目录
总体图
基础知识:one-hot编码(可看我之前的博客onehot-词嵌入-图嵌入-CSDN博客)
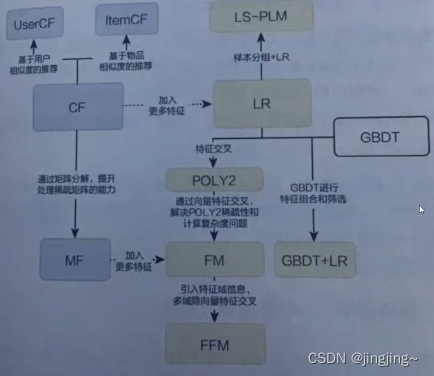
上图为传统推荐模型的演化图,从这个图中可以看出POLY2是从LR(逻辑回归)演化而来,并在它的基础上添加了一个特征交叉。
1、POLY2针对的问题
逻辑回归(LR)存在很大的一个问题就是只对单一特征做简单加权,不具备特征交叉生成组合特征的能力,因此表达能力受到了限制。
2、什么是特征交叉
特征交叉是指在机器学习和数据分析中的一种操作,它涉及将不同特征(或属性)之间的信息结合在一起,以创建新的特征或属性。这有助于提高模型的性能,尤其是在处理复杂数据集时。
例子:
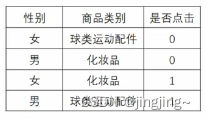
如表中所示,特征是性别(男、女)和商品类别(球类运动配件、化妆品),标签为是否点击(0代表未点击、1代表点击)。表中意为女对于球类运动点击的概率小些先定义为0,男对于化妆品点击的少些即也为0,同理为1的时候。然后对其进行one-hot编码。
当无特征交叉时,如下所示,相当于LR逻辑回归,W代表权重,这里的x1=1,x2=0,x3=1,x4=1,点击预测为y(hat)=0.6。

当有特征交叉时,如下图所示,主要区别在于划红线的位置(即为特征交叉),参数和上述类似,最后发现结果的预测概率比无特征交叉要高,这也是为什么要新增特征交叉的原因。

3、POLY2模型
3.1数学模型
如下公式即为该模型的数学公式,与LR的区别即为红线处,也就是下图矩阵的上三角形,除去对角线。


3.2损失函数
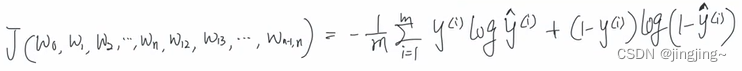 即为二元交叉熵损失。
即为二元交叉熵损失。
3.3梯度下降
3.3.1求梯度(对W求偏导的过程)

同理

同理
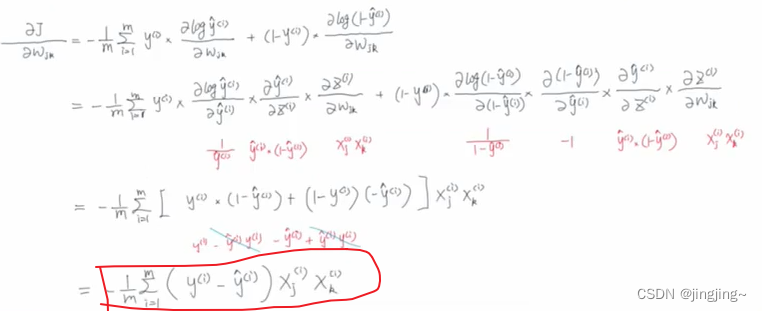
3.3.2梯度更新

这里的是加号,原因在于上步中是减号。
3.4部分代码

时间复杂度:O(n^2),因为相比RL有双层的累加求和,经过两次的for循环。
3.5优缺点
3.5.1优点
1. 既保留了逻辑回归的优点:充分利用用户特征、物品特征、上下文特征。
2.一定程度上解决了特征组合的问题。
3.5.2缺点
1.one-hot编码处理类别型数据时,会让特征向量变得极度稀疏【无选择的】特征交叉,‘暴力’组合特征,会让原本就非常稀疏的特征向量更加稀疏导致大部分交叉特征的权重缺乏有效的数据进行训练,无法收敛。
如刚刚讲到的例子:



上图中的黄色只是取的两个例子,而实际中是经过暴力无差别的组合。
2.训练复杂度由O(n)直接上升到O(n2)
参考视频链接:【推荐算法】特征交叉 之 POLY2模型 —— 特征交叉的开始_哔哩哔哩_bilibili。
4、FM模型针对问题
1.在面对稀疏特征向量时,POLY2特征交叉项无法收敛。
2.POLY2计算复杂度过高。
5、改进思路
当k足够大时,对于任意对称正定的实矩阵W ∈Rnxn,均存在实矩阵V∈Rnxk,使得W=VV转置,即利用矩阵分解(MF)的思想,如下图所示。
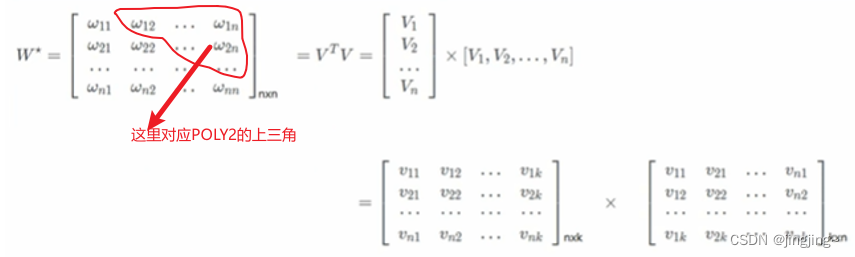
6、数学模型
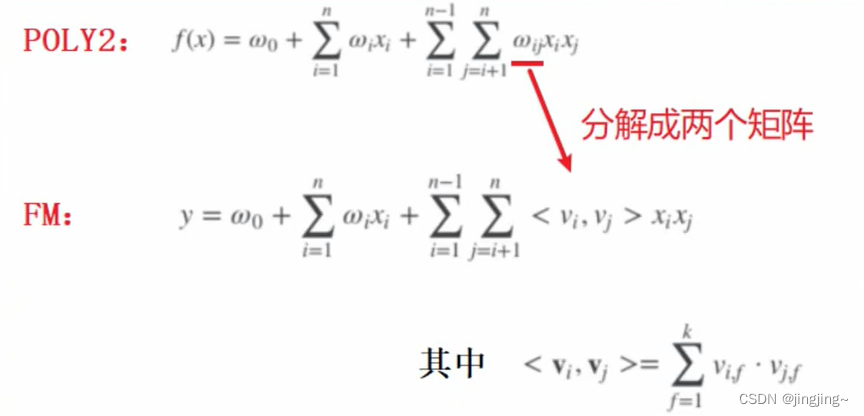

例子,如下图所示,下面的V相当于上面对应的隐向量。

6.1时间复杂度
从POLY2的o(n^2)变为o(kn)
7、损失函数
与POLY2是一样的都是二元交叉熵损失

8、梯度下降
8.1公式变形

详细推导过程参考:3.FM模型梯度下降_哔哩哔哩_bilibili
8.2求梯度
![]() 和
和![]() 与POLY2是相同的。
与POLY2是相同的。

详细推导过程参考:3.FM模型梯度下降_哔哩哔哩_bilibili
8.3参数更新
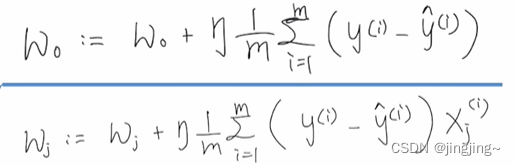

9、优点与缺点
9.1优点
1、极大降低了训练开销O(n2)——>o(kn)。
2、隐向量的引入,使得FM能更好解决数据稀疏性的问题。
3、FM模型是利用两个特征的Embedding做内积得到二阶特征交叉的权重,那么可以将训练好的FM特征取出离线存好,之后用来做其他扩展。
9.2缺点
1、对特征工程有依赖性
2、无法捕捉高阶特征交互
10、FFM模型针对问题
与FM对比,比如特征有性别(男、女),日期(一周七天)及商品的类别(运动配件 、化妆品),FM是将所有的都混合了在一起,对于性别和日期是两个完全不搭边的,因此,FFM针对这些问题进行改进,并引入特征域的概念。
11、改进方向
11.1什么是特征域
如下图所示,特征域就是将如性别、星期几总特征提取出来。

