
背景:
低剂量x射线成像是一种用于疾病筛查和诊断的医学成像方法。然而,由于成像过程产生的噪声,对这些图像的复原是一项具有挑战性的任务。尽管一些基于深度学习的去噪算法已经取得了相当大的进展,但它们在真实x射线图像上的表现并不好,因为x射线图像的实际噪声更复杂。
存在问题:
在低辐射剂量下降低入射光子密度和光子不均匀性将导致更高的量子噪声(也称为光子噪声或泊松噪声),这是一种与信号相关的噪声。同时,x射线传感器等电子设备产生的常见热噪声会进一步破坏x射线图像,这是一种信号无关的噪声。根据x射线成像系统的特点,与信号相关的量子噪声比热噪声对图像的影响更大
现有的方法忽略了x射线图像的物理形成机制,不能很好地适应真实的噪声x射线图像。
创新点:
- 在X-BDCNN中设计了噪声级估计子网络,对泊松噪声和高斯噪声进行估计,将盲去噪问题转化为非盲去噪问题。
- 提出了一个真实的混合泊松-高斯噪声网络模型。
建模:
x射线成像系统通常受到两种类型的噪声的影响:量子噪声是与信号相关的噪声,热噪声是与信号无关的噪声。根据这一特性,我们建立了混合泊松-高斯噪声模型来模拟低剂量x射线图像的降解过程,定义为:
![]()
Xp表示被泊松噪声损坏的图像,N表示热噪声,热噪声是一种均值为零,方差为σ 2的信号无关高斯噪声。
x射线成像的物理原理是人体不同部位对x射线的吸收能力不同。受康普顿效应的影响,光子能量减弱,散射方向发生改变,导致得到的x射线图像带有大量的量子噪声。
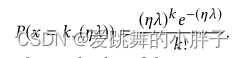
