目录
目录
1. 什么是正则表达式
正则表达式是通过一些特殊字符的排列,用以查找、替换、删除一行或多行文字字符串,简单的说,正则表达式就是用在字符串的处理上面的一项表示式。由于正则表达式语法简练,功能强大,得到了许多程序设计语言的支持,包括Java、C++、Perl以及Shell等。
2. 如何正确使用正则表达式
当一个正则表达式完成之后,并能够保证这个表达式一定是准确的,需要不断地测试才可以确定其正确与否。在不同的环境下,用户需要不同的工具来帮助他完成测试的过程。如果是在Shell命令 中,用户可以使用grep
命令来测试。
grep家族有三大成员分别为:
grep
:支持使用基本正则表达式。
egrep
:支持使用扩展正则表达式。
fgrep
:不支持使用正则表达式,即所有的正则表达式中的元字符都将作为一般字符,仅仅拥有其字面 意义,不再拥有特殊意义。
grep命令的名称来自于全局搜索正则表达式并打印文本行(
Global Search Regular Expression and Print out the line)的缩写。它是一个非常古老的
UNIX
命令,也是一种强大的文本搜索工具。
grep
命令 使用正则表达式来搜索文本,并且把匹配的文本行打印出来。
grep命令根据用户指定的
”pattern
(过滤条件)
“
对目标文本逐行进行匹配检查;打印出符合条件的
行,即文本搜索工具。注:
PATTERN
即过滤条件指由文本字符及正则表达式元字符所编写的字符串。
grep命令的基本语法如下:
grep [options] pattern [file…]
在上面的语法中,options
表示选项,选项列表如下表。
pattern
表示要匹配的模式,
file
表示一系列的文件名。grep
命令会从一个或者多个文件中搜索满足指定模式的文本行,并且打印出来。模式后面的所有的字符串参数都被看作是文件名。
-n
: 显示行号
-o
: 只显示匹配的内容
-q
: 静默模式,没有任何输出,得用
$?
来判断执行成功没有,即有没有过滤到想要的内容
-l
: 如果匹配成功,则只将文件名打印出来,失败则不打印,通常-rl
一起用,
grep
-rl
'root'
/etc
-A
: 如果匹配成功,则将匹配行及其后
n
行一起打印出来
-B
: 如果匹配成功,则将匹配行及其前
n
行一起打印出来
-C
: 如果匹配成功,则将匹配行及其前后
n
行一起打印出来
--color
: 高亮颜色显示匹配到的字符串
-c
: 如果匹配成功,则将匹配到的行数打印出来
-E
: 等于
egrep
,扩展
-i
