作者:网舟科技(席汉斌)
在运营商 大数据挖掘的应用中,由于数据获取的渠道以及数据结构理解的差异等原因,经常会把一些数据记为“未知”,“空白”或使用一些特殊的标识来表示,这类数据通常被称为缺失数据(missing data)或者是不完备数据(incomplete data)。这些缺失数据通常会造成非常大的影响,比如缺失数据会在一定程度上影响抽取数据模式的正确性和导出规则的准确性,从而导致建立错误的数据挖掘模型,并且由于现阶段的大多数数据分析的算法都没有具备分析和处理缺失数据的能力,因而当数据集中含有缺失数据时这些已经被广泛使用的数据分析算法或者系统往往是无能为力的。目前,数据缺失的问题网舟科技团队在工作中已经取得了一些研究性成果,其中包括应用近似值替换方法、随机回归填补方法、神经网络、贝叶斯网络等理论来处理缺失数据的填补问题。
下面就几种常用的数据补齐方法进行对分析:删除样本法、0-1填补法、均值填补法、EM算法填补、回归填补、MI算法、K-最邻近法。
1缺失数据补齐技术
1.1 传统方法
1.1.1删除法
这方法的思想是将原来数据集中含有缺失数据的样本删除,从而得到一个包含完整数据的数据集。这种方法简易可行,在含有数据缺失的样本数量比较少的情况下数据补齐效果比较不错。但是,这种方法是以删除含有缺失数据的样本来得到完整数据集,经常会有浪费资源的情况发生。例如,在删除含有缺失数据样本的同时,也失去了隐含在这些样本中的大量有价值信息。并且当含有缺失数据的样本数量比较多时,这种方法对处理后得到的数据集的均值和方差分布方面都会产生较大的偏差。
1.1.2填充0、1、均值法
该方法是将原数据集中包含缺失数据的项全都简单地填充为0、1或者相应属性的样本均值,从而得到一个完整的数据集。





3实验及分析
3.1 实验数据
网舟科技出于数据保密的原则,实验数据是从公开数据库UCI机器学习资源库获取的4个含有缺失数据的分类数据集,他们分别是互联网广告数据集(internetadvertisements dataset)、肝炎数据集(hepatitis dataset)、乳腺肿块数据集(mammographic masses dataset)以及众议院投票数据集(house-votes-84 dataset)。以下分别简称这些数据集为ad,hepatitis,mammographic以及house vote。
这4个数据集均含有不同数量的缺失数据,表1列出了这4个数据集的包含样本总数、属性个数、含有缺失数据样本数以及数据缺失比例。
大数据挖掘
3.2数值实验及结果分析
针对以上4个数据集,分别应用填补0、填补1、填补均值、EM算法(EM)、回归填补法、MI算法(MI)、KNN算法(KNN)以及删除样本的方法对其缺失值进行处理,得到相应的完整数据集。其中KNN算法的k值取10。
采用支持向量机的分类结果作为检验补齐性能指标度量。SVM的核函数分别采用线性核和Gaussian核。数据集的Gaussian核的Sigma值分别为0.00001,0.0001,0.001,0.01,0.1,1,10,100,1000,10000。使用n-折交叉检验来检验不同缺失值填补方法的处理效果,其中n值均取10。
图1-4分别给出了支持向量机在Gaussian核下,不同Sigma值下各填补方法的效果。从图中可以选出在合适的Sigma值下,相比其他填补方法,删除样本法及回归法的填补效果比较好。从图1-4的实验结果中,我们可以选出针对不同数据的高斯核参数,即在4组数据下的相对最优Sigma参数分别为100、100、10、10。