λ为干净图像的像素值,k为带噪图像的像素值。泊松分布P(x = k, λ)描述了原始像素值为λ时像素值k的概率。由于泊松噪声的强度与源图像的像素值有关,在式子中加入一个比例因子η,并用ηλ代替λ。因此,我们可以通过调整比例因子η来获得不同的噪声图像。
噪声水平:σ 和η分别在(0, 20) and (0.4, 1.8)随机取值
网络架构:
本文提出了一种基于CNN的x射线图像盲去噪算法,X-BDCNN的架构如图所示。它由两个子网组成:NLE子网络和NBD子网络
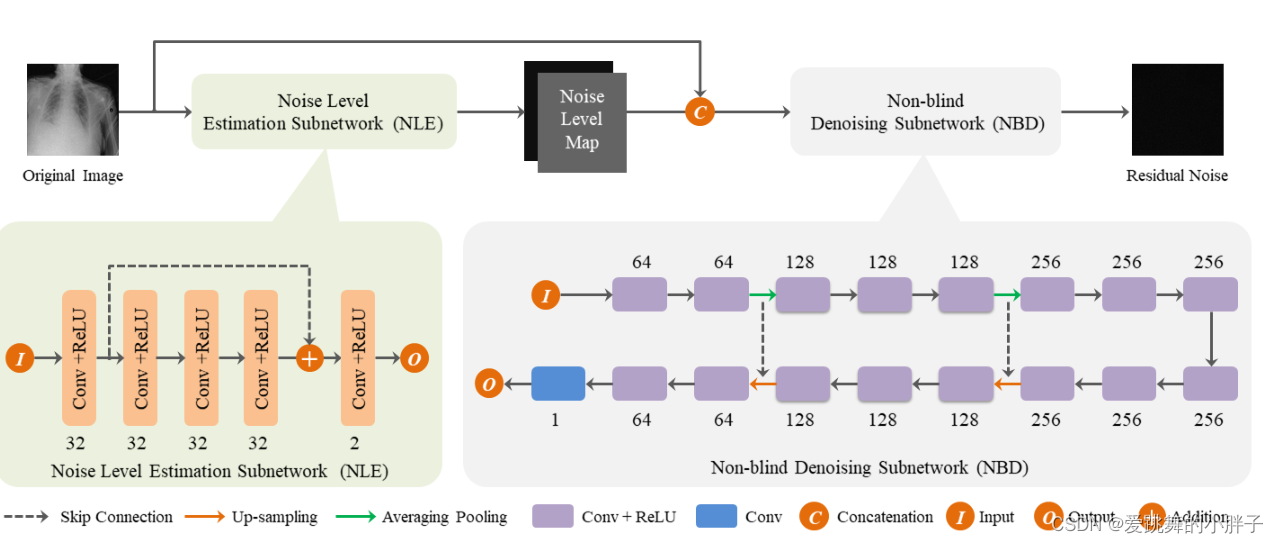
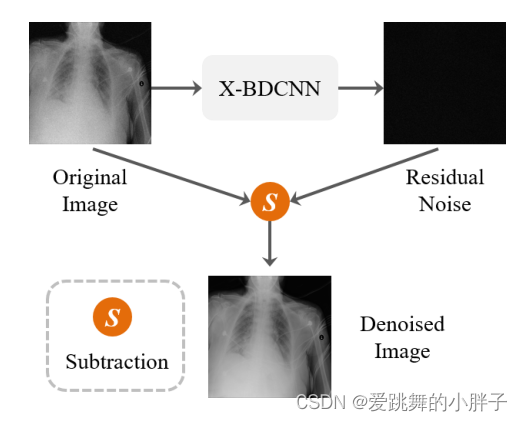
有噪声的x射线图像为输入,输出相应的残差噪声图。通过从噪声图像中减去残留噪声图,得到最终的去噪图像。
学习有噪声图像与干净图像之间的直接映射,而不是学习噪声残留图像,也可以达到图像去噪的目的。但是,学习噪声图像与其噪声残差图像之间的映射是一种更好的策略,因为架构可以被视为一个易于优化的残差单元


损失函数:
1、非对称均方误差(MSE)损失函数:
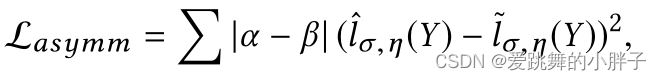
α被选择在0到0.5之间,因为它对低估误差的惩罚更大;
2、基于噪声级图非常平滑的先验知识,我们添加了一个总变分(TV)正则化损失函数LT V来约束噪声级图的估计:


总损失:
![]()
λ1 = 0.4, λ2 = 0.6, λ3 = 0.5, λ4 = 0.05
实验:
数据集:ChestX-ray8 :108,948张正面x光图像。其中的每张图像大小为1024×1024;随机选择了10,000张x射线图像,并将它们裁剪成128×128补丁。总共获得了32万个补丁
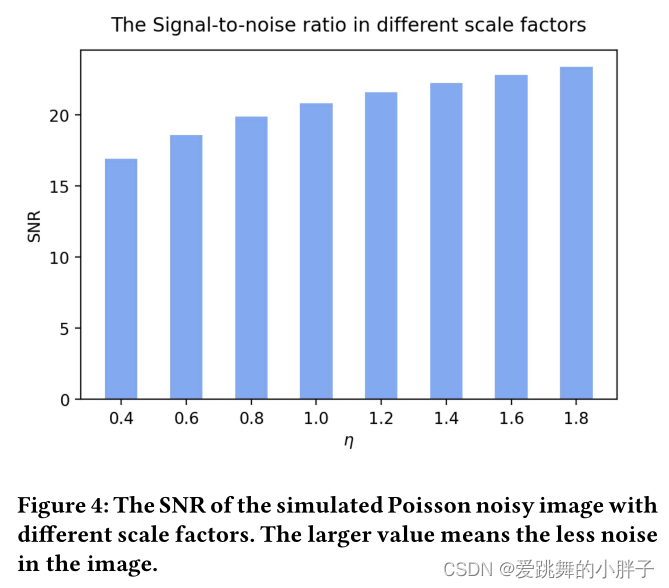
为不同η尺度因子下干净图像与模拟泊松噪声图像的信噪比。直观地表明,随着η标度因子的增加,模拟噪声图像的质量有所提高。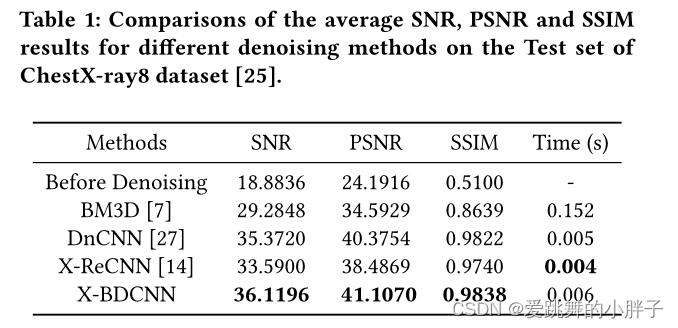
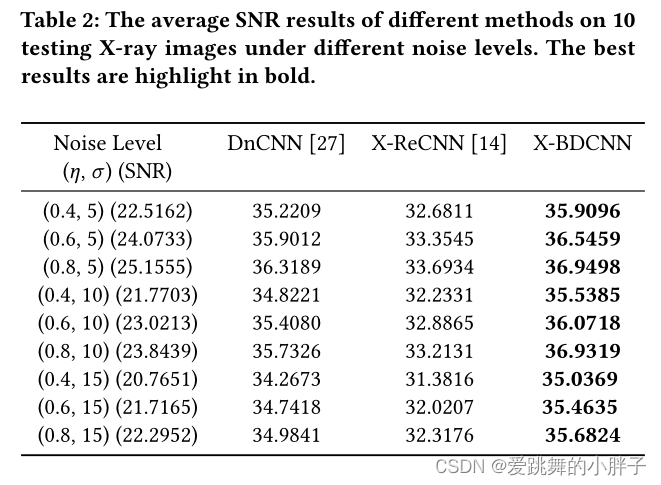

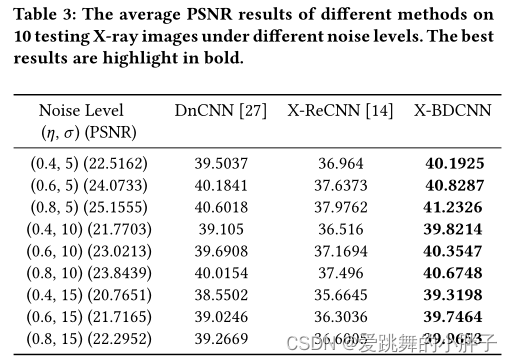
视觉效果:
不同η尺度因子下残差噪声图的可视化热图:

疾病分类实验:
基于x射线图像的疾病诊断准确性是衡量不同方法去噪后x射线图像质量的最佳方法。
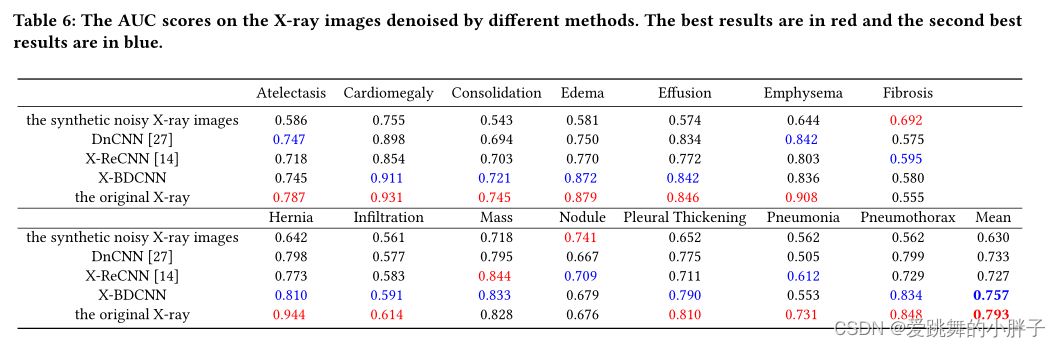
原始无噪声x射线图像的平均AUC得分最高,合成噪声x射线图像的平均AUC得分最低。这说明x线图像的质量与疾病分类的准确性正相关。
一句话总结:根据X射线图像成像物理模型提出一个真实的混合泊松-高斯噪声网络模型,并设计了噪声级估计子网络,对泊松噪声和高斯噪声进行估计,将盲去噪问题转化为非盲去噪问题。
个人想法:
1、感觉和CBDNet的网络框架很像,而且没有和CBDNe进行对比;2022年还把DnCNN作为对比实验,且结果看起来来和图相当。不合理
2、消融实验部分没有把SSIM和NLE去掉的基础方法做实验对比,感觉很不太合理。