1、二元分类
要尝试分类,一种方法是使用线性回归,并将所有大于0.5的预测值映射为1,将小于0.5的所有预测值映射为0
二元分类问题,其中y只能取两个值0和1
Sigmoid Function(逻辑回归函数)
因为只能取两个值0和1
hθ(x)=P(y=1|x;θ)=1−P(y=0|x;θ)P(y=0|x;θ)+P(y=1|x;θ)=1
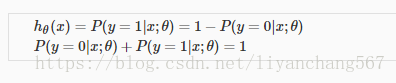
决策边界
当

等价于

g(z) (e.g. \theta^T XθTX) 就是逻辑回归的决策边界
简化的逻辑回归的代价函数
代价函数如下:

因为y等于1或0;
代价函数也可以表示成

完整形式如下:

通过向量和矩阵表达:
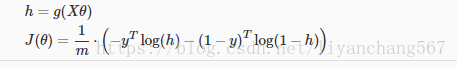
简化的逻辑回归梯度下降
梯度下降的一般表达式
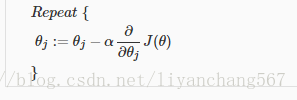
微积分计算得到

向量输出
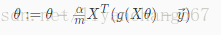
2、更高级的代价函数算法
梯度下降法并不是唯一的算法,共轭梯度法、BFGS (变尺度法) 和 L-BFGS (限制变尺度法)更加高级优化算法来优化代价函数,能够更快的使代价函数收敛,更适合大型的机器学习(有很多的特征变量)
这三种算法的特点:

举例

需要编写函数

3、一对多分类
多元分类问题可以转化为多个二元分类问题
如下图

一个样本最终的预测分类为在所有分类器中概率最大的类别
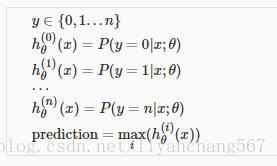
4、正则化解决过度拟合问题
hθ(x)=P(y=1|x;θ)=1−P(y=0|x;θ)P(y=0|x;θ)+P(y=1|x;θ)=1
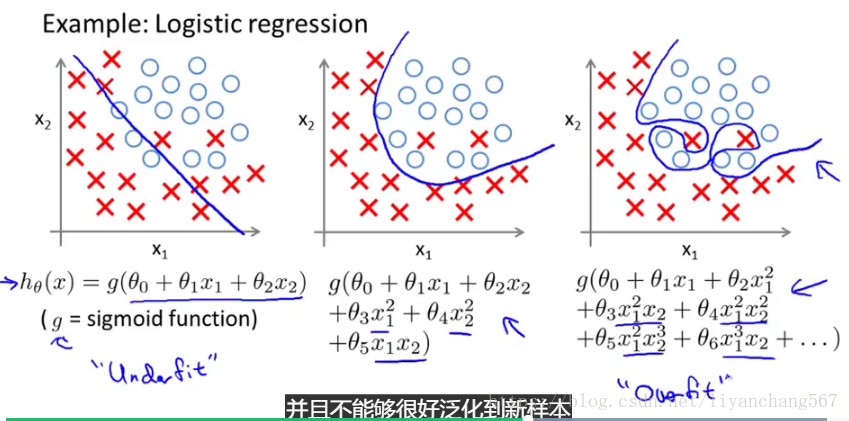
欠拟合或高偏倚是当我们的假设函数h的形式很难与数据的趋势作图时。 它通常是由一个特征太简单或功能太少造成的
过度拟合或高度方差是由适合现有数据的假设函数引起的,但不能很好地预测新数据。 它通常是由一个复杂的函数造成的,它会产生大量与数据无关的不必要的曲线和角度
举例如下图
解决过度拟合
1.减少特征的数量。 - 手动选择要保留的功能。 - 模型选择算法
2.规范化。 - 保留所有功能,但减少参数的大小/值。 - 当我们有很多功能时很有效,每个功能都有助于预测
正则化
在正则线性回归中,我们选择最小化θ,代价函数如下:
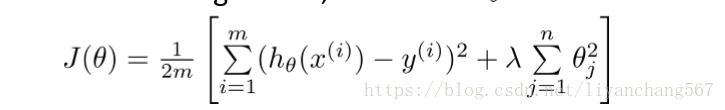
其中正则项是:
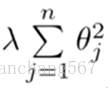
λ 要做的就是控制在两个不同的目标中的平衡关系
第一个目标就是我们想要训练,使假设更好地拟合训练数据。我们希望假设能够很好的适应训练集。
第二个目标是我们想要保持参数值较小。(通过正则化项)
λ过大,这种假设有过于强烈的"偏见" 或者过高的偏差 (bais),θ1到θn都接近于0,对于数据来说这只是一条水平线
λ过小,对于目标函数约束不足,正则项的接近于0,正则项接近于0,没有达到避免过拟合的约束目的
在正则化线性回归中的应用
梯度下降法
针对变量进行正则化,所以θ0不没有进行正规化

正则化式子转化成如下形式,1-α*λ/m值区间位于(0,1),每次迭代更新θj就一定程度上减小

正规化方程
正规化方程计算方程如下:

如果x'x不存在,x'x+λL就变成可逆的矩阵
正则化在逻辑回归中的应用
未进行正规化的方程的代价函数是:

通过正则项即可实现正则化
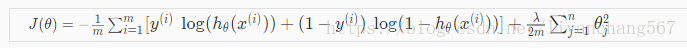
使用梯度下降法计算正则化之后的θ计算如下:

需要定义方程如下:
