(一)使用前的配置:
1,使用IDEA创建web项目:https://blog.csdn.net/MyArrow/article/details/50824793
2,(1)添加依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-selenium</artifactId>
<version>0.7.3</version>
</dependency>
(2)从GitHub官网下载webmagic的压缩包(https://codeload.github.com/code4craft/webmagic/zip/master),将webmagic-core使用Module from Existing Source..导入项目中
(3)在resources中添加资源文件log4j.properties中添加
# Set root logger level to DEBUG and its only appender to A1. log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
(二)写程序爬虫:
抽取元素:

1,page使用css选择器
2,page使用XPath


3,使用正则表达式
regex(“正则表达式”)
获取元素:

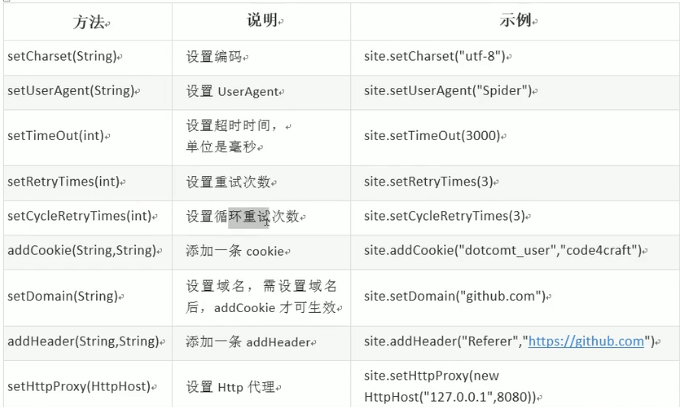
设置爬虫属性:site
Scheduler组件:
1,对抓取的url保存到队列

2,对抓取的url去重