: 忽略大小写
-v
: 取反,不匹配
-w
: 匹配单词
-r
: 递归搜索,不仅搜索当前目录,还要搜索其各级子目录
-s
: 不显示关于不存在或者无法读取文件的错误信息
3. 基本正则表达式
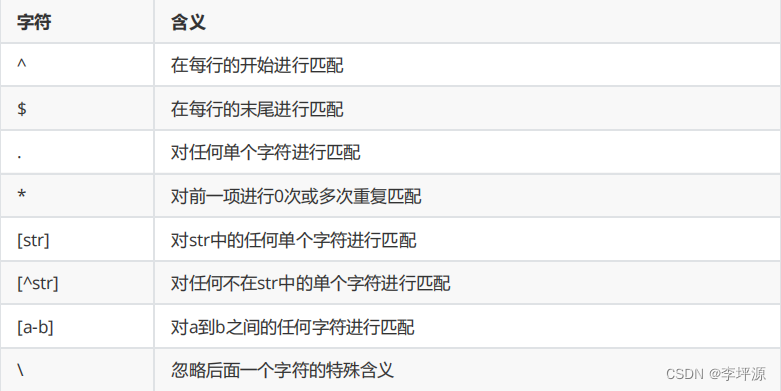
比如:
1)^word 表示搜索以word开头的内容。
2)word$ 表示搜索以word结尾的内容。
3)^$ 表示空行,不是空格。
4). 代表且只能代表一个任意字符。
5)\ 转义字符,让有着特殊身份意义的字符失效。
6)* 重复0个或多个前面的字符
7).* 匹配所有的字符。^.* 任意多个字符开头。
8)[] 匹配字符集合内任意一个字符,如[a-z]
9)[^abc] ^在中括号里表示非,不包含a或b或c
10){n,m} 匹配n到m次,前一个字符。
{n,} 至少N次,多了不限。
{n} n次
{,m} 至多m次,少了不限。
注意:grep要将{}转义,\{\},egrep不需要转义
12)\(\),定义子表达式的开始和结束位置。例如,正则表达式“\(love\).*\1”表示匹配2个“love”中间 包含任意个字符的文本行,其中“\1”表示引用前面的“love”
13)\<或\b:锚定词首(支持vi和grep),其后面的任意字符必须作为单词首部出现,如 \<love或\blove
14)\>或\b:锚定词尾(支持vi和grep),其前面的任意字符必须作为单词尾部出现,如 love\>或love\b
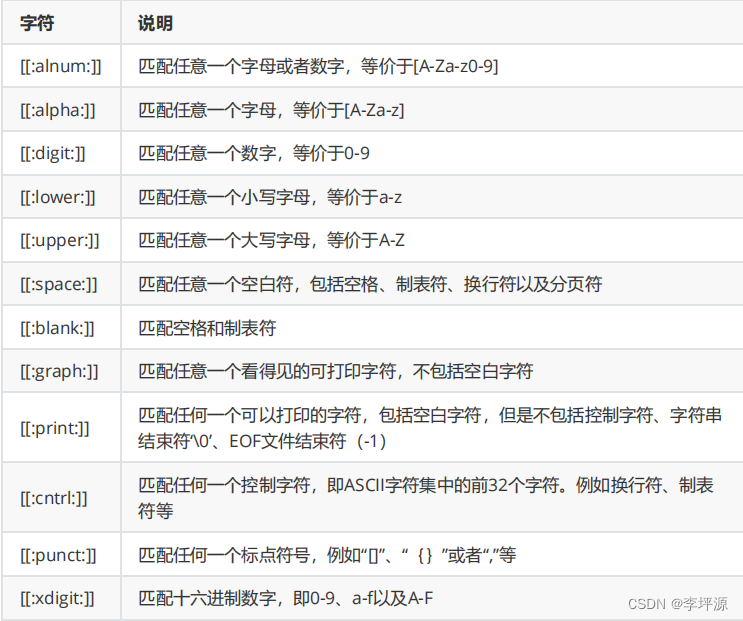
正则表达式字符集
4. 扩展正则表达式
扩展正则表达式(
Extended Regular Expression
,
ERE
)支持比基本正则表达式更多的元字符,但是扩展正则表达式对有些基本正则表达式所支持的元字符并不支持。前面介绍的元字符“^”、
“$”
、
“.”
、
“*”
、“[]”以及
“[^]”
这
6
个元字符在扩展正则表达式都得到了支持,并且其意义和用法都完全相同,不再重复介绍。接下来重点介绍一下在扩展正则表达式中新增加的一些元字符。

5. 示例演示
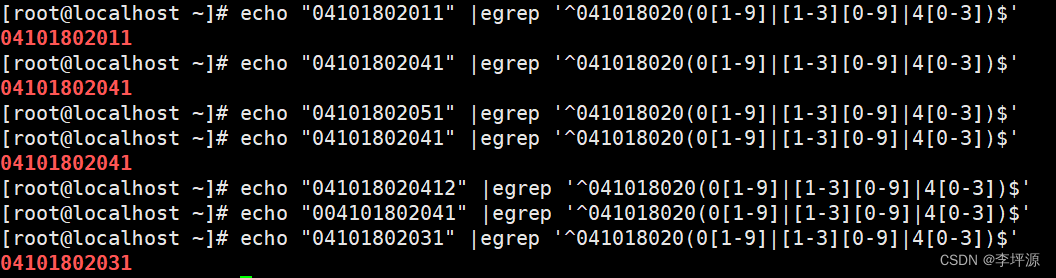
1. 04101802001-04101802043正则表达式匹配
egrep '^041018020(0[1-9]|[1-3][0-9]|4[0-3])$'
^ 从前往后匹配
$ 从后往前匹配
^ $ 一起用可以锁定匹配的位数和范围
041018020 表示前面这几位固定
