梯度下降法:
损失函数:
l o s s = ∑ i = 1 n 1 2 n [ y − ( k x + b ) ] 2 loss=\sum_{i=1}^{n}\frac{1}{2n}[y-(kx+b)]^2 loss=i=1∑n2n1[y−(kx+b)]2
对 k , b k,b k,b求梯度: k g r a d = ∂ l o s s ∂ k = − ∑ i = 1 n x n [ y − ( k x + b ) ] k_{grad}=\frac{\partial loss}{\partial k}=-\sum_{i=1}^{n}\frac{x}{n}[y-(kx+b)] kgrad=∂k∂loss=−i=1∑nnx[y−(kx+b)]
b g r a d = ∂ l o s s ∂ b = − ∑ i = 1 n 1 n [ y − ( k x + b ) ] b_{grad}=\frac{\partial loss}{\partial b}=-\sum_{i=1}^{n}\frac{1}{n}[y-(kx+b)] bgrad=∂b∂loss=−i=1∑nn1[y−(kx+b)]
梯度下降迭代公式:
k ′ = k − l r ∗ k g r a d k^\prime=k-lr*k_{grad} k′=k−lr∗kgrad
b ′ = b − l r ∗ b g r a d b^\prime=b-lr*b_{grad} b′=b−lr∗bgrad
其中 l r lr lr表示学习率。
import numpy as np
from matplotlib import pyplot as plt
data=np.genfromtxt("data.csv",delimiter=',')
x_data=data[:,0]
y_data=data[:,1]
plt.scatter(x_data,y_data)
plt.show()
lr=0.0001
b=0
k=0
epochs=100
def loss(x_data,y_data,k,b):#损失函数
n=len(x_data)
tot=0
for i in range(0,n):
tot+=(k*x_data[i]+b-y_data[i])**2
return tot/n/2
def grad_descent(x_data,y_data,k,b,lr,epochs):#梯度下降
n=len(x_data)
for i in range(epochs):
b_grad=0
k_grad=0
for j in range(n):
b_grad+=(1/n)*(k*x_data[j]+b-y_data[j])
k_grad+=(1/n)*x_data[j]*(k*x_data[j]+b-y_data[j])
b=b-lr*b_grad
k=k-lr*k_grad
if(i%10==0):
print("epochs={0}".format(i))
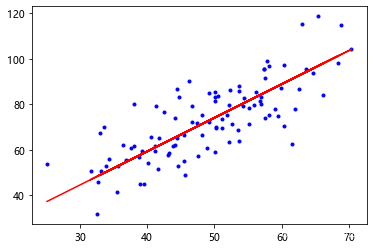
plt.plot(x_data,y_data,'b.')
plt.plot(x_data,k*x_data+b,'r')
plt.show()
return k,b
print("starting k={0},b={1},loss={2}".format(k,b,loss(x_data,y_data,k,b)))
print("running")
k,b=grad_descent(x_data,y_data,k,b,lr,epochs)
print("after {0} epochs k={1},b={2},loss={3}".format(epochs,k,b,loss(x_data,y_data,k,b)))
sklearn法:
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
data=np.genfromtxt("data.csv",delimiter=',')
x_data=data[:,0,np.newaxis]#sklearn 导入的数据需要是一个二维矩阵
y_data=data[:,1,np.newaxis]
plt.scatter(x_data,y_data)
plt.show()
model=LinearRegression()
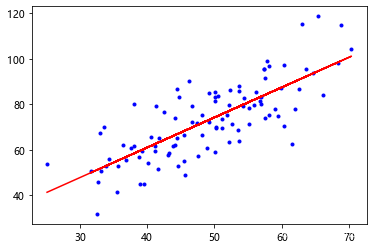
model.fit(x_data,y_data)#fit 用来建立回归直线
plt.plot(x_data,y_data,'b.')
plt.plot(x_data,model.predict(x_data),'r')# model.predict可以预测x对应的y
plt.show()