WebMagic框架介绍:
WebMagic框架是一个爬虫框架,其底层是HttpClient和Jsoup。WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。
WebMagic总体架构图如下
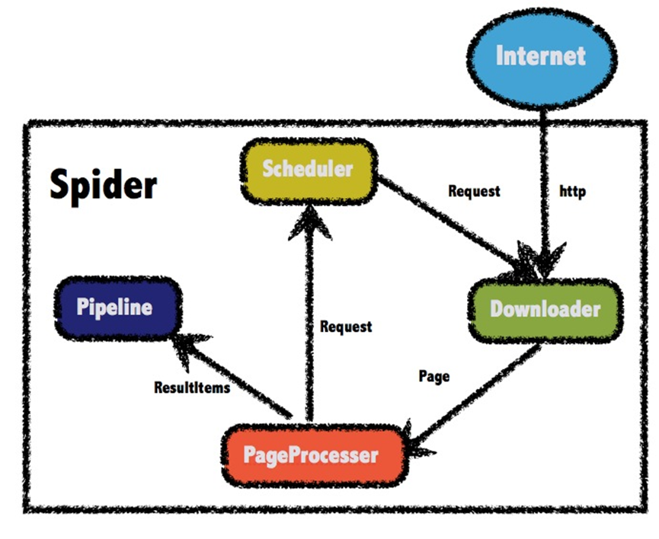
爬取京东数据各个组件的流程:
downloader
1.判断获取到的地址是下一页地址还是普通地址
2.若是下一页地址则获取附件,用无头浏览模式加载到该地址
3.再用Selenium操作浏览器点击下一页
4.用Selenium操作浏览器拉到最下方
5.吧渲染好的页面传给pageProcessor
6.若是普通地址,也要区分是第一页地址还是详情页面地址
7.若是详情页面则直接传给pageProcessor
8.若是第一页(有列表的页面则是第一页),用Selenium操作浏览器拉到最下方
9.传输渲染好的页面传给pageProcessor
pageProcessor
1.判断是列表页面还是详情页面
2.如果是列表页面就获取所有的地址传给队列
3.传给队列一个下一页地址:http://www.nextPage.com并添加附件,内容为这一页地址,方便downloader对象点击下一页按钮,
为了以放队列删除相同地址,添加一个 ?url=当前页地址
4.获取列表中每个商品的sku和sdu封装成实体类集合传给pipeline(因为详情页面不好找;通过详情页面的sku即可找到对应的spu)
5.如果是详情页面就封装成实体类传入pipeline
pipeline
1.如果获取到列表对象,就保存每个实体类到数据库
2.如果获取到实体类,就凭借实体类sku去数据库取出对应的一条数据
3.融合实体类,更新数据库
scheduler
源码:
导入依赖
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.2.RELEASE</version> </parent> <dependencies> <!--WebMagic核心包--> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <!--WebMagic扩展--> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> </dependency> <!--工具包--> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> </dependency> <!--SpringMVC--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--SpringData Jpa--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <!--单元测试--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <!--MySQL连接包--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>3.13.0</version> </dependency> </dependencies>
PageProcessor组件
package com.myjava.crawler.component; import com.myjava.crawler.entity.Item; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.impl.conn.PoolingHttpClientConnectionManager; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.springframework.stereotype.Component; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Request; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.processor.PageProcessor; import us.codecraft.webmagic.selector.Html; import us.codecraft.webmagic.selector.Selectable; import java.io.FileOutputStream; import java.io.IOException; import java.util.*; @Component public class JdPageProcessor implements PageProcessor { @Override public void process(Page page) { Html html = page.getHtml(); //1.判断是列表页面还是详情页面 List<Selectable> nodes = html.css("ul.gl-warp > li.gl-item").nodes(); if (nodes.size() > 0) { //2.如果是列表页面就获取所有的地址传给队列 List<String> hrefs = html.css("div.gl-i-wrap div.p-img a", "href").all(); page.addTargetRequests(hrefs); //4.获取列表中每个商品的sku和spu封装成实体类集合传给pipeline(因为详情页面不好找;通过详情页面的sku即可找到对应的spu) List<Item> itemList = new ArrayList<>(); Document document = html.getDocument(); Elements elements = document.select("ul.gl-warp.clearfix li.gl-item"); for (Element element : elements) { String sku = element.attr("data-sku"); String spu = element.attr("data-spu"); Item item = new Item(); item.setSku(Long.parseLong(sku)); item.setSpu(Long.parseLong(spu)); itemList.add(item); } page.putField("itemList",itemList); //3.传给队列一个下一页地址:http://www.nextPage.com并添加附件,内容为这一页地址, // 方便downloader对象点击下一页按钮,为了以放队列删除相同地址,添加一个 ?url=当前页地址 Request request = new Request("http://nextpage?url="+page.getUrl()); Map<String,Object> map = new HashMap<>(); map.put("currentPageUrl",page.getUrl().get()); request.setExtras(map); page.addTargetRequest(request); } else{ //5.如果是详情页面就封装成实体类传入pipeline //库存量单位(最小品类单元) Long sku = null; try { sku = Long.parseLong(html.css("div.preview-info div.left-btns a.follow.J-follow","data-id").get()); } catch (NumberFormatException e) { //System.out.println("---------------"+page.getUrl()+"-------------------"); e.printStackTrace(); } //商品标题 String title = html.css(".sku-name","text").get(); //商品价格 Double price = Double.parseDouble(html.css("div.dd span.p-price span.price","text").get()); //商品图片 String picture = parsePicture(page); //商品详情地址 String url = page.getUrl().get(); //创建时间 Date createDate = new Date(); //更新时间 Date updateDate = new Date(); Item item = new Item(); item.setSku(sku); item.setUpdated(updateDate); item.setCreated(createDate); item.setUrl(url); item.setTitle(title); item.setPrice(price); item.setPic(picture); page.putField("item",item); } } @Override public Site getSite() { return Site.me() //必须设置这个请求头,不然拿不到数据 .addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0"); } /** * 保存图片到本地并返回本地图片地址 * @param page * @return */ public String parsePicture(Page page){ String src = "http:"+page.getHtml().css("div#spec-n1.jqzoom.main-img img#spec-img", "src").get(); PoolingHttpClientConnectionManager hc = new PoolingHttpClientConnectionManager(); CloseableHttpClient client = HttpClients.custom() .setConnectionManager(hc) .build(); HttpGet get = new HttpGet(src); get.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0"); String fileName = UUID.randomUUID()+src.substring(src.lastIndexOf(".")); String path = "D:\\temp\\img\\"; String finalPath =path+fileName; try { CloseableHttpResponse response = client.execute(get); HttpEntity entity = response.getEntity(); entity.writeTo(new FileOutputStream(finalPath)); } catch (IOException e) { e.printStackTrace(); } return finalPath; } }
