Kmeans聚类方法原理:
1.首先随机定出K个聚类中心;
2.计算数据中每一个点到K个聚类中心的距离(欧氏距离),哪个最小就把这个点归到哪一个簇中;
3.计算每一个簇中所有点的中心点(向量对应元素取平均),这些点确定为新的聚类中心;
4.重复步骤2、3,直到所有的聚类中心不再发生变化。
知道这个原理后,我们应用此来做一个简单的小例子。
需要安装的第三方库:
numpy、matplotlib、scipy、sklearn(注意顺序不要错哦,后三个库是以numpy为基础,sklearn右是以前三个为基础的)
安装方式(pip安装):
对于不会翻墙的小伙伴,可以从镜像源网站下载,速度同样非常快,打开DOS窗口,以numpy为例,复制以下代码即可:
pip install numpy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
由于dos窗口里没法把光标移到中间删改东西,所以大家可以把这一行代码保存到一个word文档里,每次需要安装一个库时,就先把这行里面的名字改掉再复制到命令行窗口就可以啦。
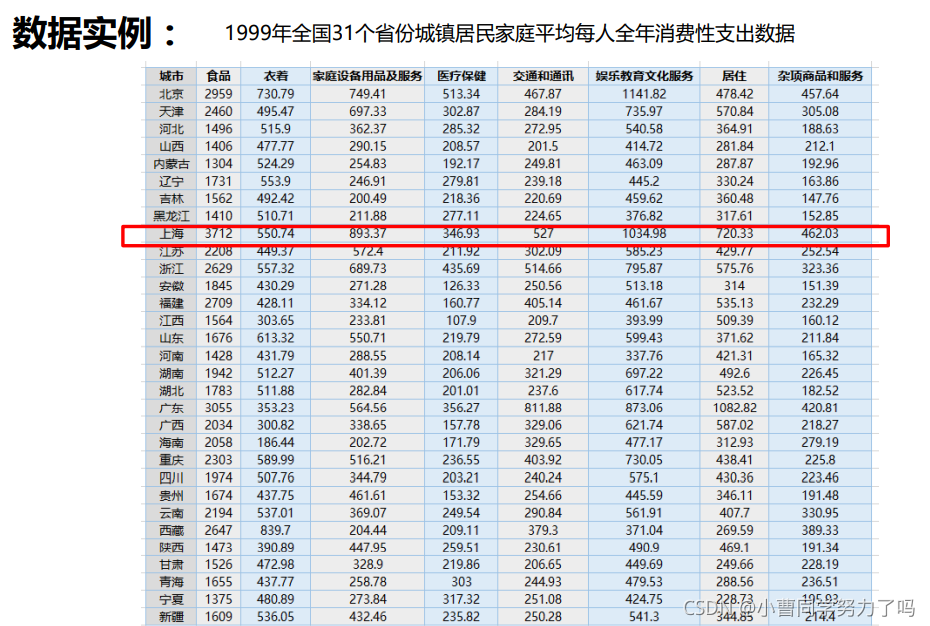
数据介绍:
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主
要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗
保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已
有数据,对31个省份进行聚类。
实验目的:
通过聚类,了解1999年各个省份的消费水平在国内的情况。
数据展示:
数据链接:
链接:https://pan.baidu.com/s/1PArczd8hxp1AbQe9MOKwgQ
提取码:9fg2
(将这个txt文档跟下面的程序放到一个文件夹里哦)
程序展示:
为了便于理解,在一些地方我添加了注释进行说明。
import numpy as np
from sklearn.cluster import KMeans
def loadData(filePath):
#该函数为从txt中读取数据
fr = open(filePath, 'r+')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")#strip()函数默认参数删除空白符(包括'\n', '\r', '\t', ' ')
#line本来是字符串,被.split(",")后,成了若干个字符串组成的列表了
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1, len(items))])#注意此处添加的是一个列表
return retData, retCityName
if __name__ == '__main__':
# 一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。
# 因此 if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,在 if __name__ == 'main': 下的代码只有在
# 第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的。
data, cityName = loadData('31省市居民家庭消费水平-city.txt')
km = KMeans(n_clusters=4)
label = km.fit_predict(data)#fit_predict():计算簇中心以及为簇分配序号,label:聚类后各数据所属的标签
expenses = np.sum(km.cluster_centers_, axis=1)
# 当axis为0时,是压缩行,即将每一列的元素相加,将矩阵压缩为一行,当axis为1时,是压缩列,即将每一行的元素相加,将矩阵压缩为一列
# 此处即是将聚类中心的各项数据求和
# print(expenses)
CityCluster = [[], [], [], []]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
#label中的每个元素都与cityname对应,也就是把每个城市名都添加到对应的簇中
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses[i])
print(CityCluster[i])
运行结果:

资料来源:
mooc北京理工大学python机器学习