大数据教育数仓之在线教育项目回顾
01:在线教育项目需求
-
目标:掌握在线教育项目需求
-
实施
- 常规的需求:通过对数据进行数据分析处理,得到一些指标,来反映一些事实,支撑运营决策
- 行业:在线教育行业
- 产品:课程
- 需求:提高学员报名的转换率,实现可持续化的运营发展
- 需求1:分析学员从访问到报名每个环节的留存率和流失率,发现每个环节存在的问题,解决问题,提高报名率
- 访问分析
- 咨询分析
- 意向分析
- 报名分析
- 通过各个环节的分析,来发现每个环节流失原因,解决问题,实现提高每一步转化率
- 需求2:持续化发展需要构建良好的产品口碑,把控学员学习质量:通过对考试、考勤、作业做管理和把控
- 考勤分析
- 需求1:分析学员从访问到报名每个环节的留存率和流失率,发现每个环节存在的问题,解决问题,提高报名率
-
小结
- 掌握在线教育项目需求
-
面试:项目介绍
02:需求主题划分
- 目标:掌握在线教育中需求主题的划分
- 实施
- 数据仓库的数据管理划分
- 数据仓库【DW】:存储了整个公司所有数据
- 数据集市/主题域【DM】:按照一定的业务需求进行划分:部门、业务、需求
- 主题:每一个主题就面向最终的一个业务分析需求
- 数据集市/主题域【DM】:按照一定的业务需求进行划分:部门、业务、需求
- 数据仓库【DW】:存储了整个公司所有数据
- 在线教育中的需求主题
- 数据仓库:业务系统数据【客服系统、CRM系统、学员管理系统】
- 业务数据仓库:结构化数据
- 数据集市/主题域
- 运营管理集市/运营域
- 销售管理集市/销售域
- 学员管理集市/用户域
- 产品管理集市/产品域
- 广告域
- ……
- 数据主题
- 来源分析主题、访问分析主题、咨询分析主题
- 销售分析主题、线索分析主题、意向分析主题、报名分析主题
- 考勤分析主题、考试分析主题、作业分析主题
- 产品访问主题、产品销售主题、产品付费主题
- 表名:层 _ 【域】 _ 主题 _ 维度表
- 数据仓库:业务系统数据【客服系统、CRM系统、学员管理系统】
- 数据仓库的数据管理划分
- 小结
- 掌握在线教育中需求主题的划分
- 面试:项目中划分了哪些主题域以及有哪些主题?
03:数据来源
- 目标:掌握在线教育平台的数据来源
- 实施
- 访问分析主题、咨询分析主题
- 客服系统:客服系统数据库
- 需求:统计不同维度下的访问用户数、咨询用户数
- 指标:UV、PV、IP、Session、跳出率、二跳率
- 维度:时间、地区、来源渠道、搜索来源、来源页面
- web_chat_ems
- web_chat_text_ems
- 线索分析主题、意向分析主题、报名分析主题
- CRM系统:营销系统数据库
- 需求:统计不同维度下意向用户个数、报名用户个数、有效线索个数
- 维度:时间、地区、来源渠道、线上线下、新老学员、校区、学科、销售部门
- customer_relationship:意向与报名信息表
- customer_clue:线索信息表
- customer:学员信息表
- itcast_school:校区信息表
- itcast_subject:学科信息表
- employee:员工信息表
- scrm_deparment:部门信息表
- itcast_clazz:报名班级信息表
- 考勤分析主题
- 数据来源:学员管理系统
- 需求:统计不同维度下学员考勤指标:出勤人数、出勤率、迟到、请假、旷课
- tbh_student_signin_record:学员打卡信息表
- student_leave_apply:学员请假信息表
- tbh_class_time_table:班级作息时间表
- course_table_upload_detail:班级排课表
- class_studying_student_count:班级总人数表
- 访问分析主题、咨询分析主题
- 小结
- 记住核心的表与字段
- 面试:数据来源是什么?