Downloader组件
package com.myjava.crawler.component; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.chrome.ChromeOptions; import org.openqa.selenium.remote.RemoteWebDriver; import org.springframework.stereotype.Component; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Request; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.downloader.Downloader; import us.codecraft.webmagic.selector.PlainText; import java.util.List; @Component public class JdDownloader implements Downloader { private RemoteWebDriver chromeDriver; public JdDownloader(){ //配置参数 System.setProperty("webdriver.chrome.driver", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe"); ChromeOptions chromeOptions = new ChromeOptions(); // 设置为 headless 模式 (必须) // chromeOptions.addArguments("--headless"); // 设置浏览器窗口打开大小 (非必须) chromeOptions.addArguments("--window-size=1024,768"); chromeDriver = new ChromeDriver(chromeOptions); } @Override public Page download(Request request, Task task) { //1.判断获取到的地址是下一页地址还是普通地址(http://nextpage?url=) if (request.getUrl().contains("nextpage")) { //2.若是下一页地址则获取附件,用无头浏览模式加载到该地址 String currentPageUrl = (String) request.getExtra("currentPageUrl"); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } chromeDriver.get(currentPageUrl); //3.再用Selenium操作浏览器点击下一页,并休眠3秒钟 chromeDriver.findElementByCssSelector("div#J_topPage.f-pager a.fp-next").click(); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } //4.用Selenium操作浏览器拉到最下方 chromeDriver.executeScript("window.scrollTo(0, document.body.scrollHeight - 300)"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } //取渲染之后的页面 String pageSource = chromeDriver.getPageSource(); //5.吧渲染好的页面传给pageProcessor return createPage(pageSource,chromeDriver.getCurrentUrl()); } else { //6.若是普通地址,也要区分是第一页地址还是详情页面地址 chromeDriver.get(request.getUrl()); List<WebElement> elements = chromeDriver.findElementsByCssSelector(".gl-item"); if (elements.size()>0) { //8.若是第一页(有列表的页面则是第一页),用Selenium操作浏览器拉到最下方 chromeDriver.executeScript("window.scrollTo(0, document.body.scrollHeight - 300)"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } //9.传输渲染好的页面传给pageProcessor return createPage(chromeDriver.getPageSource(),chromeDriver.getCurrentUrl()); }else { //7.若是详情页面则直接传给pageProcessor return createPage(chromeDriver.getPageSource(),chromeDriver.getCurrentUrl()); } } } public Page createPage(String pageSource,String url){ Page page = new Page(); //封装page对象 page.setRawText(pageSource); page.setUrl(new PlainText(url)); //设置request对象(必要) page.setRequest(new Request(url)); //设置页面抓取成功(必要) page.setDownloadSuccess(true); return page; } @Override public void setThread(int i) { } }
Pipeline组件
package com.myjava.crawler.component; import com.myjava.crawler.dao.ItemDao; import com.myjava.crawler.entity.Item; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; import java.util.List; @Component public class JdPipeline implements Pipeline { @Autowired private ItemDao itemDao; @Override public void process(ResultItems resultItems, Task task) { List<Item> itemList = resultItems.get("itemList"); //1.如果获取到列表对象,就保存每个实体类到数据库 if (itemList!=null){ for (Item item : itemList) { itemDao.save(item); } } Item item = resultItems.get("item"); if(item!=null) { //2.如果获取到实体类,就凭借实体类sku去数据库取出对应的一条数据 Item itemSku = itemDao.findBySku(item.getSku()); //3.融合实体类,更新数据库 itemSku.setPic(item.getPic()); itemSku.setPrice(item.getPrice()); itemSku.setTitle(item.getTitle()); itemSku.setUrl(item.getUrl()); itemSku.setCreated(item.getCreated()); itemSku.setUpdated(item.getUpdated()); itemDao.save(itemSku); } } }
Spider开启爬虫
package com.myjava.crawler.component; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import us.codecraft.webmagic.Spider; @Component public class JdSpider { @Autowired private JdPageProcessor pageProcessor; @Autowired private JdDownloader downloader; @Autowired private JdPipeline pipeline; public void start(){ Spider.create(pageProcessor) .setDownloader(downloader) .addPipeline(pipeline) .addUrl("https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&pvid=f50e5a02031849e4a9f8adbb9928b7ac") .start(); } }
爬取数据过程中的问题及解决方法:
问题:
在爬取过程中,明明css选择器没写错却取不到数据
结局方法:
在请求头中加入 User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0 即可解决