FM的总结:
1、FM算法与线性回归相比增加了特征的交叉。自动选择了所有特征的两两组合,并且给出了两两组合的权重。
2、上一条所说的,如果给两两特征的组合都给一个权重的话,需要训练的参数太多了。比如我们有N维的特征,这样的话就需要N*N量级的参数。FM算法的一个优点是减少了需要训练的参数。这个也是参考了矩阵分解的想法。有N个特征,特征间的权重,需要一个N*N的权重矩阵。把这个N*N的矩阵分解成 K*N的矩阵V的乘积,权重矩阵W=VT*V。把每个特征用长度为K的向量来表示,此处应该是每个特征也有一个向量,而不是每个特征的值有一个向量。比如有一个长度为K的向量来表示性别这个特征。
此处的K是自己设置的,K<<N。
3、FM算法的表示公式为:
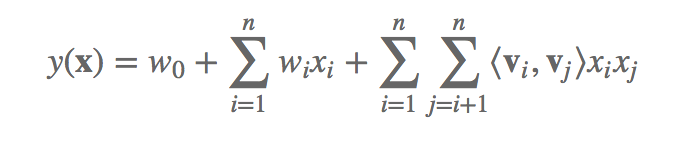
如果按这个直接算的话就是N2的复杂度了,比较高。然后针对后一部分进行化简,变成KN复杂度的。
这部分的化简主要使用了 x*y = 1/2( (x+y)2 - x2 - y2)。
变换之后的是这个样子的:
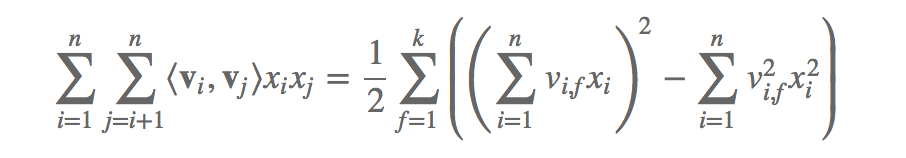
4、然后是FM的训练。
我们再来看一下FM的训练复杂度,利用SGD(Stochastic Gradient Descent)训练模型。模型各个参数的梯度如下
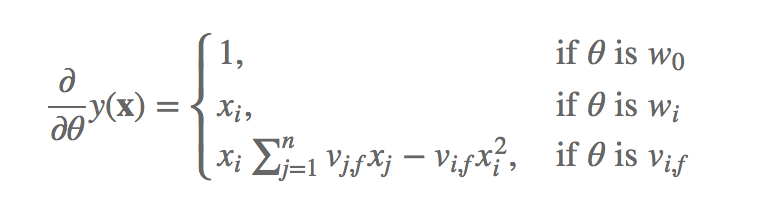

未完待续,等我看完论文再写点
参考资料:https://tech.meituan.com/deep-understanding-of-ffm-principles-and-practices.html