(0[1-9]|[1-3][0-9]|4[0-3]) 表示后面两个数的范围在01-43测试:
2. ipv4地址,邮箱地址,8位强密码,url正则表达式
2.1 ipv4地址
首先要匹配0-255这256个数字,由于正则表达式在这里不能直接使用数值大小进行匹配,并且需要尽可能地精确控制数值范围,所以我们将其分为0-9、10-99、100-199、200-249、250-255一共五个部分:
?: # 非获取匹配,只匹配但是不获取
(?:1[0-9][0-9]\.) # 100-199
(?:2[0-4][0-9]\.) # 200-249
(?:25[0-5]\.) # 250-255
(?:[1-9][0-9]\.) # 10-99
(?:[0-9]\.) # 0-9 注意这五个分组都是或|关系,前面三个部分都是0-255加上一个点.,最后的是没有点的.,所以前面的执行三次匹配,最后再加上没有点.的一次,正好就能匹配所有的IP地址
echo '254.192.168.255'|grep -oP '^(?:(?:1[0-9][0-9]\.)|(?:2[0-4][0-9]\.)|(?:25[0-5]\.)|(?:[1-9][0-9]\.)|(?:[0-9]\.)){3}(?:(?:1[0-9][0-9])|(?:2[0-4][0-9])|(?:25[0-5])|(?:[1-9][0-9])|(?:[0-9]))$'2.2 8位强密码
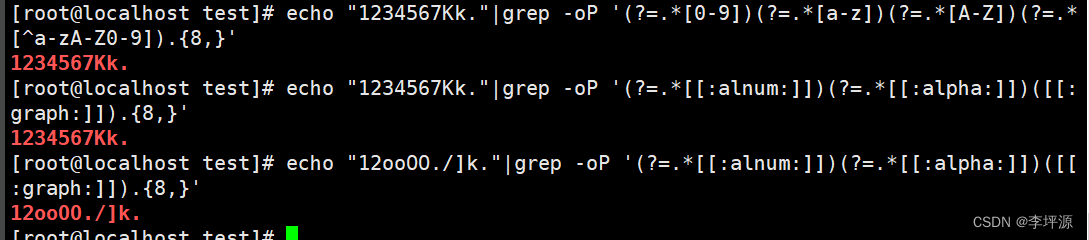
数字+大小写字母+特殊符号,至少8位
echo "1234567Kk."|grep -oP '(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[^a-zA-Z0-9]).{8,}'
或
[root@localhost test]# echo "12ooOO./]k."|grep -oP '(?=.*[[:alnum:]])(?=.*[[:alpha:]])([[:graph:]]).{8,}'
-o 只输入匹配到的
-P 使用扩展perl测试
2.3 url
grep -oP '(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]'
测试
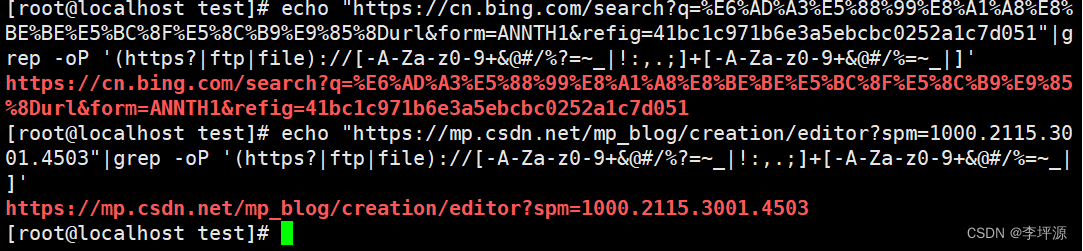
2.4 邮箱地址
邮箱地址组成:用户名@域名
grep -oP '(?:[a-zA-Z0-9]*)@([a-zA-Z0-9]*)\.(?:[a-z]*)'测试