04:数仓设计
-
目标:掌握业务分析主题中每个主题数仓的实现流程
-
实施
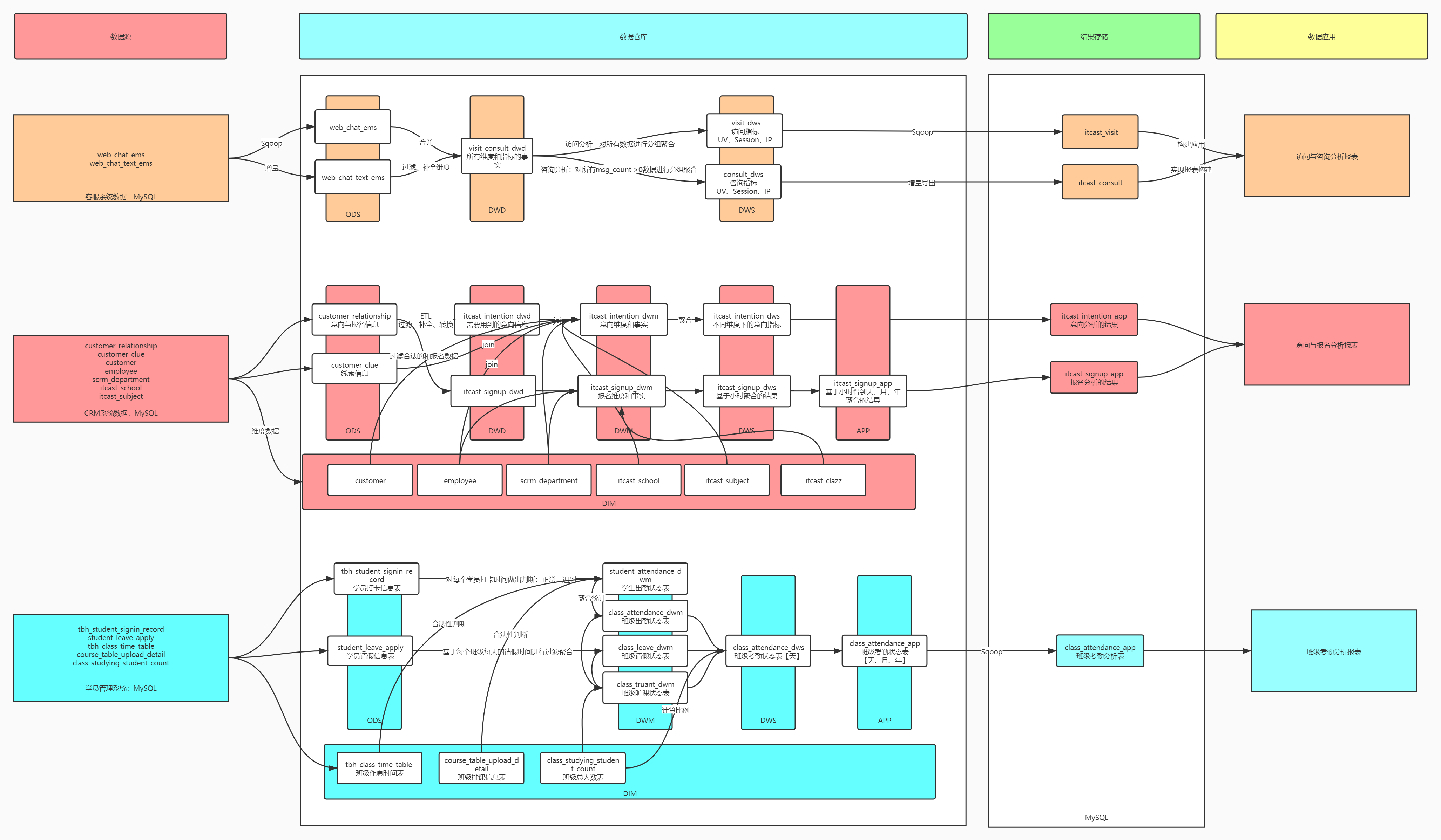
-
访问分析主题
- ODS:web_chat_ems、web_chat_text_ems
- DWD:将两张表进行合并,并且实现ETL
- DWS:基于不同维度统计所有访问数据的用户个数、会话个数、Ip个数
-
咨询分析主题
- ODS:web_chat_ems、web_chat_text_ems
- DWD:直接复用了访问分析的DWD
- DWS:基于不同维度统计所有咨询【msg_count > 0】数据的用户个数、会话个数、Ip个数
-
意向分析主题
- ODS:customer_relationship、customer_clue
- DIM:customer、employee、scrm_department、itcast_shcool、itcast_subject
- DWD:对customer_relationship实现ETL
- DWM:实现所有表的关联,将所有维度和事实字段放在一张表中
- DWS:实现基于不同维度的聚合得到意向人数
-
报名分析主题
- ODS:customer_relationship
- DIM:customer、employee、scrm_department、itcast_clazz
- DWD:对customer_relationship实现ETL并且过滤报名数据
- DWM:实现四张表的关联,将所有维度和事实字段放在一张表中
- DWS:基于小时维度对其他组合维度进行聚合得到指标
- APP:基于小时的结果累加得到天、月、年维度下的事实的结果
-
考勤管理主题
- ODS:tbh_student_signin_record、student_leave_apply
