01
引言
近年来,深度学习在NLP领域取得了显著进展。由于时间序列本质上也是呈现出序列性,如果将预训练的转换器(transformers)模型应用在时间序列预测上,结果将会如何呢?
不少学术论文(如参考文献[2]和[3])对深度学习模型进行了深度探讨,但并没有展示出完整的情况。有趣的是,即使在NLP的案例中,一些人更倾向于将GPT模型的重大突破归功于“更多的数据和计算能力”,而非“更优秀的机器学习研究”。
本文旨在消除可能存在的混淆,提供一个中立无偏的视角,并借助来自学术界和工业界的可信赖数据和资源进行阐述。具体来说,本文将讨论以下主题:
深度学习和统计模型的优点和缺点。
何时使用统计模型,何时使用深度学习。
如何处理一个预测案例。
如何通过为你的案例和数据集选择最佳模型来节省时间和金钱。
02
深度学习与统计学预测
Makridakis等人的论文
在讨论各种预测模型的发展过程时,Makridakis竞赛(又名M竞赛)提供了宝贵的见解。M竞赛是一系列的大型挑战赛,旨在呈现时间序列预测的最新进展。近期,Makridakis等人发表了一篇新论文,总结了前五届M竞赛的预测状况,同时提供了统计、机器学习和深度学习预测模型的广泛基准数据。然而,我们将在文章的后部分讨论这篇论文的一些局限性。
基准设置
传统上,Makridakis及其同事会在每次M竞赛结束后发表一篇总结论文。然而,这是他们首次在实验中纳入深度学习模型。为什么会这样?与自然语言处理(NLP)不同,深度学习(DL)预测模型在2018-2019年间才成熟到可以挑战传统预测模型。实际上,在2018年的M4竞赛中,机器学习/深度学习模型的排名垫底。
