爬取动态页面(WebMagic、HtmlUnit)
上次提出了用 Selenium+浏览器驱动 去模拟浏览器的行为,然后去爬取动态页面(爬取动态页面(WebMagic、Selenium、ChromeDriver))。但是真的是太慢太慢了,而且 WebMagic 很多特性都用不了了,比如:多线程去处理请求、使用Pipeline去对结果集进行处理、请求去重…WebMagic最后被用成了HttpClient、Jsoup,失去了框架的意义。(也有可能是小编没合理地去模块化,但慢是真慢)
所以这里提出一个简单易用的工具——HtmlUnit,它可以模拟浏览器的行为,支持JavaScript解析和执行,可以用于解析动态页面。但它解析JavaScript的时候也是比较慢的,但后续用 WebMagic 去处理静态页面就快起来了。就比如说处理某网站的主页(动态页面)是需要解析JavaScript的,但主页里面的超链接对应的网页是静态网页,这时就可以直接用WebMagic去处理就可以了,速度就有了。
这里得说明一下 HtmlUnit 的缺点,方便后面讲解其使用:
- 不支持所有的动态页面:虽然 HTMLUnit 可以处理 JavaScript 和 AJAX,但是它并不支持所有的动态页面。一些高度复杂的动态页面可能会导致 HTMLUnit 无法正确解析页面。(比如:51job)
- 缺乏可视化界面:HTMLUnit 是一个 GUI-less浏览器,因此它缺乏可视化界面,这使得它不太适合用于测试和调试 Web 应用程序。(但咱这用的是去爬虫,所以问题应该不大)
- 对JavaScript的支持并不完美:HTMLUnit 的 JavaScript 引擎不如一些主流浏览器的 JavaScript 引擎强大,所以当用 HtmlUnit 去解析的时候,可能会出现一些JavaScript的问题。(这个根据调试结果,自己应该做相应的调整选择)
一、HtmlUnit的基本使用
引入依赖
需要 htmlunit 依赖和 commons-io 这个工具依赖。
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.70.0</version>
</dependency>
一般使用步骤
// 1. 创建 WebClient 对象,模拟浏览器行为
WebClient client = new WebClient();
// 2. 对 client 进行一些配置
// 比如设置不需要解析css时
client.getOptions().setCssEnabled(false);
// 3. 打开网页(通过getPage(url)方法),该过程进行了解析
HtmlPage htmlPage = client.getPage(url);
// 4. 因为小编一般用它就是解析动态页面的,所以一般都是会解析JavaScript的
// 所以这里最好设一个解析script时间,让它充分得以解析
client.waitForBackgroundJavaScript(10*1000);// 10s
// 5. 获取解析后的页面html源代码字符串
String htmlStr = htmlPage.asXml();
// 6. 再利用webmagic中的Html类去构造Html对象去处理数据
Html html = new Html(htmlStr);
// 7. 关闭WebClient
client.close();
WebClient 的一些配置(上述一般步骤中的第二步)
- 开启JavaScript解析(默认是开启的)
client.getOptions().setJavaScriptEnabled(true);
- 关闭CSS解析(默认是开启的)
client.getOptions().setCssEnabled(false);
- 禁止抛出JavaScript错误,防止程序终止(默认是开启的)
client.getOptions().setThrowExceptionOnScriptError(false);
- 等待JavaScript执行完成(这个设在getPage方法后,对面上面的第四步)
client.waitForBackgroundJavaScript(10*1000);// 10s
- 设置浏览器的 User-Agent,反反爬虫策略之一。让浏览器觉得你不是爬虫用户访问的。
client.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
二、案例(爬取CSDN首页)测试(WebMagic+HtmlUnit)
爬取CSDN首页,案例代码
@Component