- DIM:tbh_class_time_table、course_table_upload_detail、class_studying_student_count
- DWD:没有
- DWM
- 学员出勤状态表:基于学员打卡信息表
- 班级出勤状态表:基于学员出勤状态表
- 班级请假信息表:基于请假信息表得到的
- 班级旷课信息表:总人数 - 出勤人数 - 请假人数
- DWS:基于天构建天+班级维度下的出勤指标:24个
- APP:基于人次进行Sum累加重新计算月、年的出勤指标
-
-
小结
- 掌握业务分析主题中每个主题数仓的实现流程
- 面试:分层怎么设计的?
- ODS:原始数据层:存储原始数据
- DWD:明细数据层:ETL以后的明细数据
- DWM:轻度汇总层:对主题的事务事实进行构建,关联所有事实表获取主题事实,构建一些基础指标
- DWS:汇总数据层: 构建整个主题域的事实和维度的宽表
- APP:拆分每个主题不同维度的子表
- DIM :维度数据层:所有维度表
05:技术架构
-
目标:掌握整个项目的技术架构
-
实施
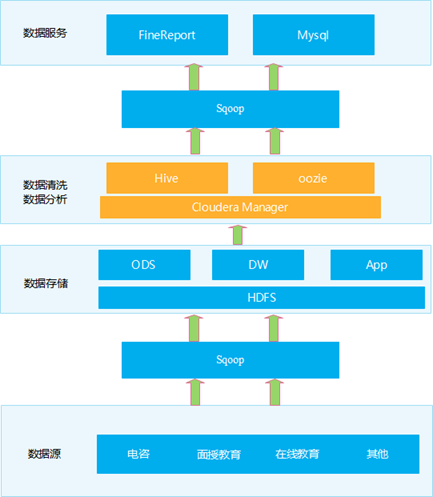
- 数据源:MySQL数据库
- 数据采集:Sqoop
- 数据存储:Hive:离线数据仓库
- 数据处理:HiveSQL【MapReduce】 =》 以后简历中要改为SparkSQL等工具来实现
- 数据结果:MySQL
- 数据报表:FineBI
- 协调服务:Zookeeper
- 可视化交互:Hue
- 任务流调度:Oozie
- 集群管理监控:Cloudera Manager
- 项目版本管理:Git
-
小结
- 掌握整个项目的技术架构
- 面试:项目介绍或者项目的技术架构?