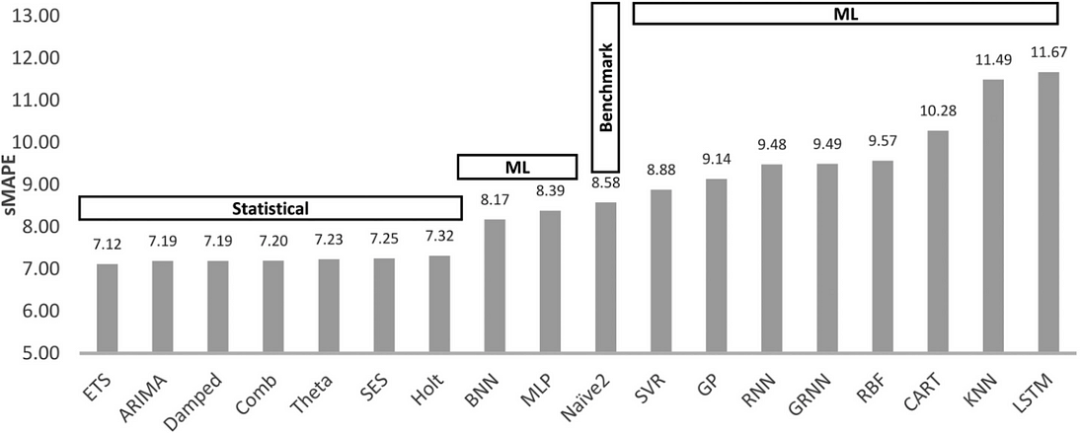
现在,让我们看看新论文中使用的DL/ML模型:
多层感知器(Multi-layer Perceptron (MLP)):我们熟悉的前馈网络。
波浪网(WaveNet): 一个结合卷积层的自回归神经网络(2016)。
转换模型(Transformer): 最初的Transformer,于2017年推出。
DeepAR:亚马逊第一个成功的自动回归网络,结合了LSTM(2017)。
注意:深度学习模型现在已经不再是最先进的(State-of-the-Art,SOTA)技术(稍后将详细讨论)。另外,多层感知机(MLP)被视为机器学习模型,而非“深度”模型。
基准测试中的统计模型包括ARIMA和ETS(指数平滑)——这两种模型都是广为人知且经过严格验证的模型。
此外,
ML/DL模型首先通过超参数调整进行了微调。统计模型则以逐个时间序列的方式进行训练。相反,DL模型是全局模型(在数据集的所有时间序列上进行训练)。因此,它们能够利用交叉学习的优势。
作者采用了集成方法:从深度学习模型中创建了一个Ensemble-DL模型,而从统计模型中创建了一个Ensemble-S模型。集成方法采用了预测结果的中位数。
Ensemble-DL由200个模型组成,每个类别(DeepAR、Transformer、WaveNet和MLP)有50个模型。
该研究使用了M3数据集:首先,作者对1,045个时间序列进行了测试,然后对整个数据集(3,003个时间序列)进行了测试。
作者使用了MASE(均方绝对缩放误差)和SMAPE(平均绝对百分比误差)等指标来衡量预测的准确性。这些误差度量标准在预测中常被使用。
