(作者:陈玓玏)
1. 为什么要用FM
在计算广告中使用逻辑回归等算法进行CTR(广告点击率)、CVR(转化率)等预估时,有三个重要的问题:
1) 特征稀疏问题。关于客户的特征和关于广告的特征都有很多的标称型特征,如客户所在地区、职业、性别,以及广告的主题等,这些属性无法比较大小,因此需要经过one-hot编码处理才能进入模型。但one-hot编码后会产生大量的0值特征,这对于逻辑回归、SVM等模型的求解都是非常不友好的,会造成预测性能差。
2) 特征空间非常大的问题。如果原来的标称特征有500个可选值,那么这个特征经过one-hot编码就会衍生成500个特征,那么对于电影、电商等品类标称特征非常多的场景来说,求解会变得困难。
3) 没有考虑特征之间的相互关系。但考虑这些是有必要的,因为点击率本身是属于预测客户的特征与广告特征之间的一个匹配度,所以必须关注客户特征和广告特征的关系(比如女性关注美妆),这一点和分类问题是不一样的。在这种情况下,适合使用的传统机器学习算法只有SVM,因为SVM的核方法能够学习它的交叉特征,但是SVM不适合稀疏场景。
由于以上三个问题的存在,FM应运而生,那么FM的特点也很明显了:适用于特征稀疏的场景,并且能够学习特征之间的关系。
2. FM模型公式
传统的线性模型的公式如下:
y(x)=ω0+i=1∑nωixi
这个公式中还未包含交叉特征,那么现在把所有特征都做交叉:
y(x)=ω0+i=1∑nωixi+i=1∑nj=i+1∑nωijxixj
最后一项即交叉特征和它们的权值的乘积和,即
ω12x1x2+ω13x1x3+…+ω(n−1)nxn−1xn。接下来的问题是,
ωi的求解是很简单的,那怎么求解
ωij呢?在SVM中我们是用核方法来求解的,但这里不行,这里是借鉴的矩阵分解的思想。
我们首先把交叉特征的权值矩阵写出来:
⎝⎜⎜⎜⎛ω11ω21⋮ωn1ω12ω22⋮ωn2ω13ω23⋮ωn3⋯⋯⋱⋯ω1nω2n⋮ωnn⎠⎟⎟⎟⎞
因为我们在实际的模型公式是只需要计算不重复的值,因此虽然现在写出来的矩阵中有
n2个值,模型公式中只用到了矩阵中
2n(n−1)个值。实际上这个矩阵是一个对称矩阵,因为本身交叉特征
x1x2和
x2x1就是一样的,系数自然也一样。至于对角矩阵,只要它的值能保证矩阵正定,也就是满足可分解条件即可。那么
ω矩阵可以分解为
VTV的形式,如下所示:
ω=VTV=⎝⎜⎜⎜⎛v11v21⋮vn1v12v22⋮vn2v13v23⋮vn3⋯⋯⋱⋯v1kv2k⋮vnk⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛v11v12⋮v1nv21v22⋮v2nv31v32⋮v3n⋯⋯⋱⋯vk1vk2⋮vkn⎠⎟⎟⎟⎞
也就是将大小为
n∗n的
ω矩阵分解成了
n∗k的
V矩阵的乘积。一般
k是要远小于
n的,至于
k具体是多少,为什么会远小于
n,这个这篇算法写完了再研究一下。
为了方便推导,把上面的公式再简化一下:
y(x)=ω0+i=1∑nωixi+i=1∑nj=i+1∑n<vi
,vj
>xixj
<vi,vj>表示向量点乘,直接这么看仍然是看不出什么名堂的,接下来推导一下:
i=1∑nj=i+1∑n<vi
,vj
>xixj=21i=1∑nj=1∑n<vi
,vj
>xixj−21i=1∑nj=1∑n<vi
,vj
>xixi
可以这样做的原因是,两项相减,减去的是
ω矩阵对角线上的元素,剩下的是对称元素,
21合并后就是原来的模型公式。接着往下展开:
i=1∑nj=i+1∑n<vi
,vj
>xixj=21i=1∑nj=1∑nf=1∑kvifvjfxixj−21i=1∑nf=1∑kvifvifxixi
把求和符号放到式子里面,得到:
i=1∑nj=i+1∑n<vi,vj>xixj=21f=1∑k((i=1∑nvifxi)(j=1∑nvjfxj)−21i=1∑nvif2xi2)=21f=1∑k((i=1∑nvifxi)2−21i=1∑nvif2xi2)
把这个结果带入到模型公式中,我们就可以通过梯度下降法来求解
ω和
v参数了,具体的求解其实还得看你想要什么样的结果,如果想要作为一个二分类问题来考虑,预测其点击的概率值,可以在