06:项目优化
-
目标:掌握Hive的常见优化
-
实施
-
属性优化
-
本地模式
hive.exec.mode.local.auto=true; -
JVM重用
mapreduce.job.jvm.numtasks=10 -
推测执行
mapreduce.map.speculative=true mapreduce.reduce.speculative=true hive.mapred.reduce.tasks.speculative.execution=true -
Fetch抓取
hive.fetch.task.conversion=more -
并行执行
hive.exec.parallel=true hive.exec.parallel.thread.number=16 -
压缩
hive.exec.compress.intermediate=true hive.exec.orc.compression.strategy=COMPRESSION mapreduce.map.output.compress=true mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec -
矢量化查询
hive.vectorized.execution.enabled = true; hive.vectorized.execution.reduce.enabled = true; -
零拷贝
hive.exec.orc.zerocopy=true; -
关联优化
hive.optimize.correlation=true; -
CBO优化器
hive.cbo.enable=true; hive.compute.query.using.stats=true; hive.stats.fetch.column.stats=true; hive.stats.fetch.partition.stats=true; -
小文件处理
#设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入 hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并 hive.merge.mapfiles=true; hive.merge.mapredfiles=true; hive.merge.size.per.task=256000000; hive.merge.smallfiles.avgsize=16000000; -
索引优化
hive.optimize.index.filter=true -
谓词下推PPD
hive.optimize.ppd=true;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4UGgQtXE-1690355726417)(J:/baidudownload/09-第九阶段spark项目-一站式制造/Day5_数仓事实层DWB层构建/02_随堂笔记/Day5_数仓事实层DWB层构建.assets/image-20210518184328346.png)]
- Inner Join和Full outer Join,条件写在on后面,还是where后面,性能上面没有区别
- Left outer Join时 ,右侧的表写在on后面,左侧的表写在where后面,性能上有提高
- Right outer Join时,左侧的表写在on后面、右侧的表写在where后面,性能上有提高
- 如果SQL语句中出现不确定结果的函数,也无法实现下推
-
Map Join
hive.auto.convert.join=true hive.auto.convert.join.noconditionaltask.size=512000000 -
Bucket Join
hive.optimize.bucketmapjoin = true; hive.auto.convert.sortmerge.join=true; hive.optimize.bucketmapjoin.sortedmerge = true; hive.auto.convert.sortmerge.join.noconditionaltask=true; -
Task内存
mapreduce.map.java.opts=-Xmx6000m; mapreduce.map.memory.mb=6096; mapreduce.reduce.java.opts=-Xmx6000m; mapreduce.reduce.memory.mb=6096; -
缓冲区大小
mapreduce.task.io.sort.mb=100 -
Spill阈值
mapreduce.map.sort.spill.percent=0.8 -
Merge线程
mapreduce.task.io.sort.factor=10 -
Reduce拉取并行度
mapreduce.reduce.shuffle.parallelcopies=8 mapreduce.reduce.shuffle.read.timeout=180000
-
-
SQL优化
-
核心思想:先过滤后处理
- where和having使用
- join中on和where使用
- 将大表过滤成为小表再join
-
-
设计优化
-
分区表:减少了MapReduce输入,避免不需要的过滤
-
分桶表:减少了比较次数,实现数据分类,大数据拆分,构建Map Join
-
文件存储:优先选用列式存储:parquet、orc
-
-
-
小结
- 熟练掌握Hive中的优化
- 面试:项目中做了哪些优化?Hive做了哪些优化?