接下来,我们提供了一个从基准得到的结果和结论的总结。
1. 深度学习模型更好
作者的结论是,平均而言,DL模型的表现优于统计模型。结果显示在图2中:
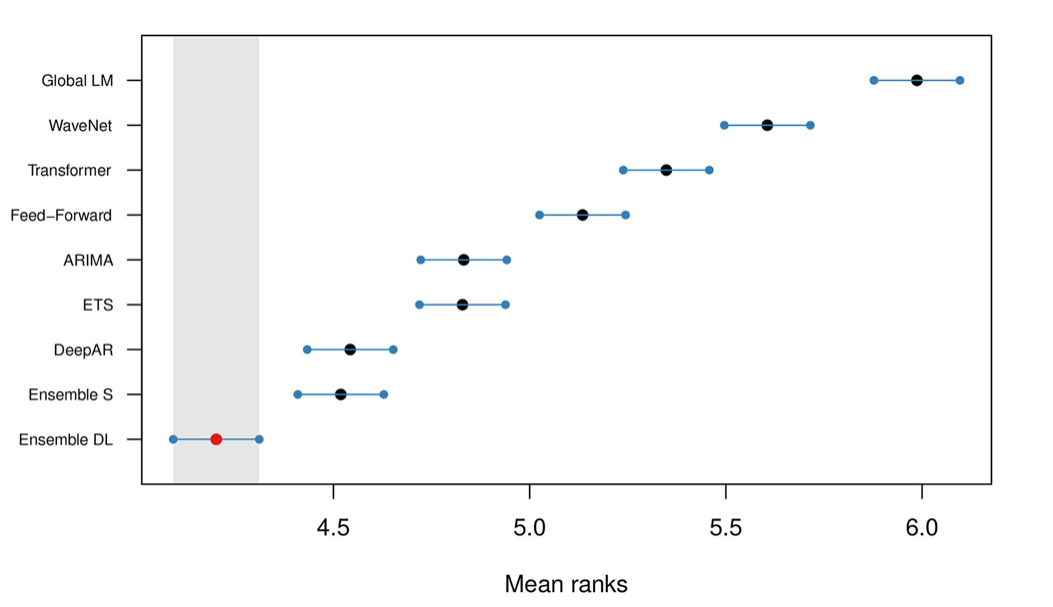
图2:所有模型的平均排名和95%置信区间,使用sMAPE进行排名
Ensemble-DL模型的表现明显优于Ensemble-S。另外,DeepAR也取得了与Ensemble-S非常相似的结果。有趣的是,图2显示,尽管Ensemble-DL胜过Ensemble-S,但只有DeepAR胜过单个统计模型。这是为什么呢?我们将在文章的后面回答这个问题。
2. 但是,深度学习模型是昂贵的
深度学习模型需要大量的时间来训练(和金钱)。这是意料之中的事。结果显示在图3中:
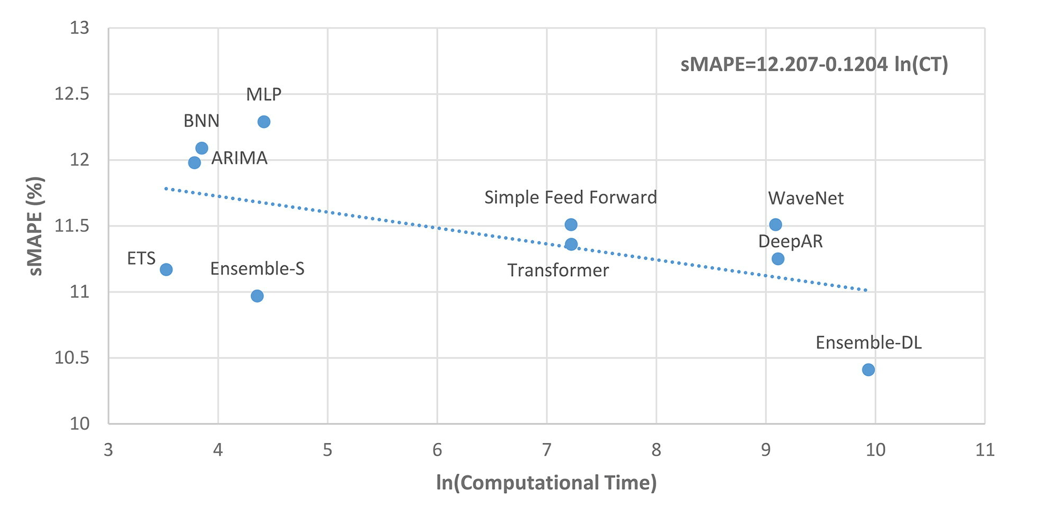
图3:SMAPE与计算时间
ln(CT)为零对应的计算时间约为1分钟,而ln(CT)为2、4、6、8和10分别对应约7分钟、1小时、7小时、2天和15天
计算上的差异是很大的。因此,降低10%的预测误差需要大约15天的额外计算时间(Ensemble-DL)。虽然这个数字看起来很大,但有一些事情需要考虑:
作者没有说明他们使用的是什么类型的硬件。
他们也没有提到是否使用了任何并行化或训练优化。
如果在集合中使用较少的模型,Ensemble-DL的计算时间可以大大减少。这显示在图4中:
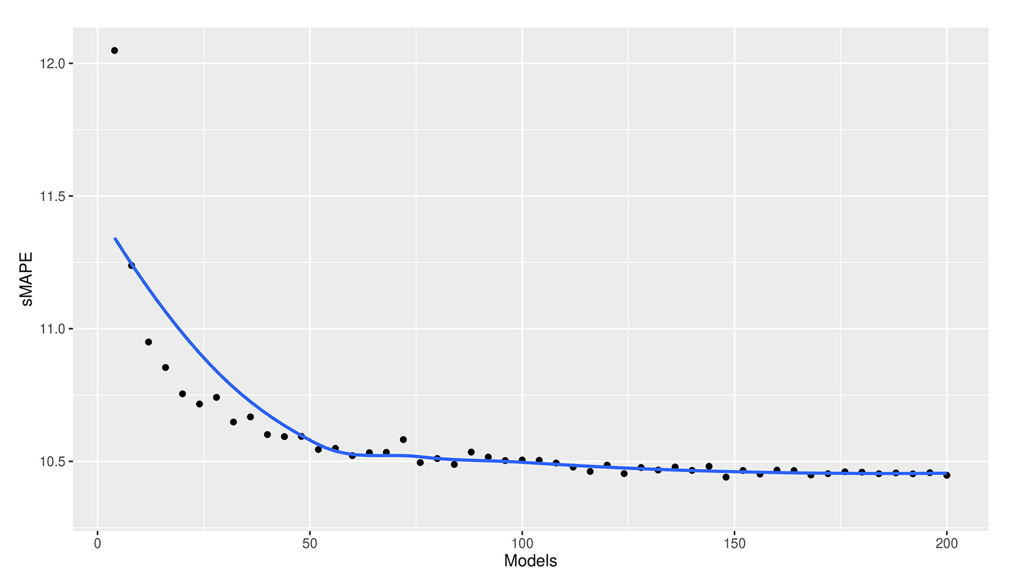