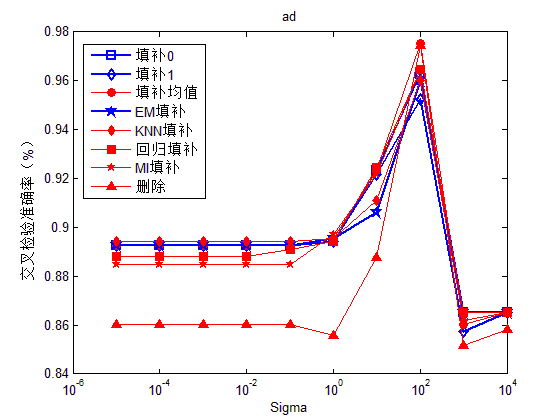
图1. Ad数据在不同sigma参数下的分类准确率
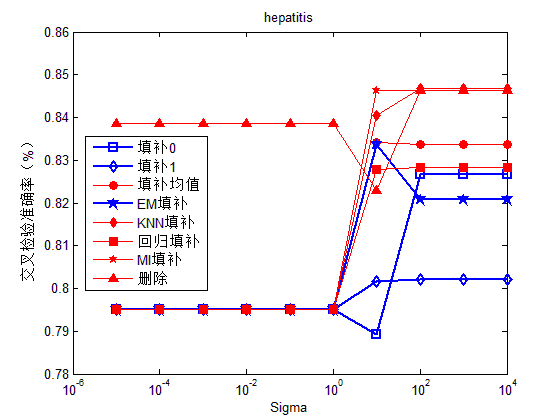
图2. Hepatitis数据在不同sigma参数下的分类准确率
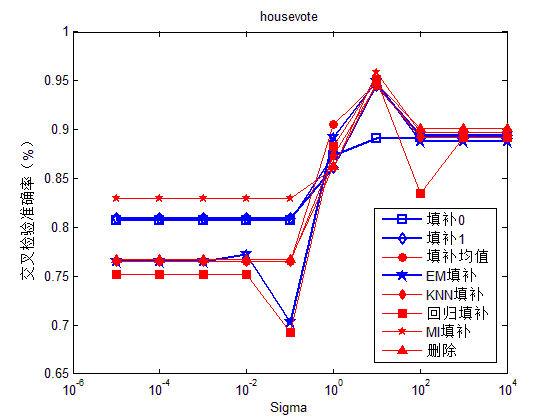
图3. Housevotes数据在不同sigma参数下的分类准确率
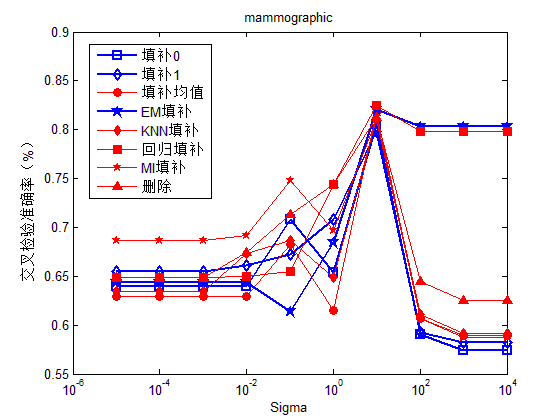
图4. Mammographic数据在不同sigma参数下的分类准确率
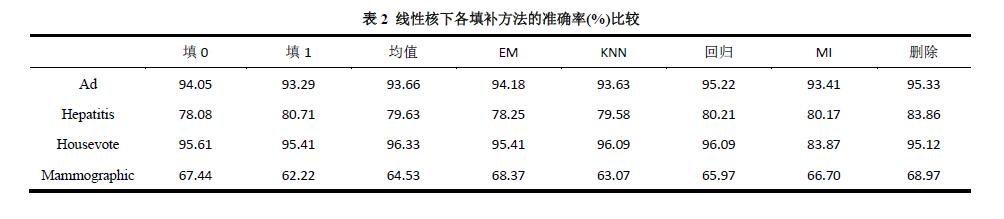
表2给出了支持向量机在线性核下(选用线性核的原因是该核无参数),对4个数据集使用不同填补方法的效果,从表2中可以看出删除样本准确率相对较高。
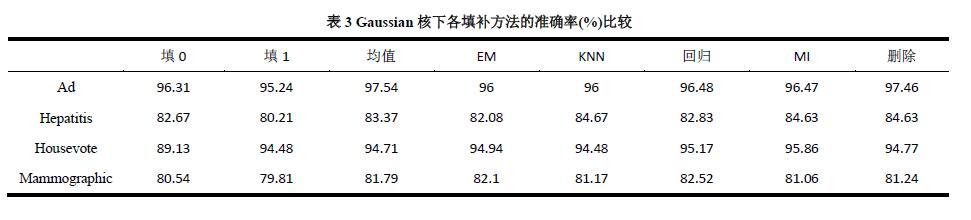
表3给出了支持向量机在Gaussian核下,对4个数据集使用不同填补方法的效果。
表2给出了支持向量机在线性核下(选用线性核的原因是该核无参数),对4个数据集使用不同填补方法的效果,从表2中可以看出删除样本准确率相对较高。
表3给出了支持向量机在Gaussian核下,对4个数据集使用不同填补方法的效果。
4结 论
在运营商 大数据挖掘的应用中,由于数据获取的渠道以及数据结构理解的差异等原因,经常会把一些数据记为“未知”,“空白”或使用一些特殊的标识来表示,这类数据通常被称为缺失数据(missing data)或者是不完备数据(incomplete data)。这些缺失数据通常会造成非常大的影响,比如缺失数据会在一定程度上影响抽取数据模式的正确性和导出规则的准确性,从而导致建立错误的数据挖掘模型,并且由于现阶段的大多数数据分析的算法都没有具备分析和处理缺失数据的能力,因而当数据集中含有缺失数据时这些已经被广泛使用的数据分析算法或者系统往往是无能为力的。目前,数据缺失的问题网舟科技团队在工作中已经取得了一些研究性成果,其中包括应用近似值替换方法、随机回归填补方法、神经网络、贝叶斯网络等理论来处理缺失数据的填补问题。
下面就几种常用的数据补齐方法进行对分析:删除样本法、0-1填补法、均值填补法、EM算法填补、回归填补、MI算法、K-最邻近法。
1缺失数据补齐技术
1.1 传统方法
1.1.1删除法
这方法的思想是将原来数据集中含有缺失数据的样本删除,从而得到一个包含完整数据的数据集。这种方法简易可行,在含有数据缺失的样本数量比较少的情况下数据补齐效果比较不错。但是,这种方法是以删除含有缺失数据的样本来得到完整数据集,经常会有浪费资源的情况发生。例如,在删除含有缺失数据样本的同时,也失去了隐含在这些样本中的大量有价值信息。并且当含有缺失数据的样本数量比较多时,这种方法对处理后得到的数据集的均值和方差分布方面都会产生较大的偏差。
1.1.2填充0、1、均值法
该方法是将原数据集中包含缺失数据的项全都简单地填充为0、1或者相应属性的样本均值,从而得到一个完整的数据集。
3实验及分析
3.1 实验数据