07:项目问题
-
目标:掌握Hive的常见优化
-
实施
-
内存问题:现象程序运行失败
- OOM:out of memory
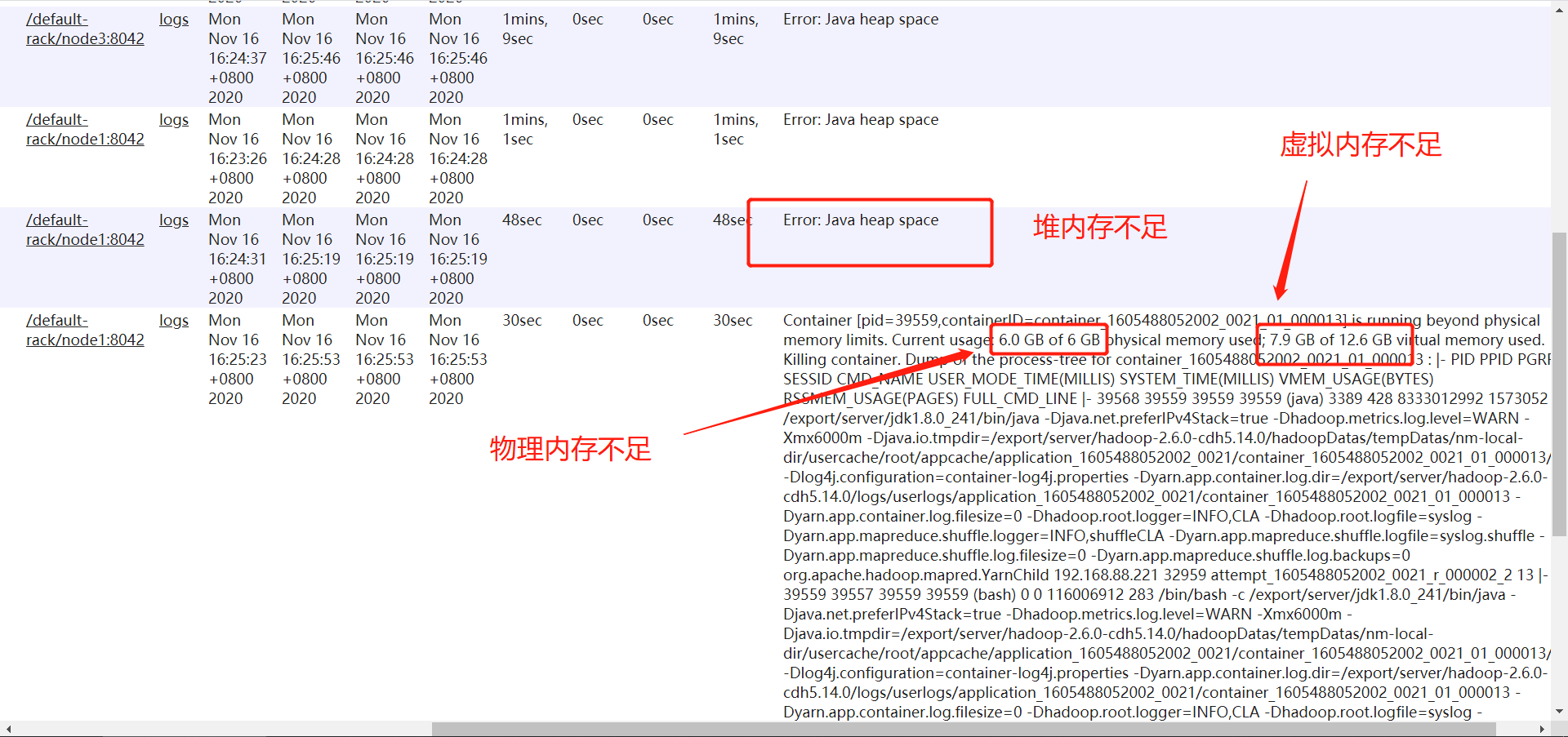
-
堆内存不足:给Task进程分配更多的内存
mapreduce.map.java.opts=-Xmx6000m; mapreduce.map.memory.mb=6096; mapreduce.reduce.java.opts=-Xmx6000m; mapreduce.reduce.memory.mb=6096; -
物理内存不足
- 允许NodeManager使用更多的内存
- 硬件资源可以扩充:扩充物理内存
- 调整代码:基于分区处理、避免Map Join
-
虚拟内存不足:调整虚拟内存的比例,默认为2.1
-
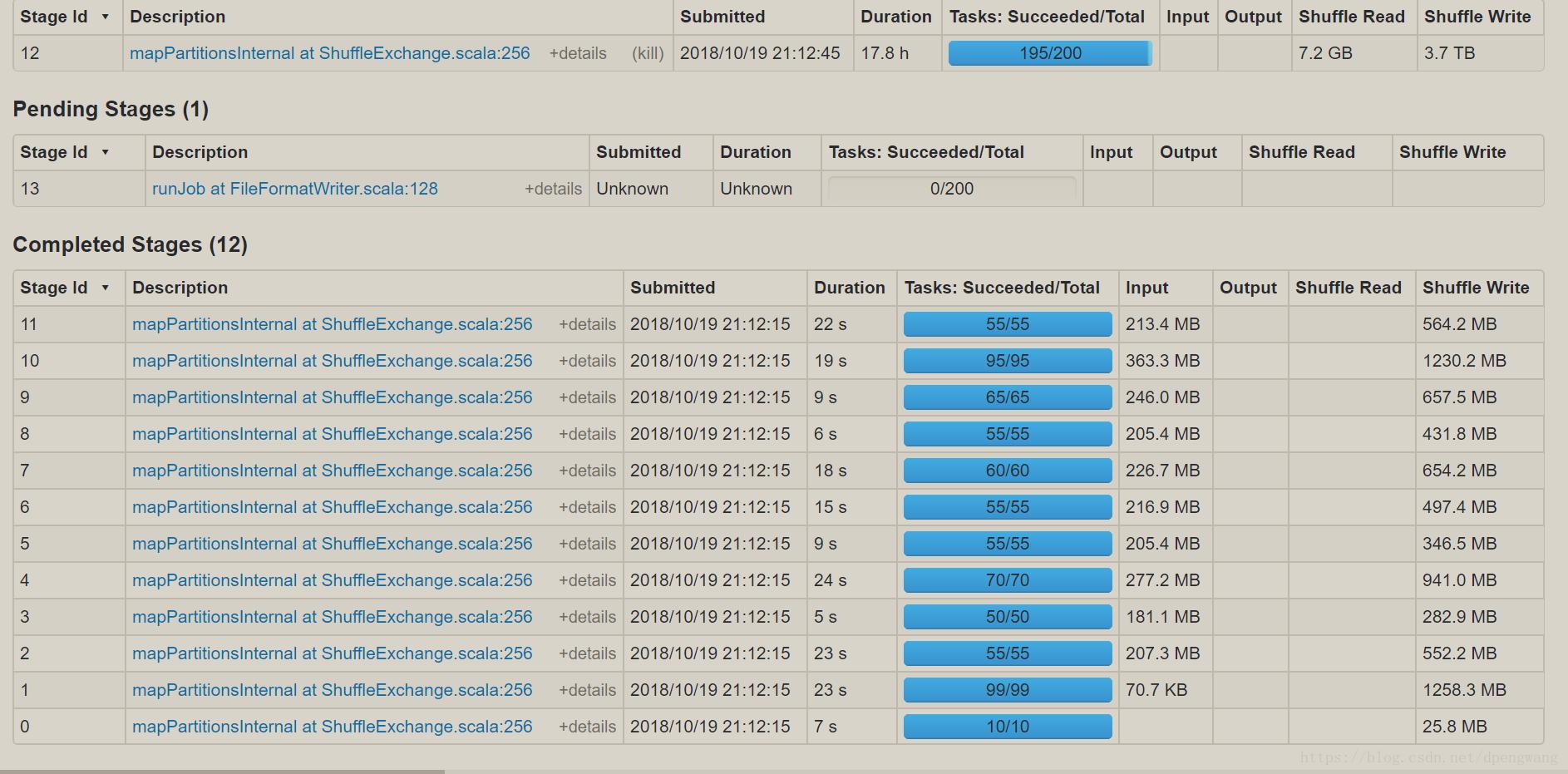
数据倾斜问题:程序运行时间长,一直卡在99%或者100%