我之前提到,Ensemble-DL模型是200个DL模型的集合体。图4显示,75个模型可以达到与200个模型相当的精度,而计算成本只有三分之一。如果使用更巧妙的方法来做合集,这个数字还可以进一步减少。最后,本文没有探讨深度学习模型的转移学习能力。我们以后也会讨论这个问题。
3. 集成模型是你所需的一切
集成模型的强大是无可争议的(见图2,图3)。无论是深度学习的集成模型(Ensemble-DL)还是统计学习的集成模型(Ensemble-SL),都是表现最佳的模型。这种思想的基础是每个单独的模型都擅长捕捉不同的时间动态。将它们的预测结果结合起来能够识别复杂的模式并进行准确的推断。
4. 短期预测 vs 长期预测
作者们研究了模型在短期预测与长期预测能力上是否存在差异。结果显示的确存在差异。图5详细展示了每个模型在每个预测视野上的准确度。例如,第1列显示了一步预测的误差。类似地,第18列显示了第18步预测的误差。
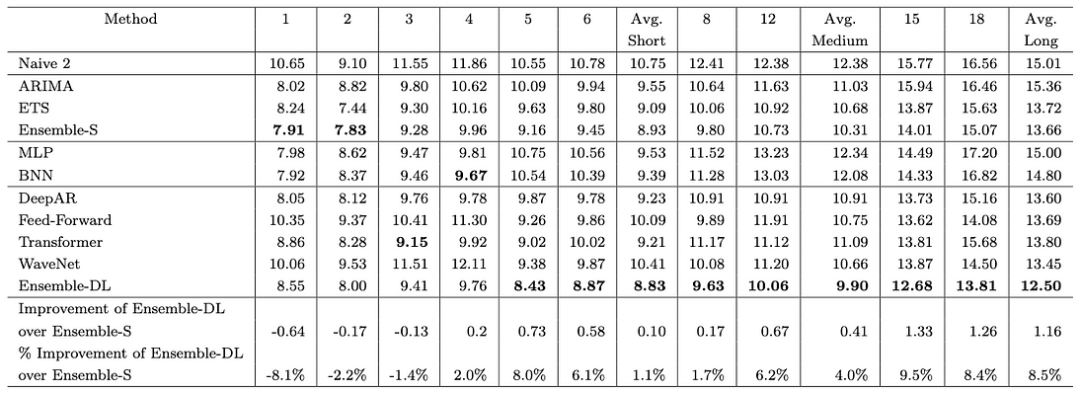
图5:1045系列的每个模型的sMAPE误差--越低越好
这里有3个关键的观察:
首先,长期预测不如短期预测准确(这并不奇怪)。在前4个水平线上,统计模型获胜。除此之外,深度学习模型开始变得更好,Ensemble-DL获胜。具体来说,在第一个水平线上,Ensemble-S的准确度要高8.1%。然而,在最后一个水平线上,Ensemble-DL的准确度要高8.5%。
如果你想一想,这是有道理的:
统计模型是自动回归的。随着预测范围的增加,误差会不断累积。
相反,深度学习模型是多输出模型。因此,他们的预测误差分布在整个预测序列中。
唯一的DL自回归模型是DeepAR。这就是为什么DeepAR在第一个水平线上表现得非常好,与其他DL模型相反。
5. 深度学习模型是否随着更多的数据而改进?