网舟科技出于数据保密的原则,实验数据是从公开数据库UCI机器学习资源库获取的4个含有缺失数据的分类数据集,他们分别是互联网广告数据集(internetadvertisements dataset)、肝炎数据集(hepatitis dataset)、乳腺肿块数据集(mammographic masses dataset)以及众议院投票数据集(house-votes-84 dataset)。以下分别简称这些数据集为ad,hepatitis,mammographic以及house vote。
这4个数据集均含有不同数量的缺失数据,表1列出了这4个数据集的包含样本总数、属性个数、含有缺失数据样本数以及数据缺失比例。
大数据挖掘
3.2数值实验及结果分析
针对以上4个数据集,分别应用填补0、填补1、填补均值、EM算法(EM)、回归填补法、MI算法(MI)、KNN算法(KNN)以及删除样本的方法对其缺失值进行处理,得到相应的完整数据集。其中KNN算法的k值取10。
采用支持向量机的分类结果作为检验补齐性能指标度量。SVM的核函数分别采用线性核和Gaussian核。数据集的Gaussian核的Sigma值分别为0.00001,0.0001,0.001,0.01,0.1,1,10,100,1000,10000。使用n-折交叉检验来检验不同缺失值填补方法的处理效果,其中n值均取10。
图1-4分别给出了支持向量机在Gaussian核下,不同Sigma值下各填补方法的效果。从图中可以选出在合适的Sigma值下,相比其他填补方法,删除样本法及回归法的填补效果比较好。从图1-4的实验结果中,我们可以选出针对不同数据的高斯核参数,即在4组数据下的相对最优Sigma参数分别为100、100、10、10。
图1. Ad数据在不同sigma参数下的分类准确率
图2. Hepatitis数据在不同sigma参数下的分类准确率
图3. Housevotes数据在不同sigma参数下的分类准确率
图4. Mammographic数据在不同sigma参数下的分类准确率
表2给出了支持向量机在线性核下(选用线性核的原因是该核无参数),对4个数据集使用不同填补方法的效果,从表2中可以看出删除样本准确率相对较高。
表3给出了支持向量机在Gaussian核下,对4个数据集使用不同填补方法的效果。
表2给出了支持向量机在线性核下(选用线性核的原因是该核无参数),对4个数据集使用不同填补方法的效果,从表2中可以看出删除样本准确率相对较高。
表3给出了支持向量机在Gaussian核下,对4个数据集使用不同填补方法的效果。
4结 论
针对4个分类数据集中的数据缺失问题展开对比分析,分别应用填补0、填补1、填补均值、EM算法、回归填补法、MI算法、KNN算法以及删除样本的方法对其缺失值进行处理。使用支持向量机对数据集进行分类验证不同的缺失数据补齐方法的效果。从数值实验结果可以看出,回归补齐法及删除样本法的效果相对较好,补齐后的数据的分类准确率更高。在实际的运营商应用中,其数据样本大,或者样本中缺失属性比较多的情况,删除样本法就不够实用了,因此回归法补齐缺失数据是各类补齐数据方法中相对较好的一种。
PS:网舟科技(www.eship.com.cn)长期专注于金融保险、通信、互联网、旅游酒店等行业的电子渠道大数据运营,为客户提供全球领先的电子渠道转型咨询、大数据挖掘和应用定制服务,助力客户互联网转型,提升数字化运营和数据营销能力。