目录
P003
时间切片:时间回溯,找回以前的数据。
P004【数仓概念讲的颇为详细】
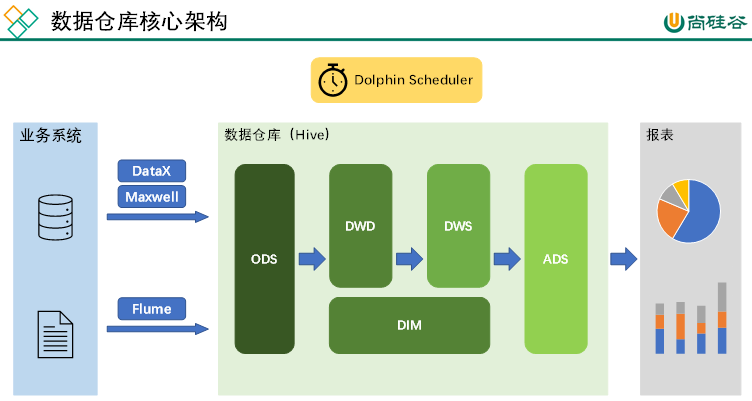
核心架构
- 业务数据:用户和系统网站进行交互所产生的数据,如下单交付数据,存在mysql中。
- datax:全量表的采集。
- maxwell:增量表的实时监控。
- 用户行为日志:点击网站所进行的一系列动作。
- flume:采集数据。
- hdfs:文件存储系统存放数据。
- kafka:为实时数仓搭建作准备,flink从kafka中读取数据。
- hive+hdfs,hive套在hdfs上,分层计算形成数仓。
- hdfs:只支持新增及追加写数据,不支持实时修改与删除。
- hive:可以用update命令修改数据,整个文件读取出来修改后覆盖写回去,效率较低,因此将计算结果保存在新表中。
数仓分层
- ods:operation data store,原始数据层。
- dwd:data warehouse detail,明细数据层。
- dws:data warehouse summary,汇总数据层。
- dim:dimension,公共维度层。
- ads:application data service,数据应用层。
P018
幂等性(Idempotence) 是一个重要的概念,指的是对同一个操作的重复执行不会产生额外的影响,结果与执行一次操作的结果相同。换句话说,无论对一个操作执行多少次,最终的状态都是一致的。

P019
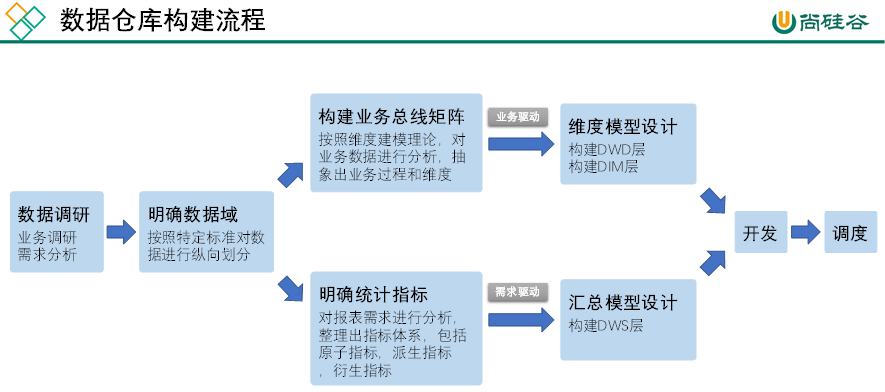
以下是构建数据仓库的完整流程。
P020
交易业务流程

P021
5.2.2 明确数据域
数据仓库模型设计除横向的分层外,通常也需要根据业务情况进行纵向划分数据域。
划分数据域的意义是便于数据的管理和应用。
通常可以根据业务过程或者部门进行划分,本项目根据业务过程进行划分,需要注意的是一个业务过程只能属于一个数据域。
下面是本数仓项目所需的所有业务过程及数据域划分详情。
数据域
业务过程
交易域
加购、下单、支付成功
流量域
页面浏览、启动应用、动作、曝光、错误
用户域
注册、登录
互动域
收藏、评价
考试域
考试
学习域
观看视频
P022
业务总线矩阵中包含维度模型所需的所有事实(业务过程)以及维度,以及各业务过程与各维度的关系。矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。