在之前的实验中,作者只使用了M3数据集中的1045个时间序列。接下来,作者使用完整的数据集(3,003个序列)重新进行了实验。他们还分析了每个水平线的预测损失。结果显示在图6中:
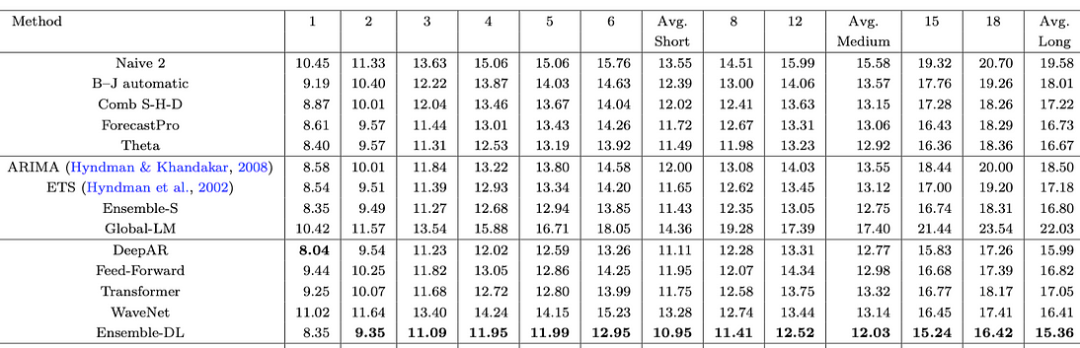
图6:3003系列每个模型的sMAPE误差
现在,Ensemble-DL和Ensemble-S之间的差距缩小了。在第一个水平线上,统计模型与深度学习模型相匹配,但在那之后,Ensemble-DL的表现超过了它们。
让我们进一步分析Ensemble-DL和Ensemble-S之间的差异:

图7:Ensemble-DL对Ensemble-S的改进百分比
随着预测步骤的增加,深度学习模型的表现超越了统计集成模型。
6. 关于趋势和季节性分析
最后,作者们研究了统计模型和深度学习模型如何处理时间序列的重要特性,比如趋势和季节性。为了实现这一点,作者们采用了[5]的方法。具体来说,他们拟合了一个多元线性回归模型,该模型将sMAPE误差与五个关键的时间序列特性关联起来:可预测性(错误的随机性)、趋势、季节性、线性、稳定性(决定数据正态性的最佳Box-Cox参数转换)。结果如图8所示:
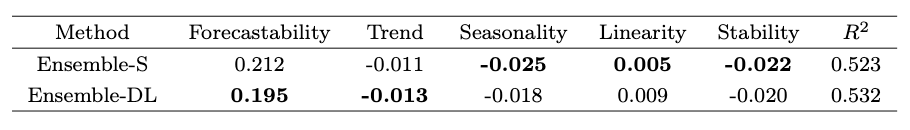
图8:不同指标的线性回归系数。数值越低越好
我们可以观察到:
深度学习模型在处理噪声大、有趋势以及非线性数据方面表现更佳。
对于具有线性关系的季节性和低方差数据,统计模型更为合适。
这些洞察无比宝贵。因此,在为你的应用案例选择合适的模型之前,进行深入的探索性数据分析(EDA)并理解数据的本质是至关重要的。
研究的局限性
这篇论文无疑是当前关于时间序列预测领域现状的最佳研究之一,但它也存在一些局限性。让我们来看一看:
(1)缺少ML算法:树 / 提升树
提升树模型在时间序列预测问题中占有重要地位。最流行的模型包括XGBoost、LightGBM和CatBoost。此外,LightGBM赢得了M5竞赛。这些模型在表格型数据上表现出色。事实上,到目前为止,提升树仍然是处理表格数据的最佳选择。然而,本研究中使用的M3数据集简单,因为它主要包含单变量序列。在未来的研究中,将提升树添加到数据集中,特别是对于更复杂的数据集,将是一个好主意。
(2)选择M3作为基准数据集国际预测期刊(IJF)的主编Rob Hyndman教授曾说过:“自2000年以来,M3数据集一直被用于测试预测方法;新提出的方法必须超越M3才能在IJF上发表。”然而,按照现代标准,M3数据集被认为是小而简单的,因此并不能代表现代预测应用和实际场景。当然,数据集的选择并不减少这项研究的价值。然而,使用一个更大的数据集进行未来的基准测试可能会提供有价值的洞察。
(3)深度学习模型并非最先进的现在,是时候面对问题的核心了。这项研究中的深度学习模型远未达到最先进的水平。研究确定了亚马逊的DeepAR作为理论预测准确性最好的DL模型。因此,DeepAR是唯一一种能够在个体层面超越统计模型的模型。然而,DeepAR模型现在已经有6年多的历史了。自那时以来,亚马逊发布了其改进版的DeepAR,名为Deep GPVAR。事实上,Deep GPVAR也已经过时——亚马逊最新的深度预测模型是在2020年发布的MQTransformer。
此外,其他强大的模型,如Temporal Fusion Transformer(TFT)和N-BEATS(最近被N-HITS超越)也没有用在深度学习集成中。因此,研究中使用的深度学习模型至少落后于当前最先进技术的两代。毫无疑问,当前一代的深度预测模型会有更好的结果。
预测并非一切准确性在预测中至关重要,但它并不是唯一重要的因素。其他关键领域
包括:
不确定性量化
预测可解释性
零样本学习 / 元学习
区制转换的划分
说到零样本学习,它是人工智能领域最具前景的领域之一。零样本学习是指模型在没有特定针对它们进行训练的情况下,能够正确估计未见过的数据。这种学习方法更好地反映了人类的感知。所有的深度学习模型,包括GPT模型,都基于这个原则。