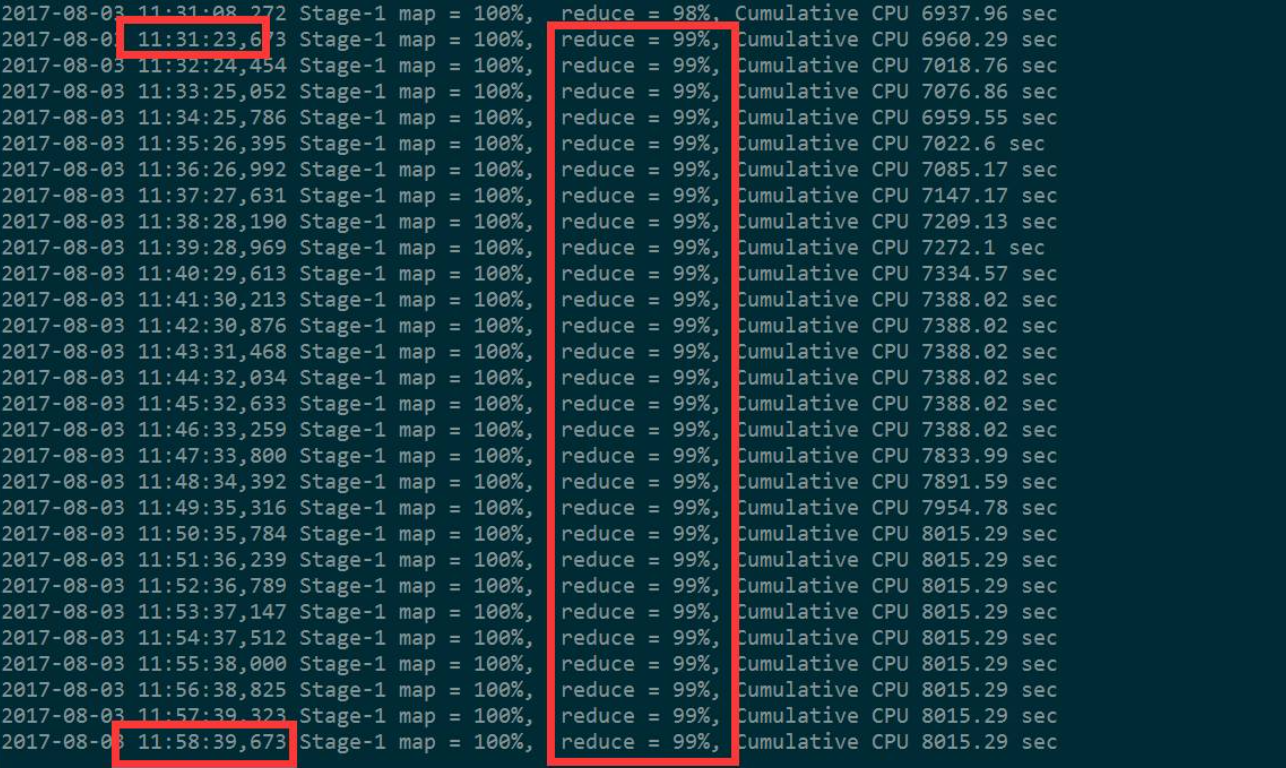
-
-
现象
- 运行一个程序,这个程序的某一个Task一直在运行,其他的Task都运行结束了,进度卡在99%或者100%
-
基本原因
-
基本原因:这个ReduceTask的负载要比其他Task的负载要高
- ReduceTask的数据分配不均衡
-
-
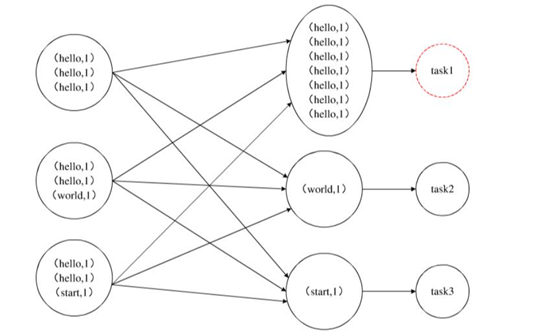
根本原因:分区的规则
-
默认分区:根据K2的Hash值取余reduce的个数
- 优点:相同的K2会由同一个reduce处理
- 缺点:可能导致数据倾斜
-
-
数据倾斜的场景
- group by / count(distinct)
- join
-
解决方案
-
group by / count(distinct)
-
开启Combiner
hive.map.aggr=true -
随机分区
-
方式一:开启参数
hive.groupby.skewindata=true-
开启这个参数以后,底层会自动走两个MapReduce