引入特征域感知(filed-aware)概念,使模型的表达能力更强。
11.2用俗话说
比如,见到同学说话是一种话术,见到老师说话是另一种话术,见到父母又是另一种话术了(总结:见人说人话,见鬼说鬼话)。
12、数学模型
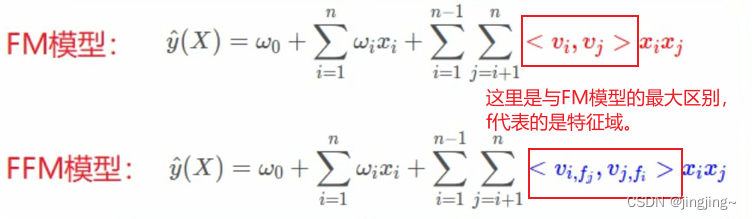
12.1示例

说明:

12.2与FM模型区别
FM:给每个特征域下的单项特征,赋予一个特征隐向量
FFM:给每个特征域下的单项特征,赋予一组特征隐向量
13、损失函数
13.1预测函数
这里的Z只是为了方便表示,将FFM的y-hat进行替换,再加上sigmoid激活函数。
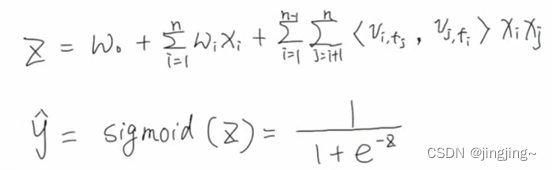
13.2交叉熵损失(与之前两个模型是一样的)
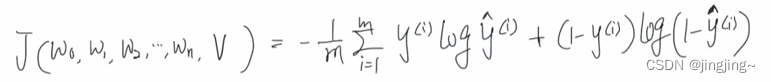
14、梯度下降
14.1参数
w0,wi, 
14.2求梯度
对w0和wi是和之前的一样。

![]()
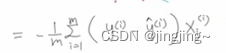
下面详细推导过程可参考3.FM模型梯度下降详解_哔哩哔哩_bilibili
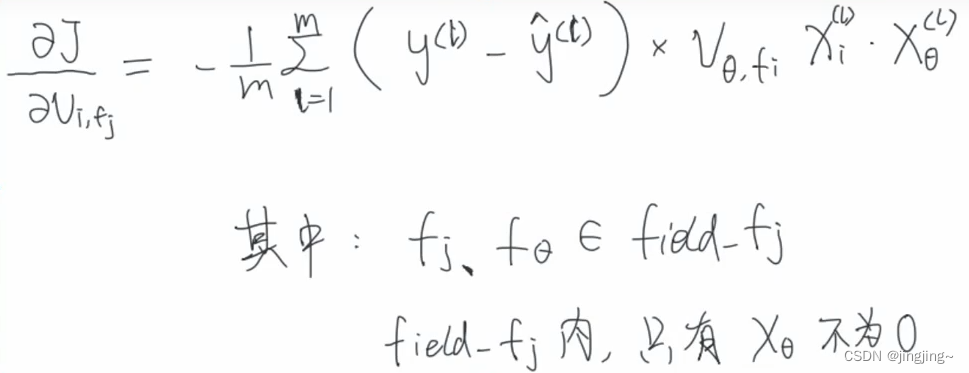
14.3梯度更新


15、FFM模型的优缺点
15.1优点
引入了更多的有价值的信息,使模型的表达能力更强。
15.2缺点
1、参数数量FM : kxn——>FFM :fxkxn。
2、时间复杂度FM : O(kn)——>FFM : O(kn^2)(在公式中多了层累加求和) 。
3、复杂度远大于FM模型,需要在模型效果和工程投入之间做权衡。
4、局限在二阶特征交叉(解决方法GBDT的”自动化“特征组合,使得模型具备了更高阶特征组合的能力)。
参考文献
【推荐算法】特征交叉 之 POLY2模型 —— 特征交叉的开始_哔哩哔哩_bilibili