首个广受好评的利用这一原则的预测模型是N-BEATS / N-HITS。这些模型可以在大规模的时间序列数据集上进行训练,并在完全新的数据上产生预测,其准确性与模型显式在这些数据上训练的准确性相似。
零样本学习只是元学习的一个特定实例。自那时以来,时间序列上的元学习已经取得了进一步的进展。以M6竞赛为例,其目标是寻找是否可以利用数据科学预测和计量经济学打败市场,就像传奇投资者那样做(例如,沃伦·巴菲特)。获胜的解决方案是一个新的架构,其中使用了神经网络和元学习。
不幸的是,这项研究并未探索深度学习模型在零样本学习设置中的竞争优势。
Nixtla 的研究
在时间序列预测领域中,备受瞩目的初创公司Nixtla最近发布了一份关于Makridakis等人论文[4]的基准测试后续报告。具体来说,Nixtla团队增加了两种额外的模型:复杂指数平滑和动态优化Theta。
这些模型的添加缩小了统计模型和深度学习模型之间的差距。此外,Nixtla团队正确地指出了两类模型所需的成本和资源之间的显著差异。事实上,许多数据科学家被深度学习过度夸大的承诺所误导,缺乏正确解决预测问题的方法。我们将在下一节进一步讨论这个问题。但在此之前,我们需要解决深度学习所面临的批评。
深度学习受到质疑
过去十年里,深度学习的进步令人惊叹,而且迄今为止还没有放缓的迹象。然而,每一个有威胁改变现状的革命性突破,往往都会遭到怀疑和批评。以GPT-4为例:这项新的发展在未来十年内威胁到了美国20%的就业岗位[6]。深度学习和变换器在NLP领域的主导地位是不可否认的。
然而,在面试中,人们会问到这样的问题:NLP的进步是归因于更好的研究,还是仅仅归因于更多的数据和增加的计算能力?在时间序列预测领域,情况更糟。要理解背后的原因,你首先必须理解传统的解决预测问题的方法。
在ML/DL广泛采用之前,预测全靠为你的数据集制定正确的转换。这包括使时间序列稳定,移除趋势和季节性,考虑到波动性,使用诸如box-cox转换等技术。所有这些方法都需要人工干预和深入理解数学和时间序列。
随着ML的出现,时间序列算法变得更自动化。你可以轻松地将它们应用到时间序列问题上,几乎不需要进行预处理,只需要清理数据(尽管额外的预处理和特征工程总是有帮助)。如今,这种项目的改进努力主要限于超参数调整。
因此,那些使用高级数学和统计的人无法理解ML/DL算法如何超越传统的统计模型。有趣的是,研究人员甚至不清楚一些DL概念为何有效。
时间序列预测最新文献
据我所知,当前的文献缺乏足够的证据来阐述各种类别的预测模型的优点和缺点。以下两篇论文最为相关:
(1)Are Transformers Effective for Time Series Forecasting?(变换器对于时间序列预测有效吗?)[2],展示了一些预测转换模型(Transformers)的弱点。该论文解释了现代转换模型中使用的位置编码方案如何无法捕获时间序列的时态动态,因为自我注意力是排列不变的。然而,该论文没有提到那些已经有效解决了这个问题的转换模型。例如,Google的Temporal Fusion Transformer (TFT)使用一个编码器-解码器LSTM层来创建时间感知和上下文感知的嵌入。同时,TFT使用了一个适应于时间序列问题的新颖注意力机制,来捕获时态动态并提供可解释性。同样,Amazon的MQTransformer使用其新颖的位置编码方案(上下文依赖的季节性编码)和注意力机制(反馈感知的注意力)。
(2)Do We Really Need DL Models for Time Series Forecasting?(我们真的需要DL模型进行时间序列预测吗?)[3],这篇论文也很有趣,比较了统计、提升树、ML和DL类别中各种预测方法。遗憾的是,这篇文章并没有达到其标题所说的,因为在12个模型中最好的模型是Google的TFT,这是一个纯粹的深度学习模型。论文提到:
...上面表5的结果强调了滚动预测配置的GBRT的竞争力,但也表明,像TFT[12]这样更强大的基于变换器的模型,完全有理由超越提升回归树的表现..