public class TestProcessor implements PageProcessor {
@SneakyThrows
@Override
public void process(Page page) {
if(page.getUrl().toString().equals(url)) {
// 创建WebClient对象
WebClient client = new WebClient();
// 开启自动解析JavaScript
client.getOptions().setJavaScriptEnabled(true);
client.getOptions().setCssEnabled(false);
client.getOptions().setThrowExceptionOnScriptError(false);
// 打开网页,获取HtmlPage对象
HtmlPage htmlPage = client.getPage(page.getUrl().toString());
client.waitForBackgroundJavaScript(30000);
// 页面源代码
String s = htmlPage.asXml();
Html html = new Html(s);
// 获取当页职位url
List<String> allUrl = html.css("html body div#app div div.main div.page-container.page-component div div.home_wrap div#floor-blog-index_747 div.floor-blog-index div.blog-content div.Community div.active-blog div.Community-item-active.blog div.Community-item.blog div.content a.blog","href").all();
// 去获取数据、处理数据、保存数据
for (String jurl : allUrl) {
page.addTargetRequest(jurl);// 静态页面交给webmagic处理
}
client.close();
}else{
addSave(page);
}
}
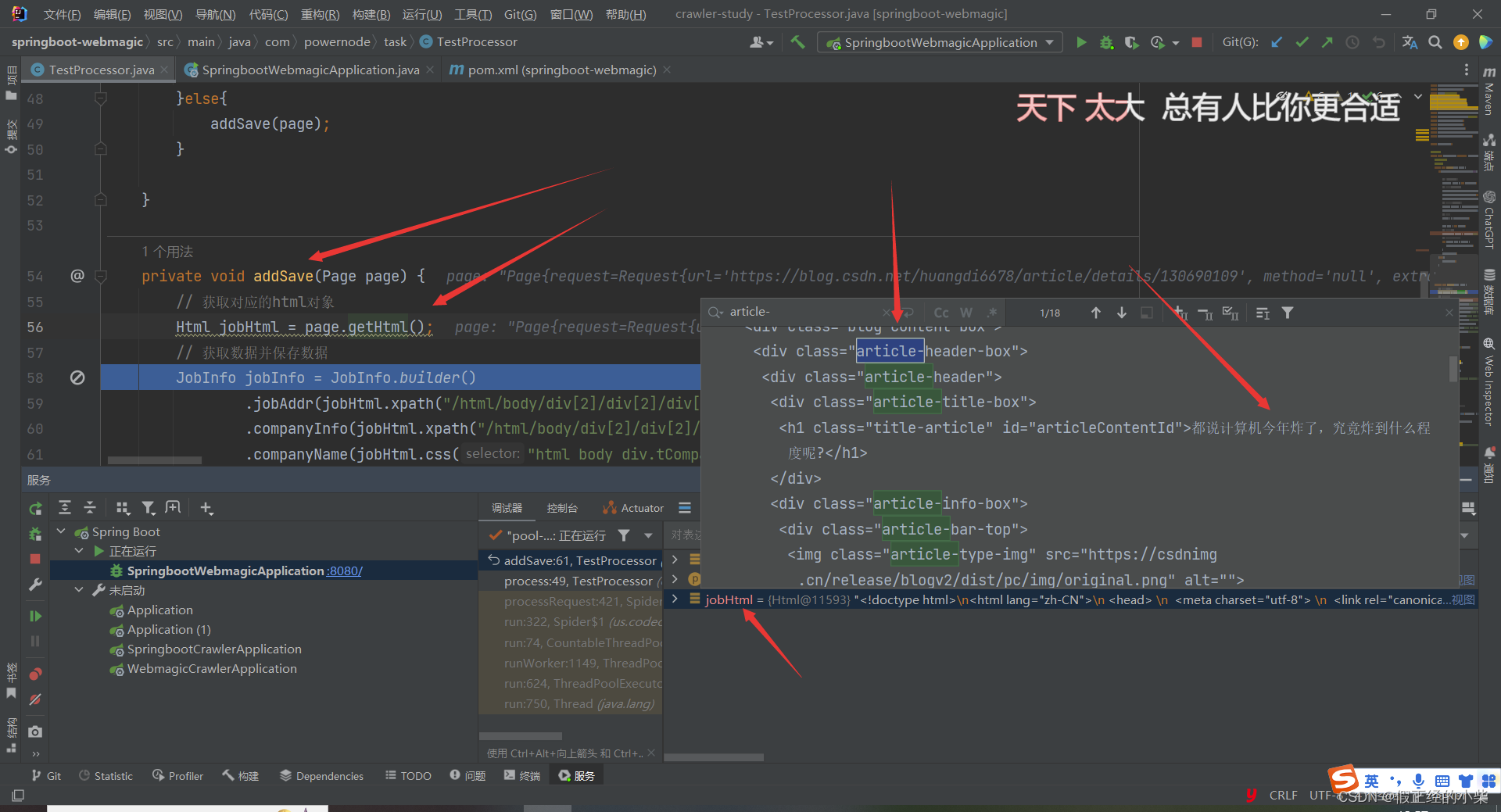
private void addSave(Page page) {
// 获取对应的html对象
Html jobHtml = page.getHtml();
// 获取数据并保存数据
// 存入数据库
}
private Site site = Site.me()
.setRetryTimes(3)
.setSleepTime(1000)
.setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
@Override
public Site getSite() {
return this.site;
}
// initialDelay 当任务启动后,等待多久执行方法
// fixedDelay 每隔多久执行这个方法
@Scheduled(initialDelay = 1000,fixedDelay = 100000)
public void process(){
Spider.create(new TestProcessor())
.addUrl(url)
.thread(5)
.run();
}
private String url = "https://blog.csdn.net/?spm=1001.2101.3001.4477";
}
测试效果
首页JavaScript被解析后的 CSDN HTML 代码

首页博客超链接对应的博客网页(它是静态网页),其 HTML 代码解析如下图所示
三、总结
使用 HtmlUnit 去解析动态页面然后去爬虫是比较方便的,这是由于 HtmlUnit 工具易用的原因。但由于它存在 JavaScript 支持并不完美,外加有些动态页面它也是解析不了的缺陷,使用 Selenium+浏览器驱动 这种方式也不能说就比 HtmlUnit 解析要差。
爬虫使用’工具’总结就是:
- 静态页面直接用 Webmagic;
- 动态页面如果可以用 HtmlUnit 就用 HtmlUnit;
- HtmlUnit 完成不了的再用 Selenium+浏览器驱动。
还有就是小编发现很多网站首页是动态页面的,但动态网页里超链接对应的页面一般是静态网页的。(小编没说绝对哈,一般是这样的)