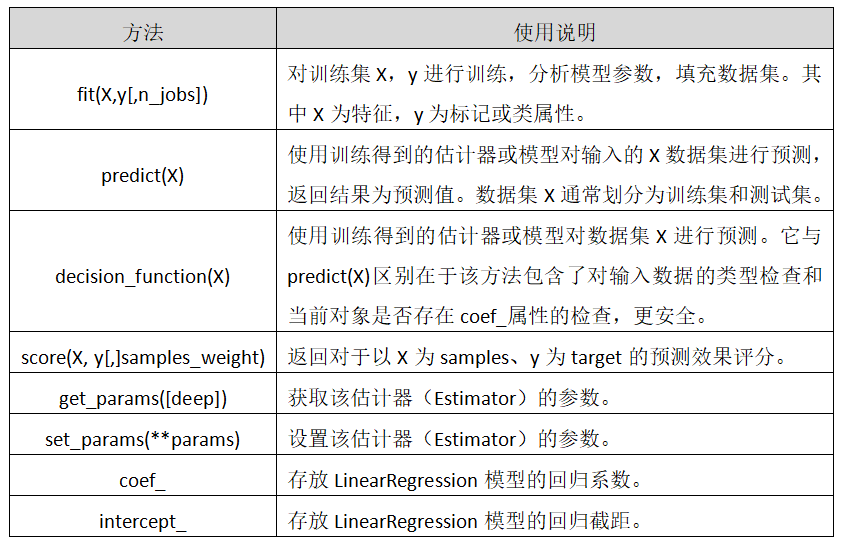
有关的回归模型库函数LinearRegression:
学习文章:
多种回归实例讲解:http://t.csdn.cn/6grAp