y(x)上加上sigmoid激活函数,那么在使用梯度下降法求导时,也可以采用逻辑回归的交叉熵损失函数来求解参数。但不管是用哪种损失函数来求解,都是要求
∂θ∂y^的,其结果如下:
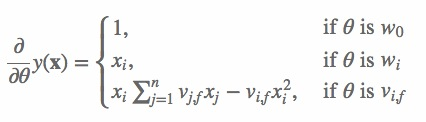
具体的公式就是把这个公式里面的结果代入到损失函数求导的结果中,逐步更新梯度直到收敛即可。
FM是一种比较灵活的模型,通过合适的特征变换方式,FM可以模拟二阶多项式核的SVM模型、MF模型、SVD++模型等[1]。参数因子化使得
xhxi的参数和
xixj 的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说,
xhxi的参数和
xixj 的系数分别为
<vh
,vi
>和
<vi
,vj
>,它们之间有共同项
vi
。也就是说,所有包含“
xi的非零组合特征”(存在某个
j̸=i,使得
xixj̸=0)的样本都可以用来学习隐向量
vi
,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中,
ωhi 和
ωij 是相互独立的[1]。
3. FFM算法
FFM是基于FM的,它改进的地方在于添加了field。之前在FM中,原始特征新生成的特征,我们是没有它们原本的关系保留下来的,但在FFM中,这种关系得到了保留,那就是同一个原始特征延伸出的新特征属于同一个Field。那么FM是对每一个新特征学习一个长度为
k的隐式向量
vi
,共有
nk个参数,而FFM是对每一个新特征学习
f个长度为
k的隐式向量
vi,fj
,共有
nkf个参数,也就是说,FFM有
f个FM中的参数矩阵,针对每个field都有一个。从这个角度看,FM是FFM的
f=1的特例。
y(x)=ω0+i=1∑nωixi+i=1∑nj=i+1∑n<vi,fj
,vj,fi
>xixj
3.1 FFM例子
考虑以下一个样本:
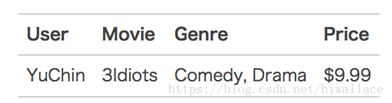
将它转换成FFM算法需要的形式:
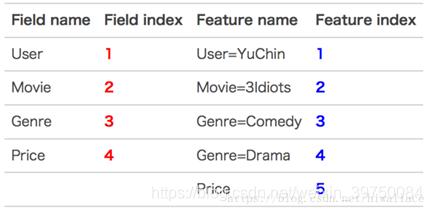
那么这个样本的模型公式最后一个部分的计算结果为:

<v1,2
,v2,1
>索引产生的逻辑是:第1个特征的feature index=1,第2个特征的field index=2,第2个特征的feature index=2,第1个特征的field index=1。后面依此类推。总之,红色是field编号,蓝色是特征编号,绿色是此样本的特征取值,同一项的特征编号和field编号总是交叉的。
FFM损失函数
网络上实现的版本里,模型公式没有考虑非交叉特征,因此,其模型公式如下:
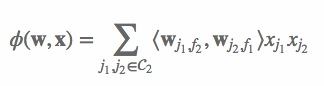
其损失函数如下:
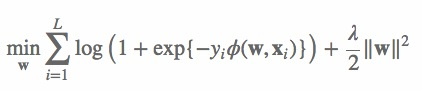
3.2 一个想要讨论的问题
其实我不是很懂为什么要交叉着来?想让特征交叉得更充分?:
我自己关于FFM一个非常拙劣的理解就是,FM是把特征与特征之间的关系表现出来了,但是没有表现客户与品牌、客户与主题这类filed与filed之间的关系,也就是说,把原始的特征的业务含义给稀释掉了,但是通过加入field概念,计算不同特征与不同field的隐式向量(同一个field的特征与另一个field的隐式向量一起应该就能说明两个field之间的相互关系了?),可能交叉也是这个含义吧,如果不交叉,以上说的这些其实就都没有意义了。
参考文章:
1. https://blog.csdn.net/happytofly/article/details/80122160(这个原文是美团的人写的,但链接失效了,这个也是一样的内容)
2. https://blog.csdn.net/hiwallace/article/details/81333604
3. https://blog.csdn.net/hualinchangfeng/article/details/78606658