P023
按照事务型事实表的设计流程,选择业务过程à声明粒度à确认维度à确认事实,得到的最终的业务总线矩阵见以下表格。

P024
5.2.4 明确统计指标
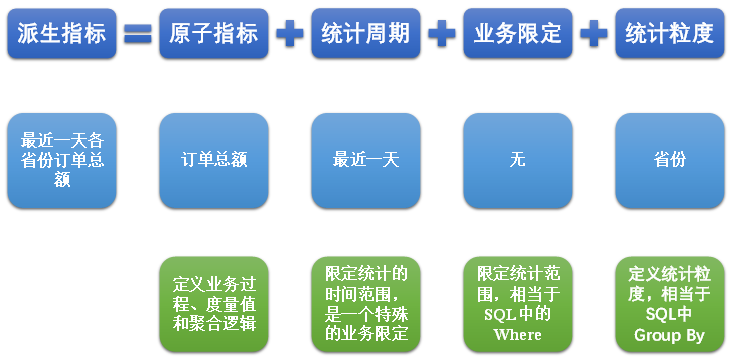
(1)原子指标
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行了定义。我们可以得出结论,原子指标包含三要素,分别是业务过程、度量值和聚合逻辑。
例如订单总额就是一个典型的原子指标,其中的业务过程为用户下单、度量值为订单金额,聚合逻辑为sum()求和。需要注意的是原子指标只是用来辅助定义指标一个概念,通常不会对应有实际统计需求与之对应。
(2)派生指标
派生指标基于原子指标,其与原子指标的关系如下图所示。
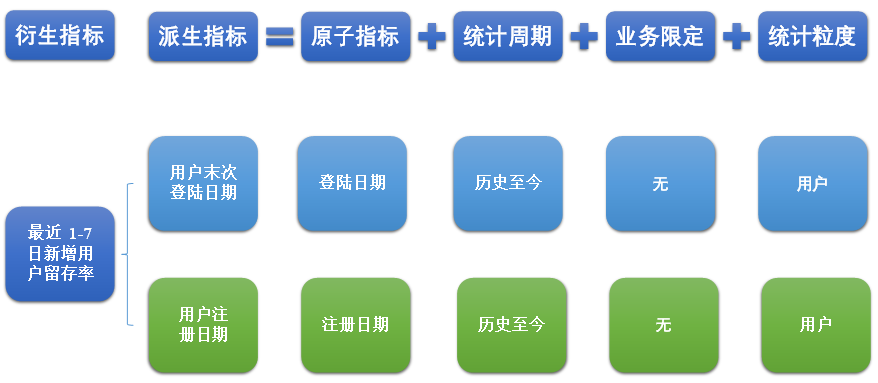
(3)衍生指标
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的。例如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。
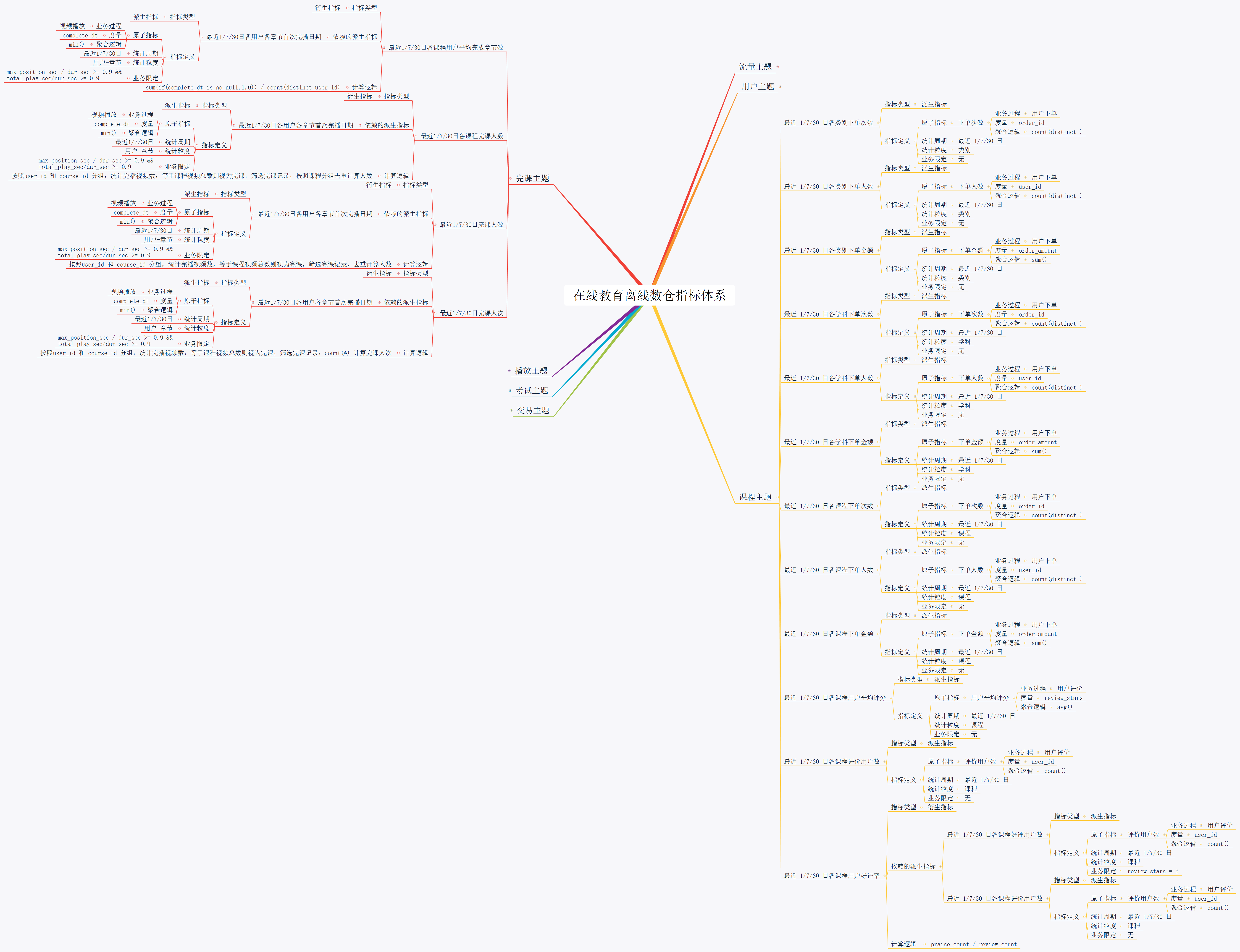
在线教育离线数仓指标体系