-
第一个MapReduce自动实现随机分区
-
第二个MapReduce做最终的聚合
-
-
方式二:手动指定
distribute by rand():将数据写入随机的分区中distribute by 1 :将数据都写入一个分区
-
-
-
join
-
方案一:尽量避免走Reduce Join
- Map Join:尽量将不需要参加Join的数据过滤,将大表转换为小表
- 构建分桶Bucket Map Join
-
方案二:skewjoin:避免数据倾斜的Reduce Join过程
--开启运行过程中skewjoin set hive.optimize.skewjoin=true; --如果这个key的出现的次数超过这个范围 set hive.skewjoin.key=100000; --在编译时判断是否会产生数据倾斜 set hive.optimize.skewjoin.compiletime=true; --不合并,提升性能 set hive.optimize.union.remove=true; --如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并 set mapreduce.input.fileinputformat.input.dir.recursive=true;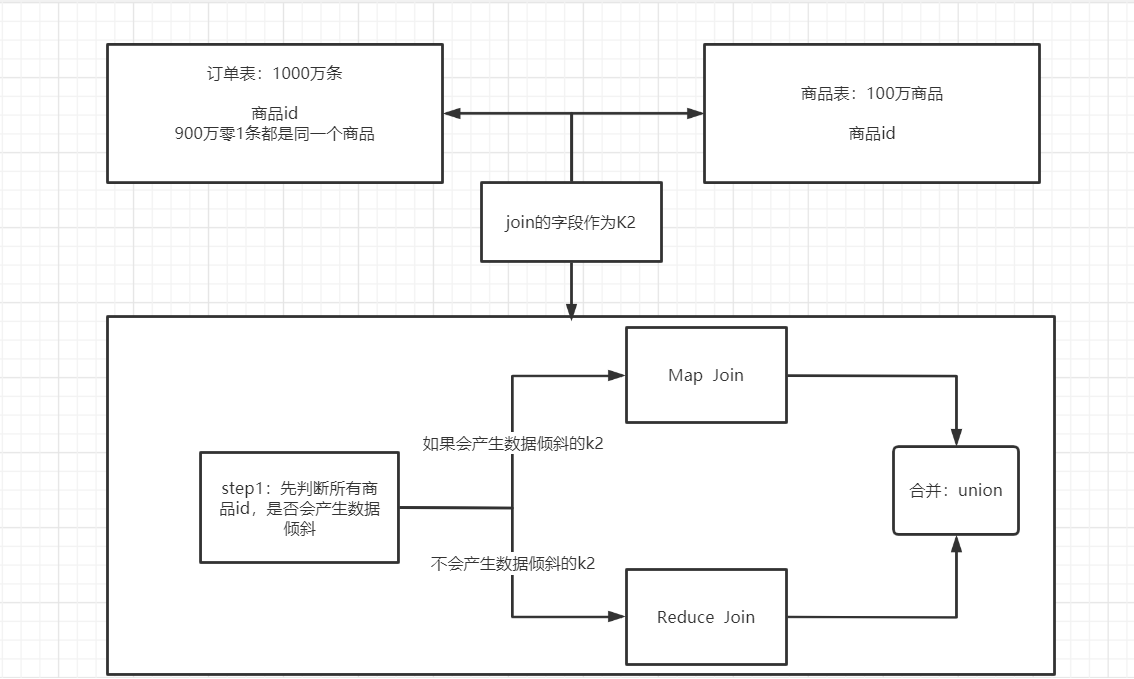
-
-
-
小结
- 掌握Hive中常见的内存溢出及数据倾斜问题
- 面试:数据倾斜怎么解决?
- 调大分区个数:重分区
- Join时候, 可以将小的数据实现广播
- 自定义分区规则:RDD五大特性:对于二元组类型的RDD,可以指定分区器
- reduceByKey(partitionClass = HashPartition)
-
技术面试:理论为主
-
Hadoop:HDFS读写原理,YARN中程序运行流程、端口号、哪些进程、MapReduce运行过程
-
Hive:SQL语句,函数应用
- 字符串函数、日期函数、判断函数、窗口函数
-