总的来说,在阅读复杂的预测论文和模型时,要特别注意,特别是关于出版源的问题。国际预测杂志(IJF)就是一个专注于预测的知名期刊。
如何处理预测问题
这并不简单。每个数据集都是独一无二的,每个项目的目标各不相同,这使得预测具有挑战性。然而,这篇文章提供了一些一般性的建议,对大多数方法可能都有益。如你所见,深度学习模型正在预测项目中逐渐流行,但它们仍处于早期阶段。尽管它们具有潜力,但也可能成为一个陷阱。
不建议你马上将深度学习模型作为你项目的优先选择。根据Makridakis等人和Nixtla的研究,最好从统计模型开始。3-4个统计模型的集成可能比你预期的更强大。此外,如果你有表格数据,尝试使用提升树也是个好主意。对于小型数据集(数量级在千位数),这些方法可能已经足够。
深度学习模型可能提供额外的3-10%的准确度提升。然而,训练这些模型可能需要耗费大量时间和成本。对于某些领域,如金融和零售,这种额外的准确度提升可能更有利,且可以证明使用深度学习模型的价值。一个更准确的产品销售预测或者一个ETF的收盘价可能转化为数千美元的增量收入。
另一方面,像N-BEATS和N-HITS这样的深度学习模型具有转移学习的能力。如果构建了足够大的时间序列数据集,而且有意愿预训练这两个模型并分享他们的参数,我们可以直接使用这些模型并达到顶级的预测准确度(或者首先对我们的数据集进行小幅度的微调)。
03
结语
时间序列预测是数据科学的一个关键领域。但相比其他领域,它的价值被低估了。Makridakis等人的论文[4]为未来提供了一些有价值的见解,但仍有大量的工作和研究需要完成。此外,预测中的深度学习模型大部分还未被探索。例如,深度学习的多模态架构无处不在。这些架构利用多个领域的知识来学习特定任务。例如,CLIP(被DALLE-2和Stable Diffusion使用)结合了自然语言处理和计算机视觉。基准M3数据集只包含3003个时间序列,每个序列的观测值不超过500个。相比之下,成功的Deep GPVAR预测模型平均包含44K个参数。相比之下,Facebook的LLaMA语言Transformer模型最小版本有70亿个参数,训练过程使用了1万亿个token。所以,对于原始问题,关于哪个模型最好并没有明确的答案,因为每个模型都有其自身的优点和不足。相反,这篇文章旨在提供所有必要的信息,帮助你为你的项目或案例选择最适合的模型。
本文由cutehand翻译整理,英文原文:Time-Series Forecasting: Deep Learning vs Statistics — Who Wins?
https://towardsdatascience.com/time-series-forecasting-deep-learning-vs-statistics-who-wins-c568389d02df
参考文献:
[1] Created from Stable Diffusion with the text prompt “a blue cyan time-series abstract, shiny, digital painting, concept art”
[2] Ailing Zeng et al. Are Transformers Effective for Time Series Forecasting? (August 2022)
[3] Shereen Elsayed et al. Do We Really Need Deep Learning Models for Time Series Forecasting? (October 2021)
[4] Makridakis et al. Statistical, machine learning and deep learning forecasting methods: Comparisons and ways forward (August 2022)
[5] Kang et al. Visualising forecasting algorithm performance using time series instance spaces (International Journal of Forecasting, 2017)
[6] Eloundou et al. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (March 2023)
文章中使用的所有图片都来自[4]。The M3 dataset as well as all M-datasets “are free to use without further permission by the IIF”.

关于Python金融量化

专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取qstock源代码、30多g的量化投资视频资料、量化金融相关PDF资料、公众号文章Python完整源码、与博主直接交流、答疑解惑等。添加个人微信sky2blue2可获取八五折优惠。
